Dzisiaj zajmiemy się ruchem tramwajów w Warszawie.
Jak zmienia się ruch w ciągu dnia? Jakie i ile tramwajów jeździ po warszawskich torach?
Inspiracją do tego wpisu jest filmik obrazujący podobne dane z Nowego Jorku.
Ekstra, co nie? Zrobimy to samo. Bo możemy, bo chcemy, bo potrafimy.
Źródło i pobranie danych
Skorzystamy z otwartych danych, jakie dostępne są na stronie Otwarte dane po warszawsku. Na początek potrzebna będzie rejestracja na tej stronie i uzyskanie klucza API, który pozwoli na dostęp do różnych ciekawych danych jakie udostępnia Miasto Stołeczne Warszawa. Po uzyskaniu klucza API koniecznie będzie wpisanie jego wartości w miejsce NUMER_APIKEY w poniższym kodzie.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
library(jsonlite) # tutaj wstaw swój API Key apikkey <- "&apikey=NUMER_APIKEY" api_url <- "https://api.um.warszawa.pl/api/action/wsstore_get?id=c7238cfe-8b1f-4c38-bb4a-de386db7e776" tramwaje <- data.frame() i <- 1 # nieskończona pętla pobierająca i zapisująca lokalnie dane while(TRUE) { dane <- fromJSON(paste0(api_url, apikkey)) dane_df <- dane$result dane_df$frame <- i # sprawdzamy czy coś pobraliśmy i jeśli tak - dodajemy do wcześniejszych danych if(!is.null(nrow(dane$result))) { tramwaje <- rbind(tramwaje, dane_df) i <- i + 1 saveRDS(tramwaje, file="tramwaje.RDS") } # czekamy minutę Sys.sleep(60) } |
Ten krótki kod sięgnie do API i pobierze plik JSON (dokładny opis struktury znajdziecie w dokumencie pdf na stronie z danymi), dane przetransformuje w ramkę i doda do niej kolejny numer frame. Numer ten pozwoli nam później na wygenerowanie kolejnych “klatek” animacji. Później czekamy minutę i operację powtarzamy, a nowe dane doklejamy do wcześniej pobranych.
Pętla jest nieskończona – po zebraniu interesującej nas liczby danych (np. doba) trzeba go przerwać. Aby nie utracić pobranych danych – po każdym pobraniu nowej partii zapisujemy całość lokalnie do pliku tramwaje.RDS. Ten proces jest najdłuższy – ponieważ nie mamy gotowych danych, musimy je pobrać. A że potrzebujemy całej doby to trwa to całą dobę… Żebyście nie musieli tyle czekać – dane z całej doby znajdziecie tutaj.
Czytając dokumentację widzimy, że znajdziemy położenie (długość i szerokość) geograficzne danego tramwaju, numer linii jaką obsługuje i numer składu (brygady) dla którego podane jest położenie oraz określenie czy zadanie realizuje tramwaj niskopodłogowy. Skorzystamy z tych danych i wybierzemy jedną brygadę (ja wybrałem trójkę) aby w animacji zaznaczyć poruszający się tramwaj oraz – zobaczymy jaki udział mają składy niskopodłogowe.
Edycja danych (czyszczenie)
Już po 15-30 minutach mamy trochę danych i jeśli jesteście niecierpliwi możecie się im przyjrzeć od razu. Warto jednak trochę poczekać. Tak czy inaczej trzeba dane wyczyścić z wartości błędnych (zdarzają się takie).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
library(dplyr) library(ggplot2) library(lubridate) library(gridExtra) tramwaje <- tramwaje %>% # granice Warszawy - doświadczalnie wybrane :) filter(Lon >= 20.8, Lat >= 52.1) %>% filter(Lon <= 21.2, Lat <= 52.5) %>% # format daty na bardziej przyjazny + godzina i minuty osobno mutate(Time = ymd_hms(Time)) %>% mutate(Date = date(Time), Hour = hour(Time), Minute = minute(Time)) %>% filter(Hour!=0, Minute!=0) tramwaje$Brigade <- trimws(tramwaje$Brigade) tramwaje$FirstLine <- as.numeric(tramwaje$FirstLine) theme_set(theme_minimal()) |
Przegląd i pierwsze analizy
Z oczyszczonych danych możemy narysować z położeniem wszystkich pobranych składów. Im więcej danych tym bardziej dokładna mapka. Ja mam dane z całej doby (wirtualny komputer popracował trochę), więc widać wszystko bardzo ładnie:
|
1 |
ggplot(tramwaje) + geom_point(aes(Lon, Lat)) + coord_map() |
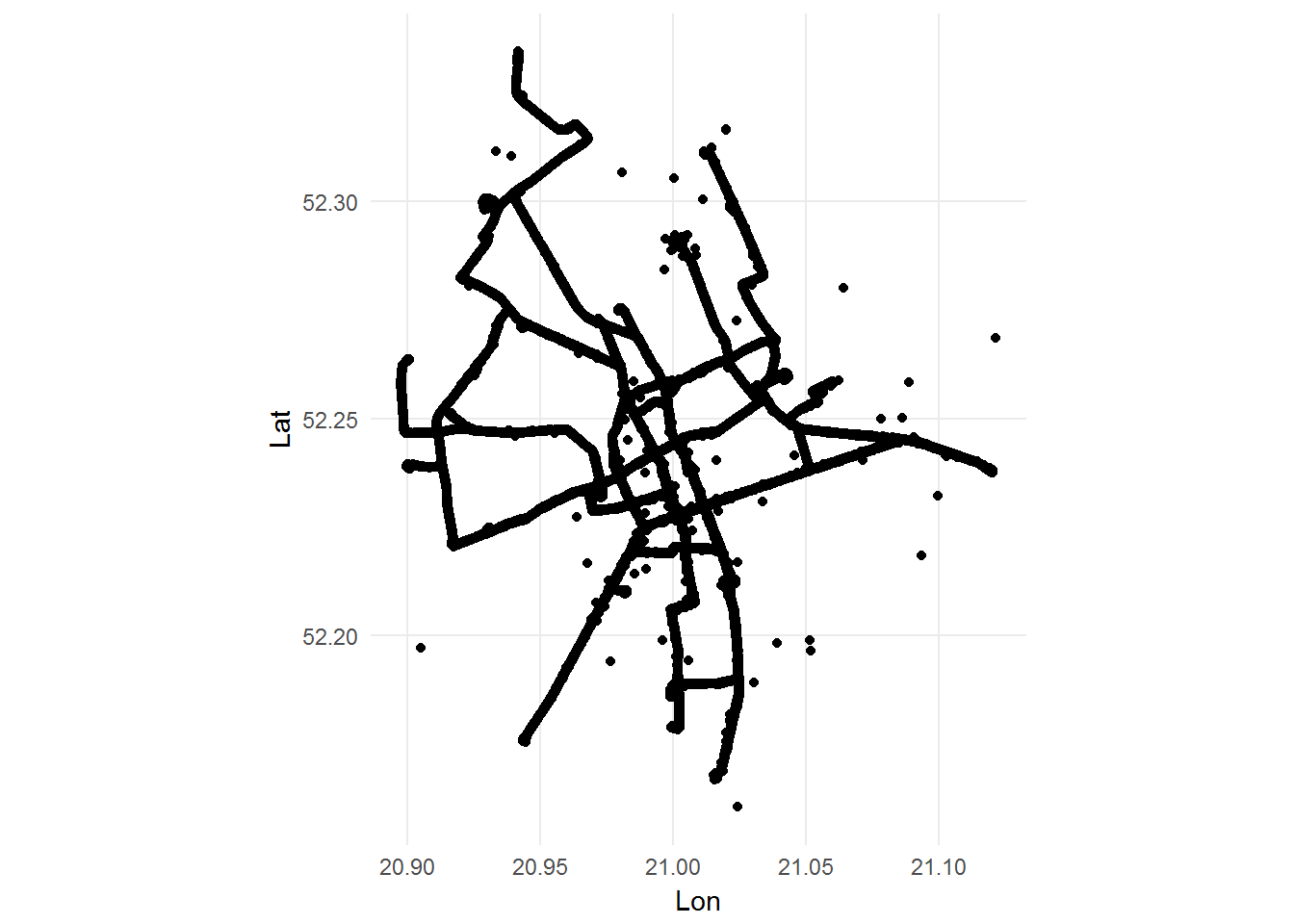
Moje dziecko młodsze powiedziało “czarny pająk!” :D
Widać jeszcze pojedyncze śmieci, ale nie warto się nimi przejmować. Dla mieszkańców Warszawy rozpoznawalne są poszczególne końcówki tras (na przykład Gocławek w prawym dolnym rogu; Nowodwory najbardziej na północnym wschodzie; na południu z jednej strony Okęcie, a bliżej Wisły – Służewiec i Wyścigi). Ale żeby było łatwiej – nałóżmy tą siatkę na mapę.
|
1 2 3 4 5 |
# mapa do tła library(ggmap) map_waw <- get_map("Warszawa, Polska", zoom=11) ggmap(map_waw) + geom_point(data=tramwaje, aes(Lon, Lat)) |
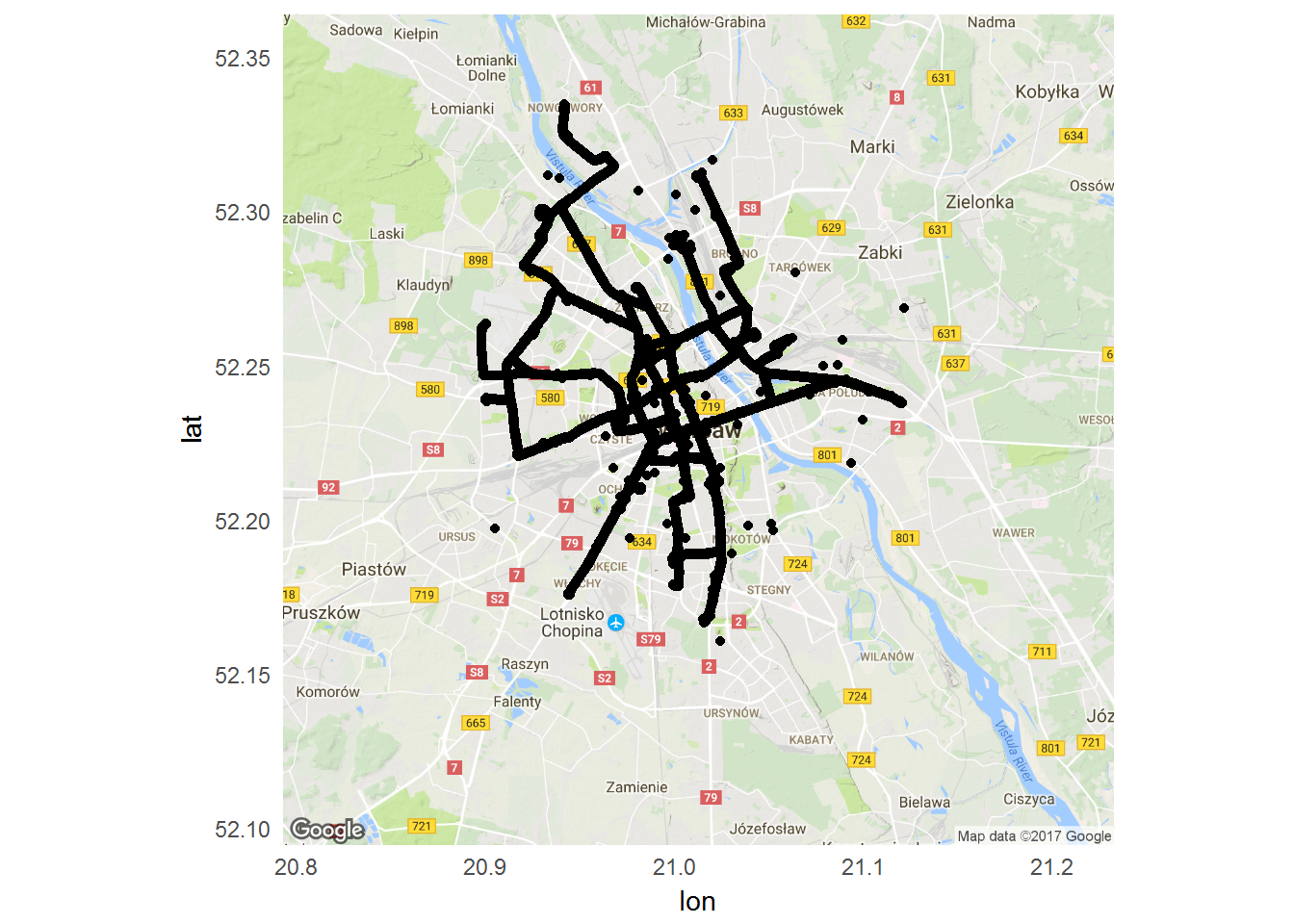
Przy tej okazji można zauważyć ciekawostki – kiedy każdą z linii narysujemy na oddzielnej mapce (to co wyżej uzupełnione o +facet_wrap(~FirstLine)) otrzymamy trasy, którymi dana linia przemieszczała się przez całą dobę. Ktoś myślał, że tramwaje jeżdżą zawsze tą samą trasą? Otóż nie! Sprawdźcie sami. Należy z danych wybrać określoną linię (filter() z odpowiednim FirstLine) i na przykład na siatce narysować jej trasę przy rozdzieleniu na godziny i składy (facet_grid() z Hour i Brigade). Dlaczego tak jest? Nie mam pojęcia – pewnie ZTM Warszawa ma w tym jakiś zamysł. Może być też tak, że są to “przejazdy techniczne” lub inne “zjazdy do zajezdni”.
Zobaczmy jak wyglądała liczba tramwajów w ruchu dla poszczególnych pobranych danych (“ramek” animacji) – czyli w czasie, chociaż nie będziemy pokazywać tutaj godzin a numer pomiaru. Przy okazji podzielmy dane na rodzaj składu (niskopodłogowy i nie).
|
1 2 3 4 5 6 7 8 |
tramwaje %>% # tylko tramwaje w ruchu filter(Status=="RUNNING") %>% count(frame, LowFloor) %>% ungroup() %>% ggplot() + geom_line(aes(frame, n, color=LowFloor)) + labs(x="Numer próbki danych", y="Liczba tramwajów w ruchu") |
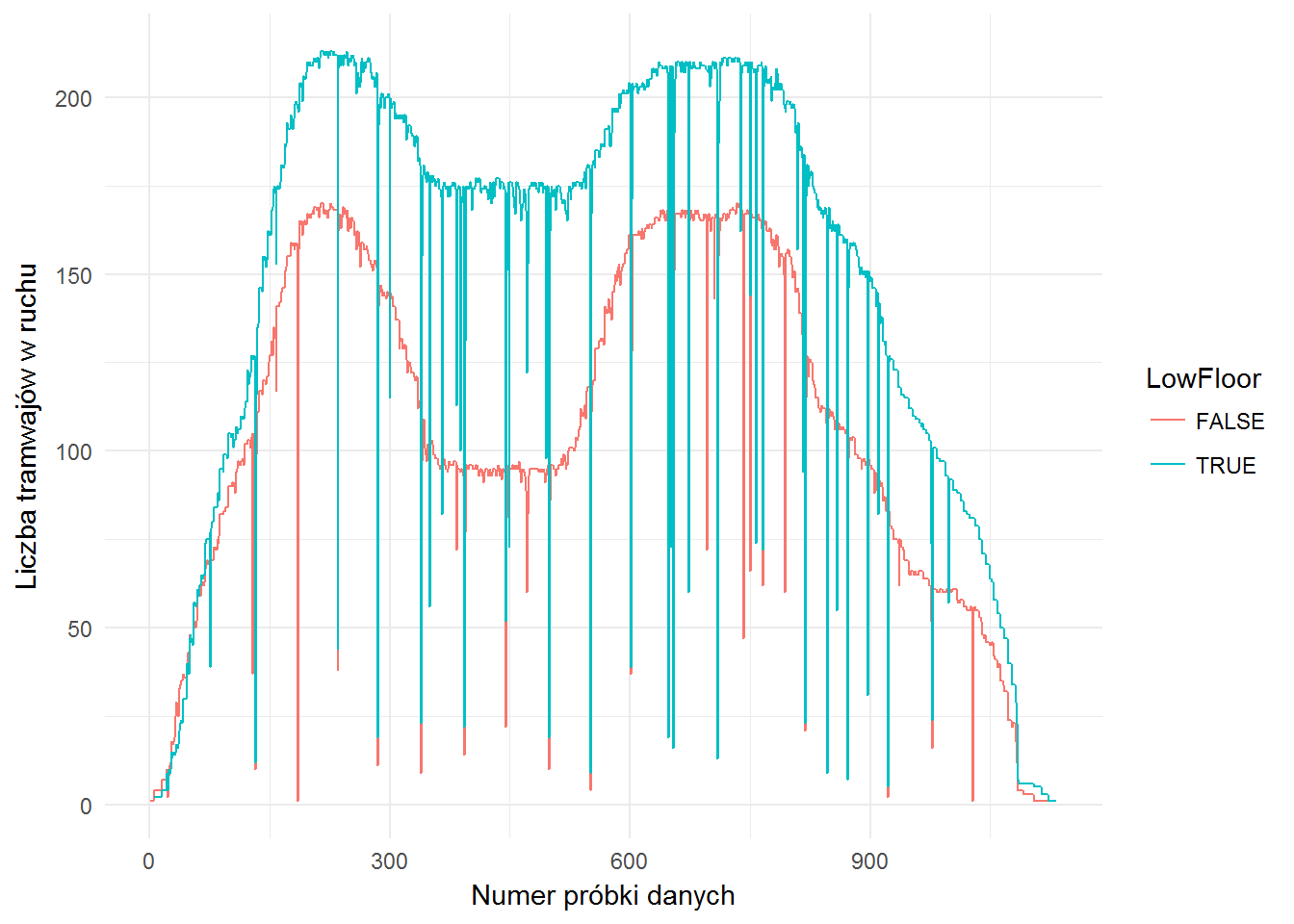
Widać zmiany razem z porą dnia, widać też jakieś pojedyncze piki (te szpilki w dół) wynikające z błędnych danych w API.
Można pokusić się o ich wygładzenie, ale szczerze powiedziawszy nie mają one większego znaczenia – interesuje nas trend. Poza tym – uważam, że w takim zadaniu nie warto. Zadaniem analityka jest dostarczyć użyteczne dane szybko. Szybkość informacji to o wiele większa wartość w biznesie niż 100% precyzja. Błąd na poziomie pewnie w okolicy 3% (ile jest tych szpilek? a danych mamy 1133 pomiarów…) jest w tym przypadku pomijalny. Można robić analizę tydzień i dość do błędu na poziomie promila, ale czy jest ona lepsza (w sensie przydatności biznesowej) od tej zrobionej w pół dnia z błędem 3% (lub mniejszym)? Możemy się spierać.
Swoją drogą – w API powinny być też tramwaje stojące, ale jak widać:
| Status | n |
|---|---|
| RUNNING | 282381 |
nie ma takowych :)
Do dalszej zabawy potrzebujemy wyskalowania osi czasu. Na naszej animacji będziemy rysować wykres zgodnie z upływem czasu – kolejne punkty będą pojawiać się na wykresie, więc zakres na osi czasu był ciągle taki sam. Znajdźmy chwilę początkową i końcową w naszych danych:
|
1 2 3 4 5 6 7 8 |
t_min <- min(tramwaje$Time) t_max <- max(tramwaje$Time) # miejsce na informacje zagregowane w kolejnych punktach czasu n_tramwaje <- data.frame() # numer brygady - o tym niżej brygada <- "3" |
Dla kolejnych ramek przygotujemy pakiet wykresów i mapkę. Te elementy umieścimy na jednym obrazku, który zapiszemy lokalnie. Później (już poza R) całą armię obrazków połączymy w animację – klatka po klatce.
Przygotowanie animacji – składowe elementy
W pętli na początku wybieramy dane z i-tej ramki:
|
1 2 3 4 5 6 7 8 9 |
for(i in 1:max(tramwaje$frame)) { # tramwaje w minutowym okienku tmp_tramwaje <- filter(tramwaje, frame==i) # ile wszystkich tramwajów w ruchu? n_tramwaje <- rbind(n_tramwaje, data.frame(t=mean(tmp_tramwaje$Time), n=nrow(tmp_tramwaje), l=nrow(tmp_tramwaje[tmp_tramwaje$LowFloor==TRUE,]))) |
Teraz przygotowujemy mapkę z położeniem tramwajów. Żeby było ładnie wszystkie tramwaje zaznaczymy na czerwono, a te, które prowadzi jedna brygada (na każdej linii jednocześnie jest kilka składów w trasie – to właśnie poszczególne brygady, numery brygad powtarzają się globalnie, ale w danym momencie dla linii numery brygad są unikalne) – na biało i nieco większe. Tylko która brygada powinna być wyróżniona?
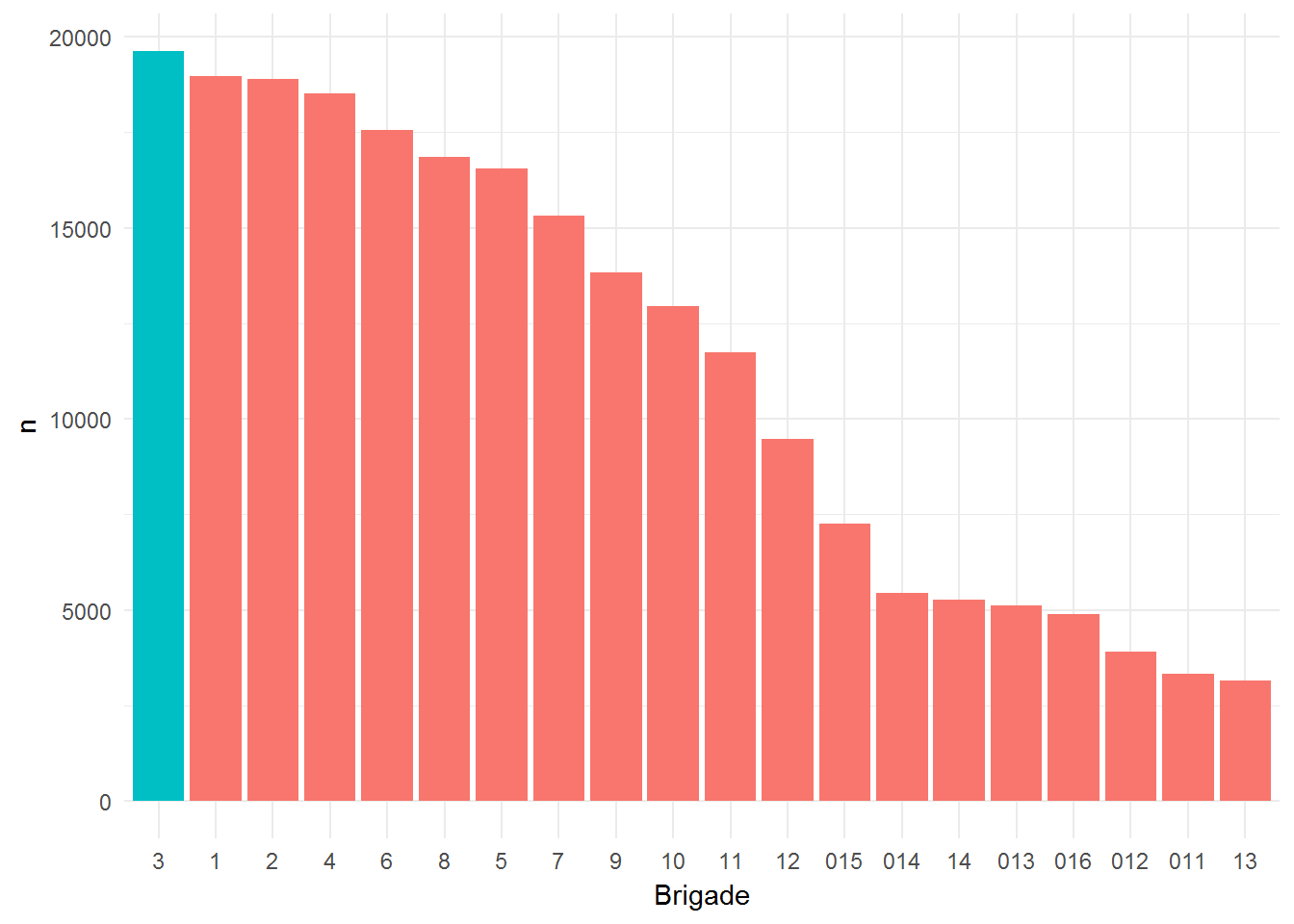
Wybrałem brygadę numer trzy, bo jak widać takich składów jest najwięcej (globalnie, ze wszystkich danych).
|
1 2 3 4 5 6 7 8 9 10 |
# mapa tramwajów p1 <- ggmap(map_waw, darken = 0.7) + geom_point(data=tmp_tramwaje, aes(Lon, Lat), color="red", size=1) + geom_point(data=filter(tmp_tramwaje, Brigade==brygada), aes(Lon, Lat), color="white", size=2) + theme_void() + theme(legend.position = "none") + labs(title="Położenie tramwajów", subtitle=substr(min(tmp_tramwaje$Time), 1, 16)) |
Zobaczmy jak taka mapa będzie wyglądać (dla losowo wybranej ramki, losowość w tym przypadku to tak naprawdę mediana z frame):
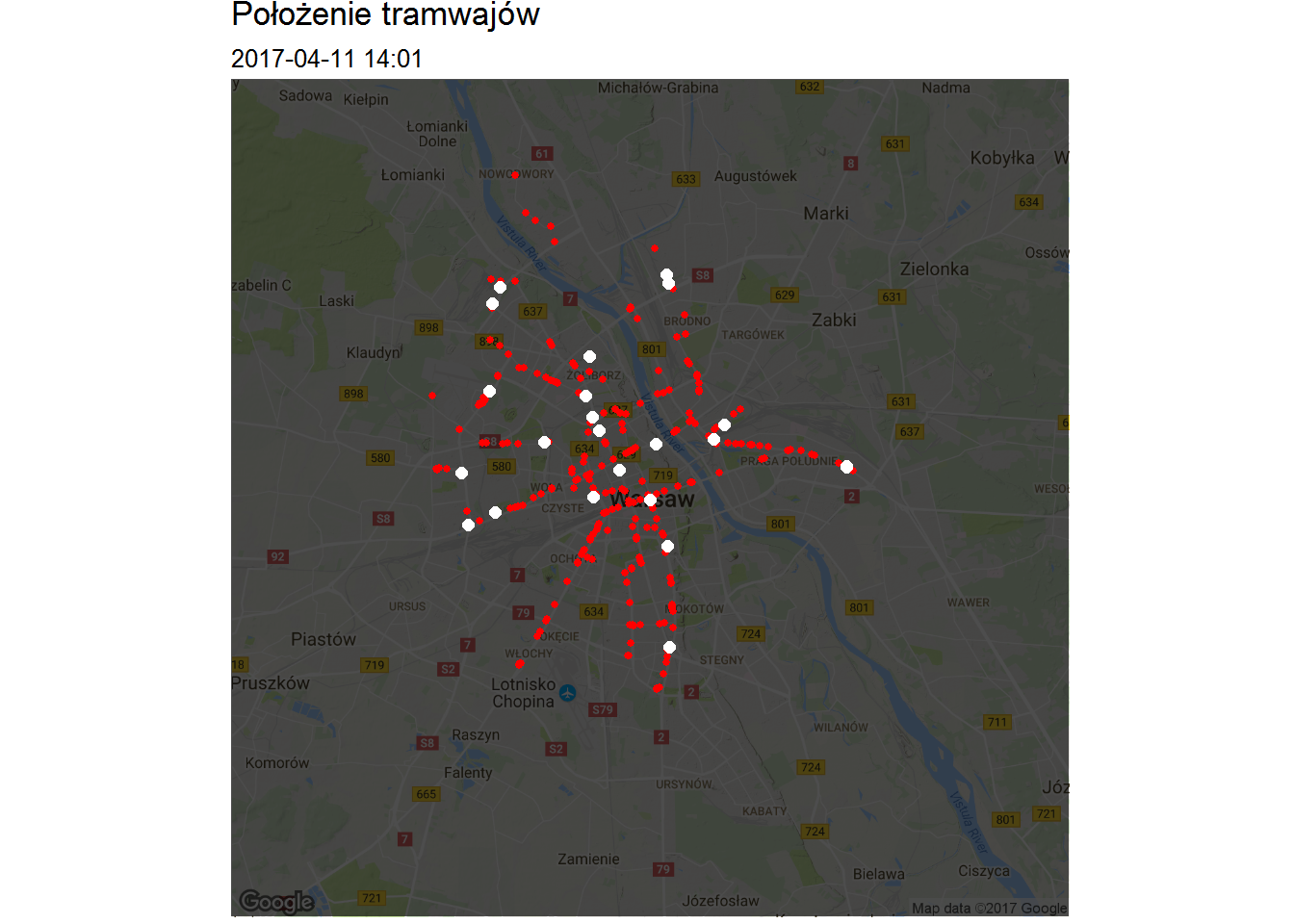
Dodajmy do tego podział na rodzaje składów na danej linii – ile niskopodłogowych dziesiątek jedzie w danym momencie? To zobaczymy na odpowiednim słupku.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# ile tramwajów niskopodłogowych na danej linii? p2 <- tmp_tramwaje %>% count(FirstLine, LowFloor) %>% ungroup() %>% group_by(FirstLine) %>% mutate(p=100*n/sum(n)) %>% ggplot() + geom_bar(aes(FirstLine, p, fill=LowFloor), stat="identity") + labs(title="Niskopodłogowe na liniach", x="", y="") + xlim(0, 50) + theme(legend.position = "none") + geom_hline(yintercept = 50, color="black") |
Efektem tego kodu będzie taki wykres (znowu – tutaj na losową chwilę; na złożonej w całość animacji osie nie będą opisane):
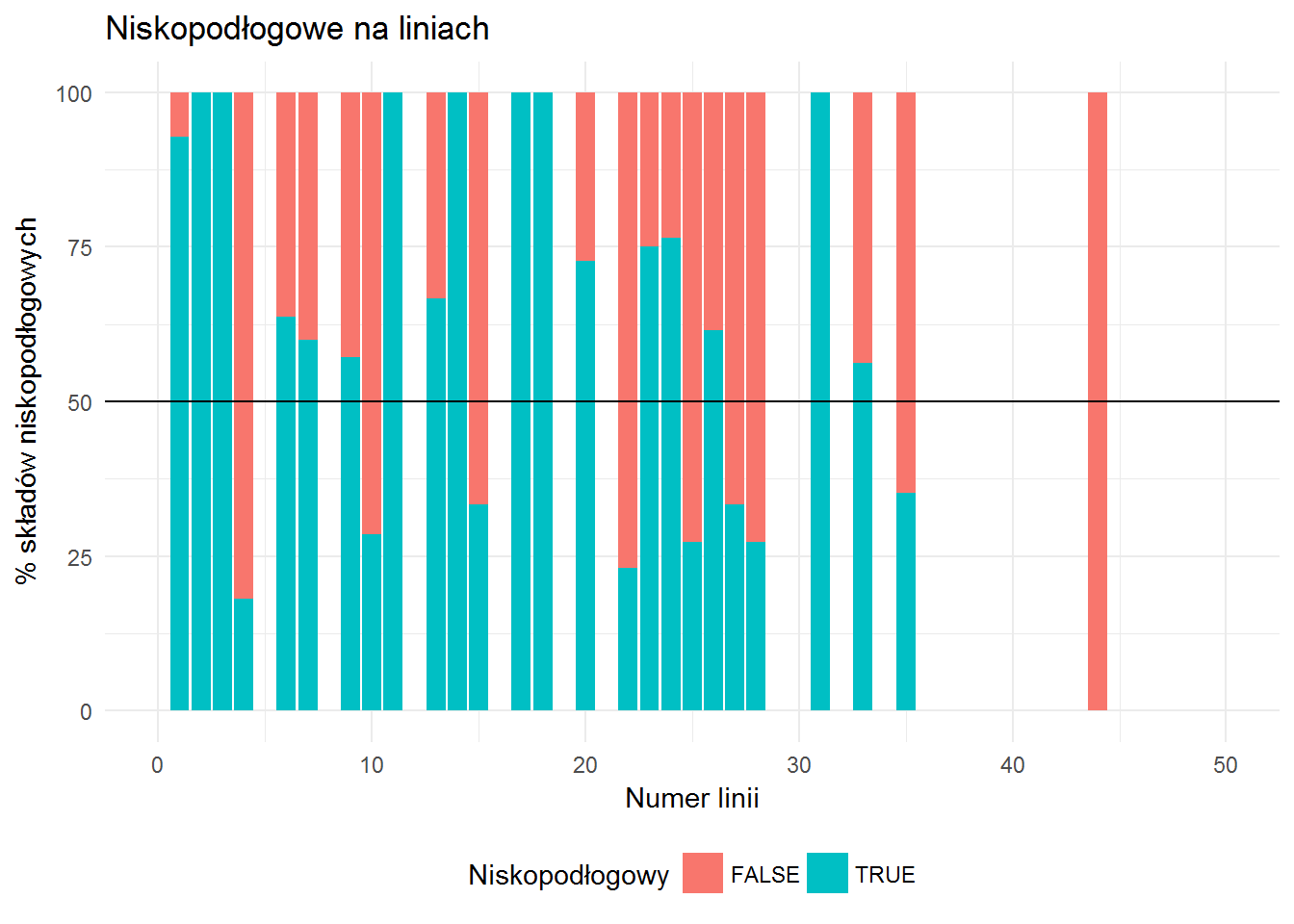
Widzimy przy okazji, że nie ma tramwajów o numerach 5, 8, 12, 16 i tak dalej – tam gdzie nie ma pasków.
Teraz dla bieżącej (w ramach pętli) ramki policzmy ile mamy wszystkich składów i ile z nich jest niskopodłogowych. Te dane gromadzimy w tabeli n_tramwaje i jednocześnie rysujemy całą tabelę od początku na dwóch wykresach – ile tramwajów i jaki procent z nich to niskopodłogowe. Zobaczymy też, czy udział tramwajów niskopodłogowych jest ciągle taki sam, czy też im więcej tramwajów w trasie tym mniej niskopodłogowych (bo wielkość taboru jest stała, a nie wszystkie pociągi są niskopodłogowe).
Tym razem bez obrazka :)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# wykres ilości tramwajów p3 <- ggplot(n_tramwaje) + geom_line(aes(t, n)) + scale_x_datetime(lim=c(as_datetime(t_min), as_datetime(t_max))) + ylim(0,400) + labs(title="Liczba tramwajów w ruchu", x="", y="") # ile niskopodłogowych? p4 <- ggplot(n_tramwaje) + geom_line(aes(t, 100*l/n)) + scale_x_datetime(lim=c(as_datetime(t_min), as_datetime(t_max))) + ylim(25,75) + labs(title="% niskopodłogowych w ruchu", x="", y="") # % niskopodłogowych vs liczba tramwajów p5 <- ggplot(n_tramwaje) + geom_point(aes(n, 100*l/n)) + xlim(0,400) + ylim(25,75) + labs(x="liczba tramwajów", y="% niskopodłogowych") |
Na koniec składamy w jeden obrazek wszystkie przygotowane wykresy i zapisujemy je do pliku z kolejnym numerem. I kończymy pętlę.
|
1 2 3 4 5 6 7 8 9 10 11 |
# łączymy wykresy w jeden obrazek plot <- arrangeGrob(p1, p2, p3, p4, p5, layout_matrix=rbind(c(1,1,3), c(1,1,4), c(1,1,5), c(1,1,2))) # zapisujemy obrazek na dysku ggsave(paste0("pics/", sprintf("%04d", i), ".png"), plot, width = 16, height = 9, dpi=120) } |
Wykonanie całej pętli na moim komputerze (kilkuletni Vaio) zajęła jakieś dwie-trzy godziny. Najbardziej pracochłonne jest generowanie obrazków; bez tej części pętla przechodzi dość szybko.
Wnioski
W katalogu pics/ mamy całą masę plików wyglądających mniej więcej tak:
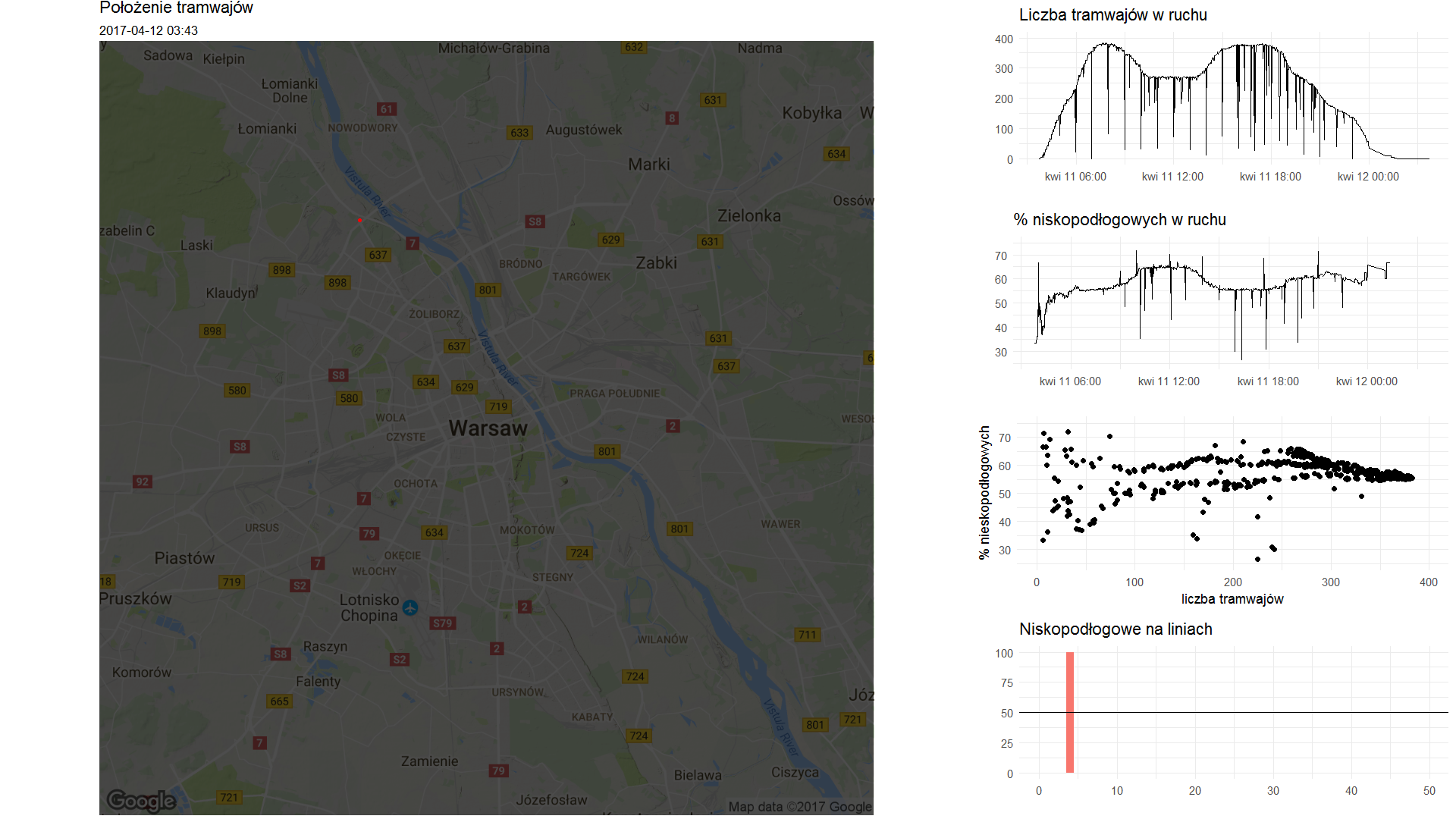
To jest ostatnia klatka – moment, kiedy mamy już wszystkie dane na bocznych wykresach, ale za to na mapie pusto. Pusto, bo wszystkie tramwaje już śpią w swoich tramwajowych domkach, na swoich tramwajowych poduszeczkach, przykryte tramwajowymi kołderkami z wyhaftowanymi autobusikami… taki żart, kiepski, wiem.
Widać (drugi i trzeci wykres od góry w prawej kolumnie) między innymi, że udział pociągów niskopodłogowych nie jest stały. Zapewne takich pociągów jest określona liczba i jeśli na trasach jest więcej tramwajów (na przykład w godzinach szczytu co widać z pierwszego wykresu w prawej kolumnie) to ich po prostu brakuje. Dlaczego dla 250 jeżdżących tramwajów raz niskopodłogowych jest jakieś 55%, a innym razem około 65%? Ciekawa to zmiana, będzie ją fajnie widać na animacji – zaobserwujcie wtedy gdzie przybywają kolejne punkty na trzecim od góry wykresie. Odpowiedź kryje się na drugim wykresie – w dzień niskopodłogowce są bardziej potrzebne (w dużym uproszczeniu).
Wygenerowanie animacji ze składowych (timelapse)
Możemy zamknąć R i przejść do sklejenia animacji poklatkowej. Metod jest wiele, moje “top of mind” mówi:
- VirtualDub – używam do składania timelapsów
- ImageMagick – korzysta z niego pakiet gganimate
- FFmpeg którego używałem do rozdzielenia filmów na pojedyncze klatki
- Photoshop – zapewne się da, w Photoshopie da się wszystko
Ja wybieram VirtualDub, bo wygenerowanie poklatkowej animacji sprowadza się do kilku kroków:
- uruchamiamy VirtualDub
- wybieramy z menu opcję Otwórz File/Open video file…
- wskazujemy pierwszy obrazek z całej serii, ważne – kolejne klatki muszą mieć kolejne numery, ale o to zadbaliśmy na poziomie skryptu R
- VirtualDub sam zaczyta kolejne pliki jako kolejne klatki
- wybieramy kodek, który wygenerujemy wideo (Video/Compression…); ja użyłem Xvid MPEG-4 Codec
- ewentualnie konfigurujemy ustawienia kodeka (Configure w oknie, w którym wybieramy kodek)
- ustawiamy ilość klatek na sekundę (Video/Frame rate…) – ja zmieniłem z domyślnych 25fps na 12 (Change frame rate to (fps))
- zapisujemy film (uruchamiając tym samym konwersję) w wybranym pliku (File/Save as AVI…)
- kiedy VirtualDub zrobi swoje będziemy mieć gotowy filmik
Tak samo (w najprostszej wersji) robi się timelapse’y i jest to o tyle banalne, że pliki z aparatu są od razu ponumerowane.
VirtualDub poradził sobie z przygotowaniem animacji w kilkanaście minut. Samo napisanie całego kodu z weryfikacją czy wszystko wygląda i działa jak należy to może 2-3 godziny, z czego 75% czasu to babranie się z wyglądem wykresów i mapy (kolory, przeźroczystość itp.). Podsumowując – cały proces zajął dwa dni (i noce maszynie zbierającej dane), samej pracy twórczej było z tego ze 2 godziny (2/48 daje 4%). Tak właśnie wygląda praca analityka danych – 96% nudnej roboty z przygotowaniem danych, 4% przyjemności. I wszystko to dla półtorej minuty wideo.
Gotowa animacja
Wynikowa animacja wygląda następująco (polecam full screen i full HD):
Czad.
Można dopracować kolory, układ, cokolwiek. Można przyczepić się do wielu elementów.
Nie ma bunkrów, a i tak jest zajebiście.
Ano czad :) I pomyśleć, że dla tajmlapsów instalowałem FCP #gupek
Pingback: Jak zrobić animowany wykres kołowy? | Łukasz Prokulski