Gdzie rejestruje się najwięcej nowych samochodów?
Jak to porównywać i pokazywać?
Dzisiaj proste zadanie, ale wymagające nieco gimnastyki. Otóż sprawdzimy gdzie przybywa najwięcej nowych samochodów. Skorzystamy z danych GUSu (precyzyjniej jest to Kategoria: TRANSPORT I ŁĄCZNOŚĆ, Grupa: POJAZDY, Podgrupa: Zarejestrowane nowe pojazdy samochodowe (dane kwartalne)).
Pobieramy ręcznie plik CSV (dane dla wszystkich okresów i wszystkich lat, tylko samochody osobowe), pamiętając żeby przed pobraniem pliku przełączyć układ danych na “według TERYT” (klucz TERYT jest najlepszy do łączenia danych z mapami – pobranymi w plikach SHP z CODGiK – zdaje się, że było już o tym).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
library(tidyverse) library(lubridate) pojazdy_nowe <- read_csv2("dane/pojazdy_nowe.csv") pojazdy_nowe <- pojazdy_nowe[,c(1,2,3,5,6)] pojazdy_nowe <- na.omit(pojazdy_nowe) # kod TERYT województwa jest dwucyfrowy pojazdy_nowe$Kod <- substr(pojazdy_nowe$Kod, 1, 2) # zamiana kwartałów na daty ich końca pojazdy_nowe$Data <- as.Date(ifelse(pojazdy_nowe$Okresy == "I kwartał", make_date(pojazdy_nowe$Rok, 3, 31), ifelse(pojazdy_nowe$Okresy == "II kwartał", make_date(pojazdy_nowe$Rok, 6, 30), ifelse(pojazdy_nowe$Okresy == "III kwartał", make_date(pojazdy_nowe$Rok, 9, 30), make_date(pojazdy_nowe$Rok, 12, 31)))), origin = "1970-01-01") # Potrzebujemy tylko województwa, bez całego kraju pojazdy_nowe <- filter(pojazdy_nowe, Kod != "00") |
Po delikatnej transformacji danych i wybraniu tylko tego co nas interesuje możemy zobaczyć jak zmieniała się w czasie ilość nowych samochodów osobowych w poszczególnych województwach:
|
1 2 3 4 5 |
theme_set(theme_minimal()) ggplot(pojazdy_nowe) + geom_line(aes(Data, Wartosc)) + facet_wrap(~Nazwa, scales = "free_y") |
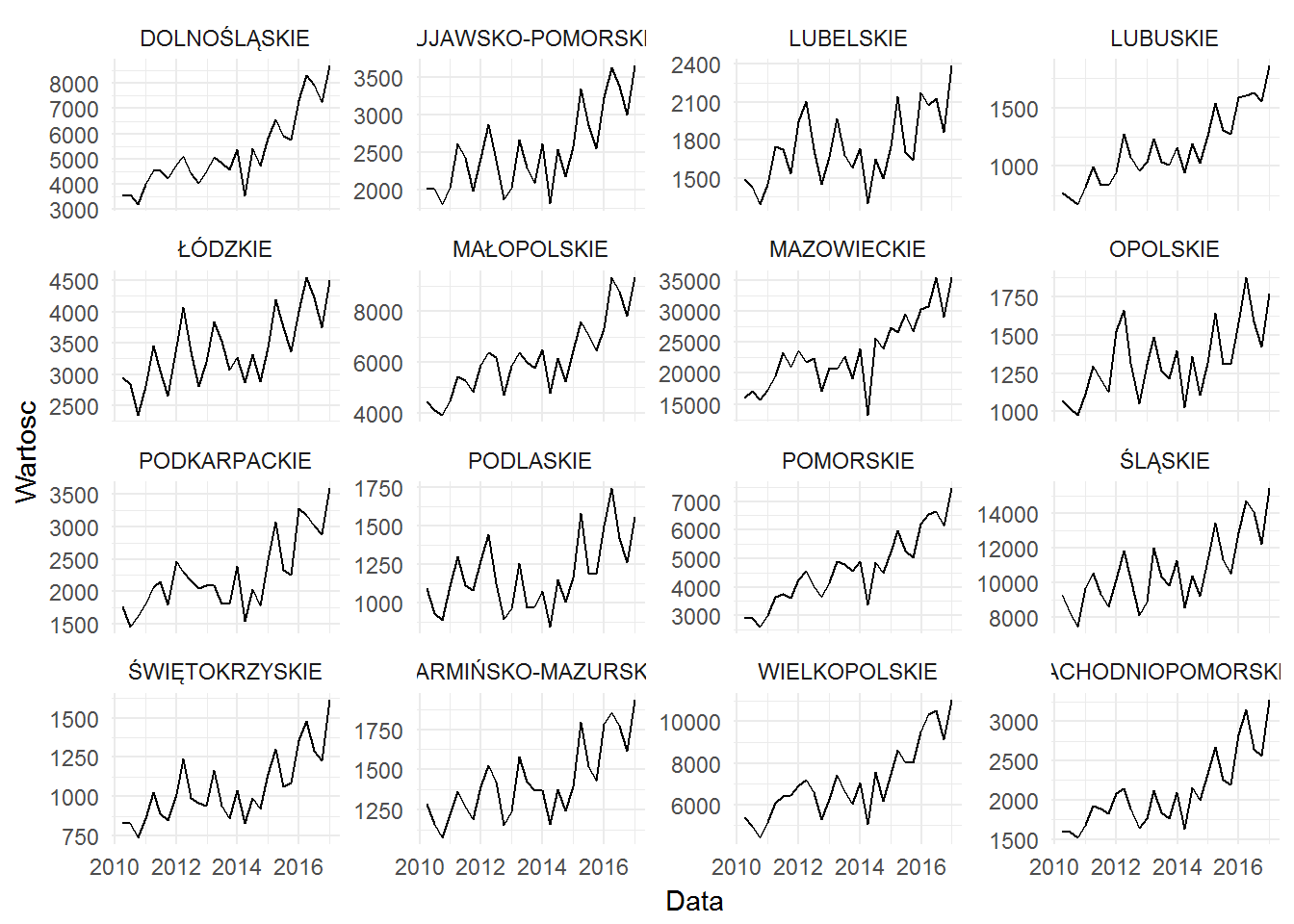
Wszędzie właściwie rośnie, wszędzie sezonowo. Korzystając z lekcji z ostatniego postu możemy przygotować szereg czasowy dla sumy nowych samochodów w całym kraju i go zdekomponować na potrzeby szybkiej obserwacji:
|
1 2 3 4 5 6 7 8 9 |
pojazdy_nowe %>% group_by(Data) %>% summarise(Wartosc = sum(Wartosc)) %>% ungroup() %>% arrange(Data) %>% select(Wartosc) %>% ts(start=c(2010,1), freq=4) %>% decompose() %>% plot() |
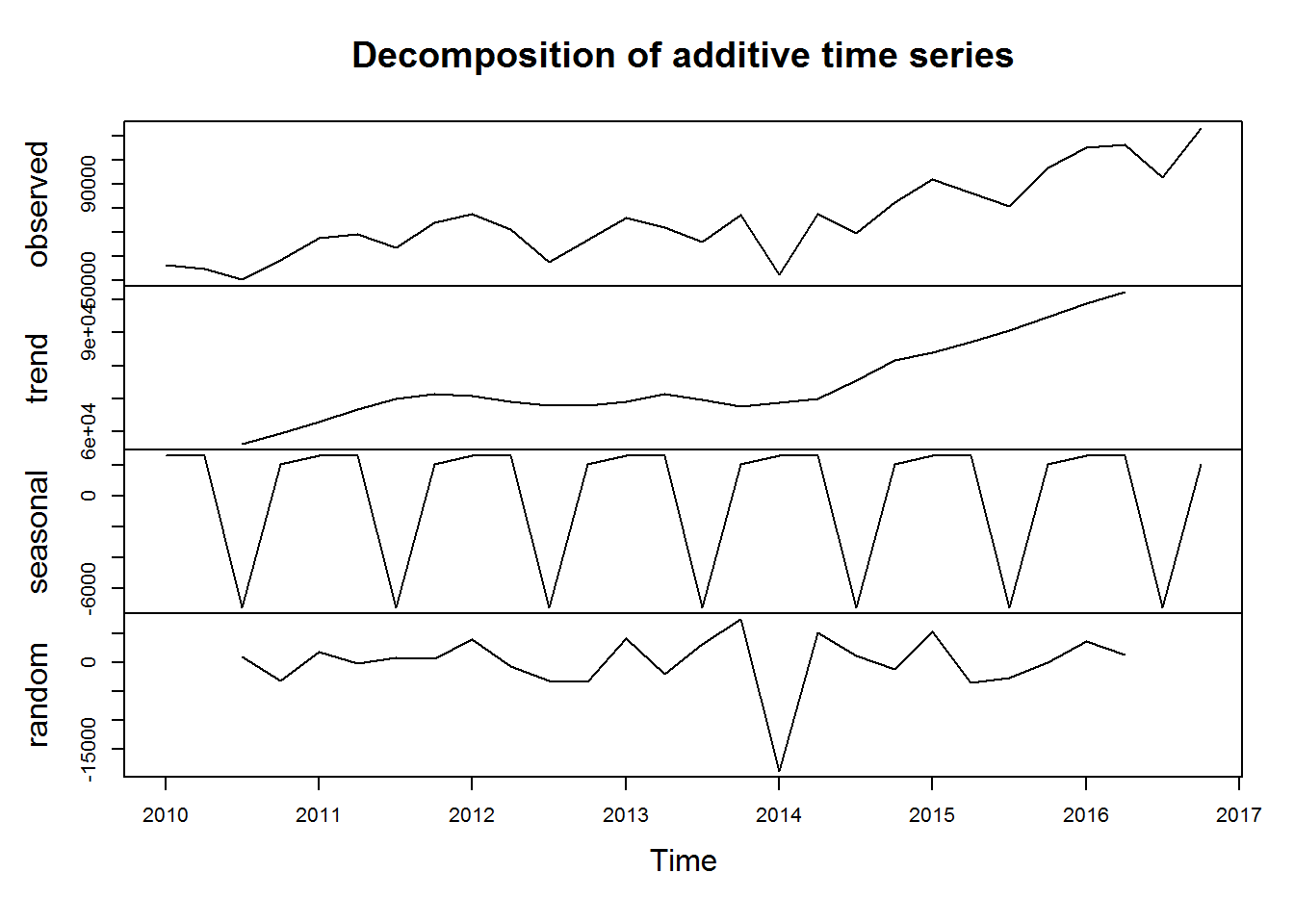
Trend jest wyraźnie wznoszący, sezonowość też widoczna (spadki w trzecim kwartale), coś odbiegającego od normy wydarzyło się w I kwartale 2014 roku. Z takim szeregiem można już zrobić jakąś prostą prognozę. Ale dzisiaj nie o tym.
Dzisiaj bardziej o podejściu analitycznym, niż o samych wynikach.
Porównywanie ilości nowych samochodów pomiędzy województwami w wartościach bezwzględnych jest niepoprawne. Przecież w jednym województwie mieszka więcej ludzi niż w drugim (dla przykładu – mazowieckie jest ponad 5 raz bardziej zaludnione niż opolskie; w całym opolskim mieszka “tylko” pół Warszawy).
Dlatego potrzebujemy porównać dane względne. Na przykład ile jest nowych samochodów na tysiąc mieszkańców?. Do tego porównania potrzebujemy informacji o ilości mieszkańców w poszczególnych województwach, a żeby być jeszcze bardziej precyzyjnym – w tych samych kwartałach, dla których mamy dane o pojazdach.
Zatem znowu sięgamy do GUS – tym razem pobierając dane z kategorii LUDNOŚĆ, Grupa: STAN LUDNOŚCI, Podgrupa: Ludność wg płci (dane kwartalne). Znowu w podziale według kodów TERYT.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
ludnosc <- read_csv2("dane/ludnosc.csv") ludnosc <- ludnosc[,c(1,2,3,5,6)] ludnosc <- na.omit(ludnosc) ludnosc$Kod <- substr(ludnosc$Kod, 1, 2) ludnosc <- filter(ludnosc, Kod != "00") ludnosc$Data <- as.Date(ifelse(ludnosc$Okresy == "I kwartał", make_date(ludnosc$Rok, 3, 31), ifelse(ludnosc$Okresy == "II kwartał", make_date(ludnosc$Rok, 6, 30), ifelse(ludnosc$Okresy == "III kwartał", make_date(ludnosc$Rok, 9, 30), make_date(ludnosc$Rok, 12, 31)))), origin = "1970-01-01") |
Do dokonaniu tego samego rodzaju przekształceń co dla pojazdów otrzymujemy:
|
1 2 3 |
ggplot(ludnosc) + geom_line(aes(Data, Wartosc)) + facet_wrap(~Nazwa, scales = "free_y") |
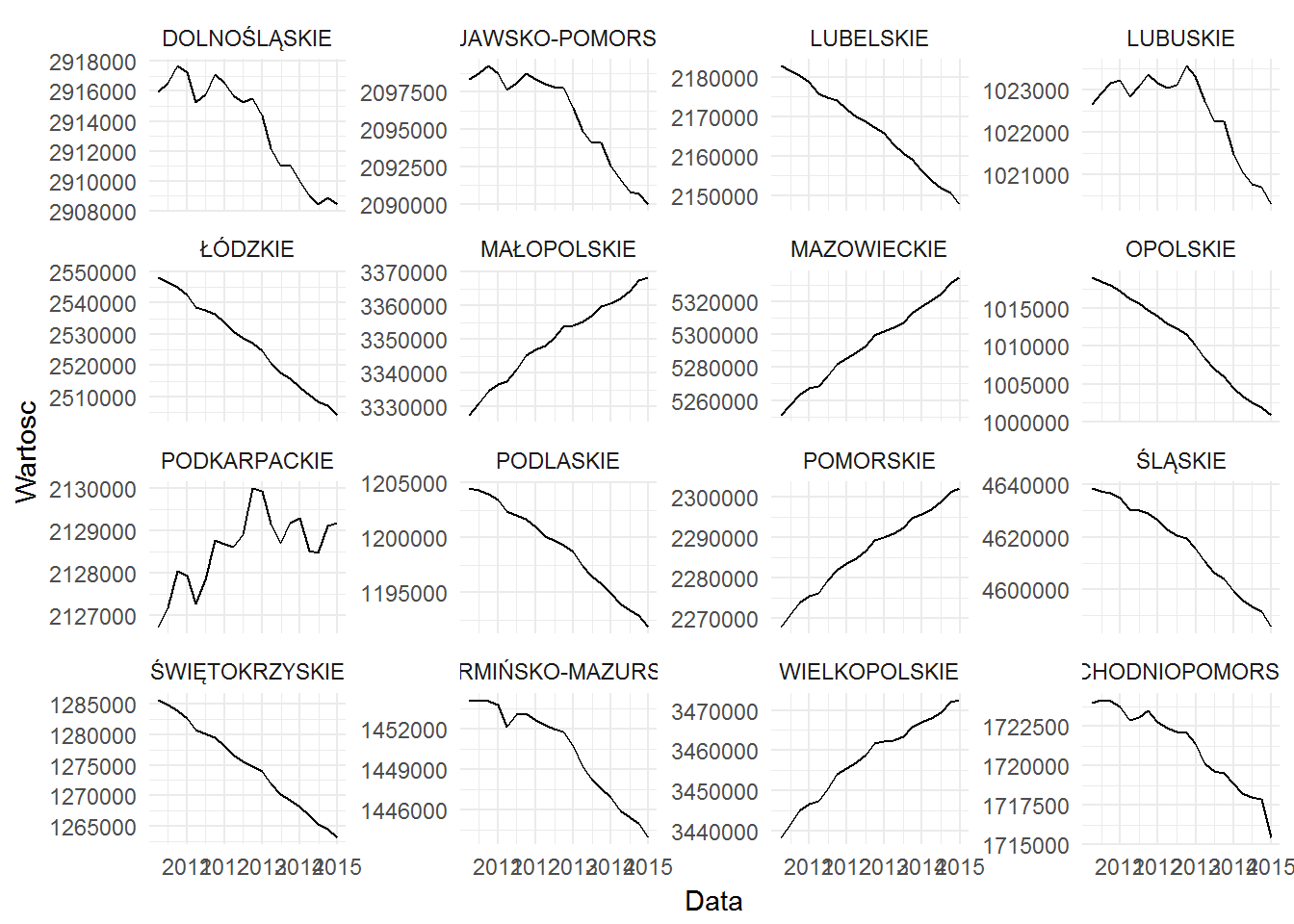
Tutaj widzimy ciekawostki! Część województw się wyludnia (przykładowe opolskie straciło na przestrzeni 5 lat 15 tysięcy mieszkańców – jakieś 1.5%), a jak pamiętamy z wykresu o rejestracji nowych pojazdów – wszędzie właściwie pojazdów przybywa. Zatem podejście zestawienia ze sobą dwóch wartości w tym samym czasie wydaje się być zasadne. W pomorskim pod koniec 2015 roku rejestrowano ponad dwukrotnie więcej samochodów kwartalnie, a ludzi było 30 tysięcy więcej (znowu – 1.5%). Różnice są nieporównywalne.
Połączmy więc dwie tabele danych, a po połączeniu – policzymy ile nowy samochodów zostało zarejestrowanych na 1000 mieszkańców.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# złączenie danych poj_lud <- left_join(pojazdy_nowe, ludnosc, by=c("Kod"="Kod", "Data"="Data")) # mały porządek poj_lud <- poj_lud[,c(1,2,5,10, 6)] colnames(poj_lud) <- c("Kod", "Nazwa", "Pojazdy_nowe", "Ludnosc", "Data") poj_lud <- na.omit(poj_lud) # ile aut na 1k mieszkańców? poj_lud$Pojazdy_ludnosc <- 1000 * poj_lud$Pojazdy_nowe / poj_lud$Ludnosc # wykres ggplot(poj_lud) + geom_point(aes(Data, Pojazdy_ludnosc)) + geom_smooth(aes(Data, Pojazdy_ludnosc), se=FALSE) + facet_wrap(~Nazwa, scales="free_y") |
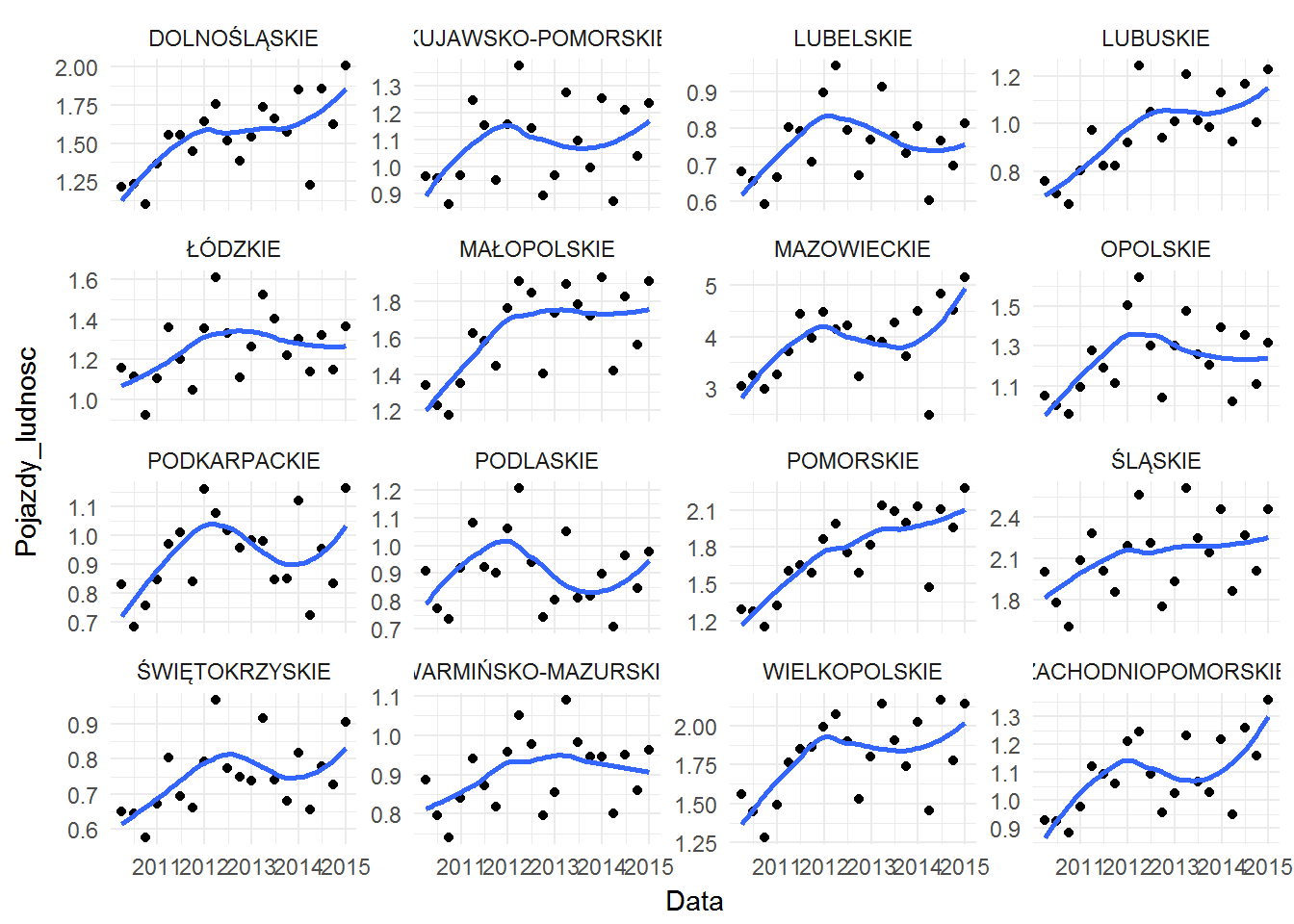
Uwaga na oś Y na wykresach powyżej – każdy ma swoją. Taka wizualizacja pokazuje dobrze dynamikę zmian, ale jest nieprzydatna do porównania zmian między województwami.
Mamy to, czego można było się spodziewać – we wspomnianym pomorskim wskaźnik zmienił się prawie dwukrotnie (urósł o prawie 100%): z 1.2 nowego samochodu na 1000 mieszkańców do dwóch z całkiem sporym kawałkiem. W innych województwach wygląda to podobnie:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
left_join(filter(poj_lud, Data==min(Data)), filter(poj_lud, Data==max(Data)), by="Kod") %>% select(Nazwa = Nazwa.x, Pojazdy_ludnosc.x, Pojazdy_ludnosc.y) %>% mutate(Zmiana = 100*(Pojazdy_ludnosc.y - Pojazdy_ludnosc.x) / Pojazdy_ludnosc.x) %>% select(Nazwa, Zmiana) %>% mutate(Nazwa=factor(Nazwa, levels = rev(Nazwa))) %>% ggplot() + geom_bar(aes(Nazwa, Zmiana), fill="lightgreen", color="darkgreen", stat="identity") + coord_flip() + labs(x="", y="Procentowa zmiana liczby nowych samochodów\nna 1000 mieszkańców, 1q2010 - 4q2014") |
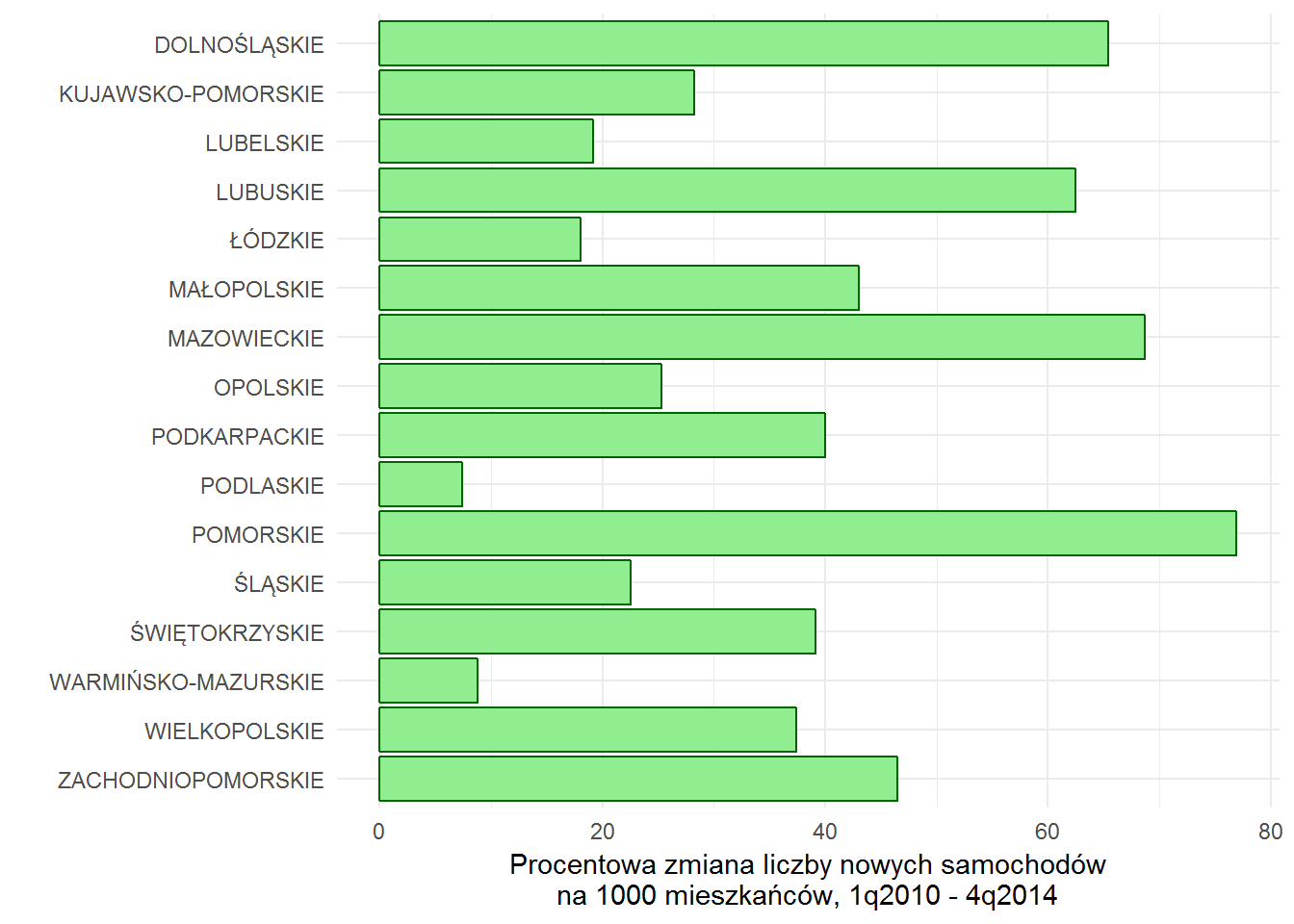
Można więc postawić tezę, że społeczeństwo w ciągu pięciu lat (2010-2015) się wzbogaciło i zainwestowało w nowe auta. Albo też przyjechało więcej złomu z zagranicy lub więcej zarejestrowano aut leasingowych.
Jak było dokładnie – trzeba by sięgnąć głębiej w dane. Zależy który serwis informacyjny taką informację ma pokazać, tak trzeba dobrać tezę. W końcu te osiem lat to były najgorsze lata dla Polski, więc jak mogło się Polakom polepszyć?
Mamy już wykresy ze zmianą liczby nowych rejestracji w poszczególnych województwach, ale w telewizorze lepiej wyglądają mapy. Przygotujmy je więc:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# mapa województw library(rgdal) wojewodztwa <- readOGR("../!mapy_shp/wojewodztwa.shp") library(broom) wojewodztwa_df <- tidy(wojewodztwa, region="jpt_kod_je") # poprzez mniejszą dokładność współrzędnych zmniejszamy ilość danych do narysowania wojewodztwa_df2 <- wojewodztwa_df %>% select(-order) %>% mutate(long=round(long/10000, 1), lat=round(lat/10000, 1)) %>% unique() %>% mutate(order=row_number()) # łączymy mapę z danymi po kodzie województwa mapki <- left_join(wojewodztwa_df2, poj_lud %>% mutate(Rok=year(Data), Kwartal=quarter(Data)) %>% select(Kod, Rok, Kwartal, Pojazdy_ludnosc), by=c("id"="Kod")) |
Po przekształceniu pliku z mapą na ramkę danych i połączeniu ich z danymi o nowych pojazdach rysujemy mapę – rok po roku, kwartał po kwartale:
|
1 2 3 4 5 6 7 8 9 10 |
ggplot(mapki) + geom_polygon(aes(long, lat, group=group, fill=cut(Pojazdy_ludnosc, breaks = c(0,1,2,3,4,5,6))), color="gray") + scale_fill_brewer(palette = "YlOrRd") + facet_grid(Rok~Kwartal) + coord_equal(0.9) + theme_void() + labs(fill="Liczba nowych pojazdów na 1000 mieszkańców") + theme(legend.position = "bottom", legend.direction = "horizontal") |
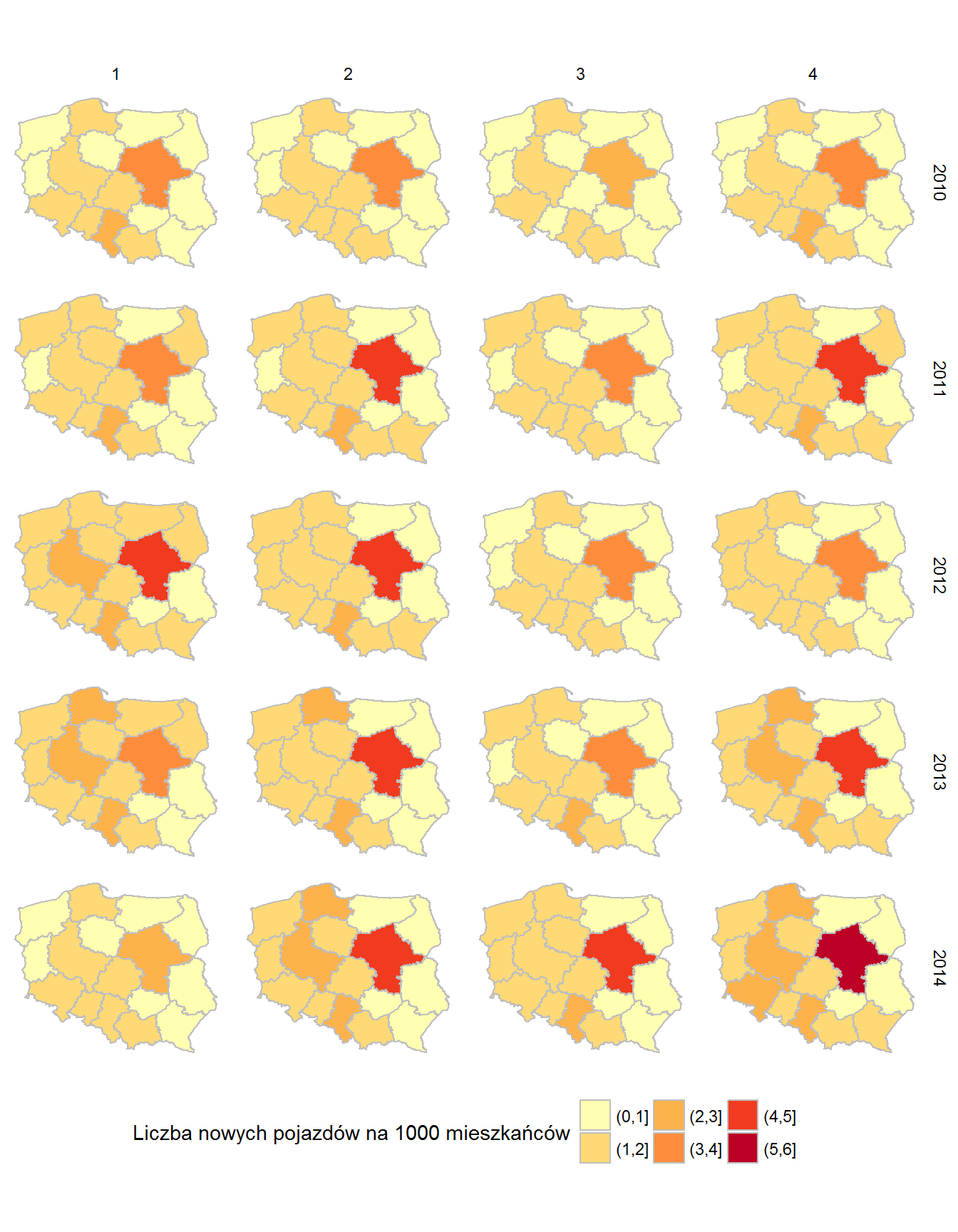
Mazowieckie dominuje – tutaj rejestruje się zawsze najwięcej samochodów. Tak zwana ściana wschodnia wydaje się pozostawać na tym samym poziomie, zaś na zachód od Wisły wzrost jest wyraźny.
Pingback: Mapy po raz kolejny - pakiet rgeos | Łukasz Prokulski