W pierwszej części przygotowaliśmy zestaw narzędzi do uzyskania informacji skąd przyjechali mieszkańcy danej gminy oraz dokąd wyjechali. Oparliśmy się o dane GUSu o migracjach z 2016 roku. Obiecałem, że there is an app for this – dzisiaj taką aplikację przygotujemy.
Uwaga wpis jest mocno techniczny (i w dodatku dla co najmniej średnio zaawansowanych pRogramistów). Jeśli interesuje Cię wynik (gotowa aplikacja) najlepiej przejdź na stronę aplikacji i się nią pobaw do woli. Powinna być zrozumiała :)
Skorzystamy z pobranych wcześniej danych, ale rozważania prowadzić będziemy na poziomie powiatów. Zatem potrzebujemy zagregować dane o migracjach do powiatów oraz wykorzystać mapę powiatów (zamiast gmin). Zgodnie z wcześniejszymi uwagami – zobaczymy względny ruch, a nie bezwzględną liczbę osób zmieniających miejsce zamieszkania (stałego zamieszkania, bo dane GUSu dotyczą osób zmieniających meldunek).
Większość danych mamy już przygotowanych i cała droga będzie krótsza. Z poniższych pakietów
|
1 2 3 |
library(tidyverse) library(broom) library(rgdal) |
wystarczy później tylko tidyverse, ale będziemy potrzebowali wstępnego przygotowania map – stąd broom i rgdal.
Zaczniemy od nazwy powiatów i województw z bazy TERYT:
|
1 2 3 4 5 6 7 8 9 10 |
Baza_TERYT <- read_csv2("TERC_Urzedowy_2017-09-21.csv") wojewodztwa <- Baza_TERYT %>% filter(is.na(POW)) %>% select(WOJ, Wojewodztwo = NAZWA) powiaty <- Baza_TERYT %>% filter(is.na(GMI), NAZWA_DOD != "województwo") %>% select(WOJ, POW, Powiat = NAZWA) %>% mutate(TERYT_POW = paste0(WOJ, POW)) %>% left_join(wojewodztwa, by = "WOJ") %>% select(TERYT = TERYT_POW, Powiat, TERYT_WOJ = WOJ, Wojewodztwo) |
W aplikacji Shiny będziemy chcieli pokazać informacje o wybranym powiecie. Wybór będzie polegał na wskazaniu województwa (z listy 16), a następnie powiatu (z tych, które znajdują się w województwie). To wygodniejsze niż przedzieranie się przez listę 380 powiatów. Oba pola wyboru musimy jakoś zasilić, a co więcej – pole dla powiatów powinno reagować na to co wskazuje województwo.
Potrzebujemy więc listy województw. Dla Shiny dobrze mieć nazwaną listę (wektor) – nazwa elementu jest wyświetlana na polu wyboru, jego wartość jest zwracana przy wyborze do aplikacji. Będziemy operować na kodach TERYT – stąd kolumna WOJ (zawierająca kod TERYT województwa):
|
1 2 |
ListaWojewodztw <- wojewodztwa$WOJ names(ListaWojewodztw) <- wojewodztwa$Wojewodztwo |
Teraz czas na powiaty, które zależą od wybranego województwa. Wystarczy z listy powiatów wybrać te, które należą do województwa o znanym numerze TERYT i zwrócić je w postaci odpowiednio przygotowanej listy. Najlepiej przy pomocy funkcji:
|
1 2 3 4 5 6 7 |
ListaPowiatow <- function(woj_teryt) { lista <- powiaty %>% filter(TERYT_WOJ == woj_teryt) %>% select(Powiat, TERYT) lista_lst <- lista$TERYT names(lista_lst) <- lista$Powiat return(lista_lst) } |
Wynik działania takiej funkcji dla województwa o kodzie TERYT równym 14 (mazowieckie) wygląda następująco:
|
1 |
ListaPowiatow("14") |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
## białobrzeski ciechanowski garwoliński ## "1401" "1402" "1403" ## gostyniński grodziski grójecki ## "1404" "1405" "1406" ## kozienicki legionowski lipski ## "1407" "1408" "1409" ## łosicki makowski miński ## "1410" "1411" "1412" ## mławski nowodworski ostrołęcki ## "1413" "1414" "1415" ## ostrowski otwocki piaseczyński ## "1416" "1417" "1418" ## płocki płoński pruszkowski ## "1419" "1420" "1421" ## przasnyski przysuski pułtuski ## "1422" "1423" "1424" ## radomski siedlecki sierpecki ## "1425" "1426" "1427" ## sochaczewski sokołowski szydłowiecki ## "1428" "1429" "1430" ## warszawski zachodni węgrowski wołomiński ## "1432" "1433" "1434" ## wyszkowski zwoleński żuromiński ## "1435" "1436" "1437" ## żyrardowski Ostrołęka Płock ## "1438" "1461" "1462" ## Radom Siedlce Warszawa ## "1463" "1464" "1465" |
Czas na dane o migracjach. W poprzednim wpisie opisałem jak je przygotować – warto zapisać tak przygotowaną tabelę (migracje) do pliku (tutaj migracje.rds), który teraz wykorzystamy. I zagregujemy dane do poziomu powiatów:
|
1 2 3 4 5 6 7 8 9 10 |
# migracje pomiędzy gminami - z poprzedniego wpisu migracje <- readRDS("migracje.rds") # agregowane do powiatów migracje_pow <- migracje %>% mutate(From_Pow_TERYT = substr(From_TERYT, 1, 4), To_Pow_TERYT = substr(To_TERYT, 1, 4)) %>% group_by(From_Pow_TERYT, To_Pow_TERYT) %>% summarise(Liczba_osob = sum(Liczba_osob)) %>% ungroup() |
Teraz możemy zapisać sobie tabelę migracje_pow do pliku lokalnego (aby zminimalizować czas uruchomienia aplikacji). Albo zaczekać, bo swoje zajmie też przygotowanie map:
|
1 2 3 4 |
# mapa powiatów powiaty_mapa <- readOGR("../!mapy_shp/powiaty.shp", layer = "powiaty") powiaty_mapa <- spTransform(powiaty_mapa, CRS("+init=epsg:4326")) powiaty_mapa <- tidy(powiaty_mapa, region = "jpt_kod_je") |
Oczywiście korzystamy z plików z wielkiego archiwum pobranego z CODGiK.
Swoją drogą można również skorzystać z funkcji getData() z pakietu raster: powiaty_mapa <- raster::getData("GADM", file = "POL", level = 2), tak otrzymane dane trzeba później przepuścić przez tidy (bo pobrane dane to właściwie plik SHP). Problem z nimi jednak jest taki, że nie posiadają kodów TERYT (są nazwy, ale w jakimś języku obcym – nie ułatwia to zadania).
Podobnie jak dla gmin zmniejszymy sobie dokładność map:
|
1 2 3 4 5 6 7 8 |
powiaty_mapa_small <- powiaty_mapa %>% arrange(order) %>% mutate(long = round(long, 2), lat = round(lat, 2)) %>% select(-order) %>% distinct() %>% group_by(group, id, hole) %>% mutate(order = row_number()) %>% ungroup() |
W efekcie otrzymując coś całkiem przyjemnego i wystarczająco dokładnego:
|
1 2 3 4 |
powiaty_mapa_small %>% ggplot() + geom_polygon(aes(long, lat, group=group, fill = id), color = "black", show.legend = FALSE) + coord_map() |
W tym miejscu zakończyliśmy poprzednim razem przygotowanie danych dla gmin. Ale dzisiaj weźmiemy pod uwagę procent osób jakie zmieniło miejsce zamieszania (zatem wartości względne), a do tego potrzebujemy informacji o stanie ludności w danym powiecie na koniec 2016 roku. Za źródło posłuży nam tradycyjnie GUS (konkretnie dane pobrane z kategorii Ludność / Stan ludności / Ludność wg miejsca zamieszkania (dane kwartalne) dla wszystkich powiatów, stan na koniec 2016 roku).
|
1 2 3 4 5 6 7 |
# ludność - dane z GUS ludnosc <- read_csv2("LUDN_2461_CREL_20170925092715.csv") ludnosc_pow <- ludnosc %>% filter(substr(Kod, 3, 4) != "00") %>% mutate(Kod = substr(Kod, 1, 4)) %>% select(Kod, Ludnosc=Wartosc) |
Teraz tylko trzeba złączyć informacje o migracjach z liczbą mieszkańców powiatu i policzyć jaki procent mieszkańców ubył (lub przybył):
|
1 2 3 4 5 6 7 |
migracje_pow <- migracje_pow %>% left_join(ludnosc_pow, by = c("From_Pow_TERYT" = "Kod")) %>% rename(From_Ludnosc = Ludnosc) %>% left_join(ludnosc_pow, by = c("To_Pow_TERYT" = "Kod")) %>% rename(To_Ludnosc = Ludnosc) %>% mutate(From_Proc = 100 * Liczba_osob / From_Ludnosc, To_Proc = 100 * Liczba_osob / To_Ludnosc) |
Dane łączymy dwukrotnie – raz dla powiatów źródłowych i drugi raz dla powiatów docelowych.
Sprawdźmy tym razem skąd do przyjechali ludzie do Warszawy? (kod 1465)
|
1 2 3 |
migracje_pow %>% filter(To_Pow_TERYT == "1465") %>% arrange(desc(From_Proc)) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
## # A tibble: 250 × 7 ## From_Pow_TERYT To_Pow_TERYT Liczba_osob From_Ludnosc To_Ludnosc ## <chr> <chr> <int> <int> <int> ## 1 1465 1465 13332 1744351 1744351 ## 2 1418 1465 603 177007 1744351 ## 3 1408 1465 323 113242 1744351 ## 4 1421 1465 458 160776 1744351 ## 5 1432 1465 315 112957 1744351 ## 6 1434 1465 638 235043 1744351 ## 7 1464 1465 195 76942 1744351 ## 8 1417 1465 305 123120 1744351 ## 9 1461 1465 117 52571 1744351 ## 10 2062 1465 127 62737 1744351 ## # ... with 240 more rows, and 2 more variables: From_Proc <dbl>, ## # To_Proc <dbl> |
Pierwszy na liście (poza Warszawą) jest powiat o numerku 1418, czyli:
|
1 |
powiaty %>% filter(TERYT == "1418") |
|
1 2 3 4 |
## # A tibble: 1 × 4 ## TERYT Powiat TERYT_WOJ Wojewodztwo ## <chr> <chr> <chr> <chr> ## 1 1418 piaseczyński 14 MAZOWIECKIE |
powiat piaseczyński. Jak wyglądają odpowiednie liczby?
|
1 2 3 |
migracje_pow %>% filter(To_Pow_TERYT == "1465", From_Pow_TERYT == "1418") %>% select(-From_Pow_TERYT, -To_Pow_TERYT) |
|
1 2 3 4 |
## # A tibble: 1 × 5 ## Liczba_osob From_Ludnosc To_Ludnosc From_Proc To_Proc ## <int> <int> <int> <dbl> <dbl> ## 1 603 177007 1744351 0.3406645 0.03456873 |
Około 0.34% (603 osób z 177007) mieszkańców powiatu piaseczyńskiego przeprowadziło się do Warszawy, co jednocześnie oznacza, że nieco ponad 0.03% (603 z 1744351) mieszkańców Warszawy przybyło właśnie z tego powiatu.
Przy okazji: największy ruch był z Wrocławia do powiatu wrocławskiego (1.6% mieszkańców powiatu wrocławskiego przyjechało z Wrocławia) oraz przemeldowań w obrębie Łodzi (0.87% mieszkańców tego miasta zmieniło adres).
W tym momencie mamy komplet przygotowanych danych:
- dane o mapie powiatów
powiaty_mapa_small - dane o migracjach pomiędzy powiatami
powiaty_mapa_small - listy nazw powiatów i województw (odpowiedni wyciąg z tabeli
powiaty)
Wszystkie te dane możemy zapisać lokalnie, a w aplikacji skorzystać z tak przygotowanych plików. Oszczędzamy dzięki temu czas na powtarzanie obliczeń, które wystarczy wykonać tylko raz.
Przed przystąpieniem do programowania aplikacji zobaczmy jeszcze mapkę powiatów, które zasiliły mieszkańców Warszawy (skoro ostatnio był Kraków, to teraz – w imię świętej wojny – Warszawa):
|
1 2 3 4 5 6 7 8 |
powiaty_mapa_small %>% left_join(migracje_pow %>% filter(To_Pow_TERYT == "1465"), by = c("id" = "From_Pow_TERYT")) %>% ggplot() + geom_polygon(aes(long, lat, group = group, fill = From_Proc), color = "gray80") + scale_fill_gradient(low = "darkred", high = "yellow", na.value = "white") + coord_map() |
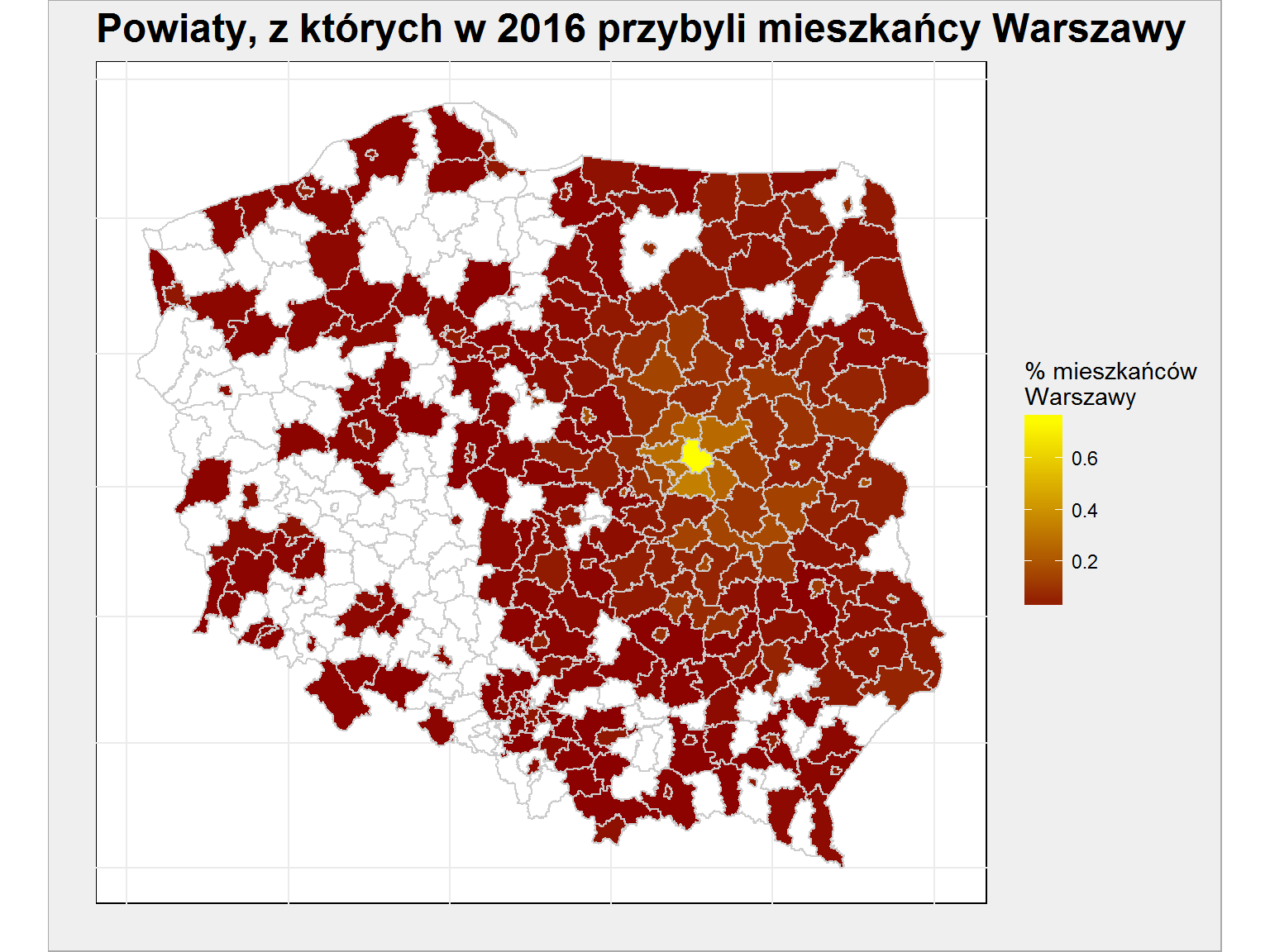
Do Warszawy przyjeżdża się z większości (dokładnie z 250 spośród 380) powiatów w Polsce, różnic wielkich nie ma. Najwięcej jest migracji wewnątrz stolicy (przemeldowania w ramach miasta), a później imigracja z najbliższych powiatów. Trochę jaśniejsze kolory ciągną się w stronę Lublina (L na początku rejestracji samochodów jeżdżących po Warszawie nie bierze się od Legii, taki żart).
Co się dzieje w zachodniej części Polski? Gdzie migrują ludzie z mniejszych powiatów na przykład południowej Wielkopolski? Za chwilę będziecie mogli sami to sprawdzić wybierając powiaty kępiński (z dużych miast Wrocław, albo powiat wieruszowski) albo krotoszyński (Wrocław i Poznań, powiat ostrowski) w aplikacji, którą przygotujemy.
Bazując na poprzednim wpisie przygotujemy zmodyfikowaną funkcję dającą na tacy wszystkie interesujące nas parametry. Później funkcja ta posłuży nam w aplikacji i będzie jej najważniejszym elementem (maszyną wybierająco-dostarczającą, że tak powiem).
Tak na prawdę działanie aplikacji jest banalne: pozwalamy na wybranie województwa i powiatu, wywołyjemy poniższą funkcję z odpowiednim kodem TERYT wybranego powiatu i wyświetlamy stosowne informacje. Prawda, że proste? Większość paneli czy dashboardów do przeglądania danych tak właśnie działa!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 |
Migration <- function(powiat_teryt) { # znajdżmy nazwę powiatu nazwa_powiatu <- powiaty %>% filter(TERYT == powiat_teryt) %>% mutate(Nazwa = paste0(Powiat, ", woj. ", tolower(Wojewodztwo))) %>% .$Nazwa # przyjezdni do powiatu migracje_powiat_to <- migracje_pow %>% filter(To_Pow_TERYT != From_Pow_TERYT) %>% filter(To_Pow_TERYT == powiat_teryt) # mapa przyjezdnych mapa_to <- powiaty_mapa_small %>% left_join(migracje_powiat_to, by = c("id" = "From_Pow_TERYT")) %>% ggplot() + geom_polygon(aes(long, lat, group=group, fill = To_Proc), color = "gray80") + scale_fill_gradient(low = "darkred", high = "orange", na.value = "white") + coord_map() + labs(title = paste0("Do ", nazwa_powiatu, " przybywają z:"), x = "", y = "", fill = "Procent liczby mieszkańców powiatu") + theme(legend.position = "bottom") # wyjezdni do powiatu migracje_powiat_from <- migracje_pow %>% filter(To_Pow_TERYT != From_Pow_TERYT) %>% filter(From_Pow_TERYT == powiat_teryt) # mapa mapa_from <- powiaty_mapa_small %>% left_join(migracje_powiat_from, by = c("id" = "To_Pow_TERYT")) %>% ggplot() + geom_polygon(aes(long, lat, group=group, fill = From_Proc), color = "gray80") + scale_fill_gradient(low = "darkred", high = "orange", na.value = "white") + coord_map() + labs(title = paste0("Z ", nazwa_powiatu, " kierują się do:"), x = "", y = "", fill = "Procent liczby mieszkańców powiatu") + theme(legend.position = "bottom") # słupki z 20 najpopularniejszymi powiatami barplot_from <- migracje_powiat_from %>% top_n(20, Liczba_osob) %>% left_join(powiaty, by = c("To_Pow_TERYT" = "TERYT")) %>% mutate(Wojewodztwo = tolower(Wojewodztwo), Powiat_To = paste0(Powiat, ", woj. ", Wojewodztwo)) %>% select(Liczba_osob, Powiat_To, Powiat, Wojewodztwo) %>% arrange(Liczba_osob) %>% mutate(Powiat = factor(Powiat, levels = Powiat)) %>% ggplot() + geom_col(aes(Powiat, Liczba_osob, fill = as.factor(Wojewodztwo))) + coord_flip() + labs(title = paste0("Z ", nazwa_powiatu, " kierują się do:"), subtitle = "Dwadzieścia najpopularniejszych powiatów", x = "", y = "Liczba osób, które zmieniły miejsce zameldowania", fill = "województwo") barplot_to <- migracje_powiat_to %>% top_n(20, Liczba_osob) %>% left_join(powiaty, by = c("From_Pow_TERYT" = "TERYT")) %>% mutate(Wojewodztwo = tolower(Wojewodztwo), Powiat_From = paste0(Powiat, ", woj. ", Wojewodztwo)) %>% select(Liczba_osob, Powiat_From, Powiat, Wojewodztwo) %>% arrange(Liczba_osob) %>% mutate(Powiat = factor(Powiat, levels = Powiat)) %>% ggplot() + geom_col(aes(Powiat, Liczba_osob, fill = as.factor(Wojewodztwo))) + coord_flip() + labs(title = paste0("Do ", nazwa_powiatu, " przybywają z:"), subtitle = "Dwadzieścia najpopularniejszych powiatów", x = "", y = "Liczba osób, które zmieniły miejsce zameldowania", fill = "województwo") # wojewodztwa - tabela table_woj_to <- migracje_powiat_to %>% mutate(From_Woj = substr(From_Pow_TERYT, 1, 2)) %>% group_by(From_Woj) %>% summarise(Liczba_osob = sum(Liczba_osob)) %>% ungroup() %>% left_join(wojewodztwa, by = c("From_Woj" = "WOJ")) %>% mutate(Wojewodztwo = tolower(Wojewodztwo)) %>% arrange(desc(Liczba_osob)) table_woj_from <- migracje_powiat_from %>% mutate(To_Woj = substr(To_Pow_TERYT, 1, 2)) %>% group_by(To_Woj) %>% summarise(Liczba_osob = sum(Liczba_osob)) %>% ungroup() %>% left_join(wojewodztwa, by = c("To_Woj" = "WOJ")) %>% mutate(Wojewodztwo = tolower(Wojewodztwo)) %>% arrange(desc(Liczba_osob)) # wszystkie przygotowane dane zwracamy w postaci listy return(list(mapa_to = mapa_to, mapa_from = mapa_from, barplot_from = barplot_from, barplot_to = barplot_to, table_woj_to = table_woj_to, table_woj_from = table_woj_from)) } |
Mamy wszystkie komponenty gotowe, zbudujmy aplikację
Aplikacja w Shiny
Potrzebna będzie dodatkowa biblioteka – shiny. Cała aplikacja może być w dwóch plikach (ui.R oraz server.R) lub w jednym (app.R, w takim przypadku umieścić ją trzeba w stosownym kontenerze shinyApp()). Cały kod z dzisiejszego odcinka możecie wrzucić w jeden plik app.R i zadziała.
|
1 2 3 |
library(shiny) application <- shinyApp( |
Pierwsza część to wygląd (User Interface) aplikacji. Nie będę wnikał w szczegóły, jest wielka dokumentacja razem z bardzo dobrym tutorialem.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
ui <- pageWithSidebar( # tytuł naszej aplikacji headerPanel('Migracje Polaków w 2016 roku'), # panel boczny - ze sterowaniem sidebarPanel( # wybierak województwa selectInput('wojewodztwo', 'Województwo:', choices = ListaWojewodztw), # wybierak powiatu selectInput('powiat', 'Powiat:', choices = character(0)), # panel boczny będzie zajmował 3/12 szerokości okna width = 3 ), # panel główny mainPanel( # dwie zakładki - dokąd i skąd tabsetPanel( tabPanel("Dokąd wyjechali?", # w ramach zakładki "dokąd" - trzy zakładki na wyniki: tabsetPanel( # mapka powiatów tabPanel("Mapa powiatów", plotOutput('from_plot_map', width = 500, height = 500)), # wykres słupkowy tabPanel("Liczba mieszkańców - powiaty", plotOutput('from_plot_bar', width = 500, height = 500)), # tabela województw tabPanel("Liczba mieszkańców - województwa", tableOutput('from_table')) ) ), # zakładka "skąd" z analogicznym układem tabPanel("Skąd przyjechali?", tabsetPanel( tabPanel("Mapa powiatów", plotOutput('to_plot_map', width = 500, height = 500)), tabPanel("Liczba mieszkańców - powiaty", plotOutput('to_plot_bar', width = 500, height = 500)), tabPanel("Liczba mieszkańców - województwa", tableOutput('to_table')) ) ) ), # szerokość panelu głównego - 9/12 szerokości strony width = 9 ) ), |
Druga część aplikacji to jej logika. Tutaj przygotujemy reakcje na odpowiednie wybory oraz prezentację danych wynikowych:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
server <- function(input, output, session) { # sprawdź czy zmieniło się województwo observe({ woj <- input$wojewodztwo # zaktualizuj listę powiatów updateSelectInput(session, "powiat", choices = ListaPowiatow(woj)) }) # czy zmienił się powiat? jeśli tak - przygotuj wszystkie dane dla tego powiatu dane <- reactive({ Migration(input$powiat) }) # pokaż dane w zakładce "dokąd" output$to_plot_map <- renderPlot({ dane()$mapa_to }) # mapa powiatów output$to_plot_bar <- renderPlot({ dane()$barplot_to }) # wykres słupkowy output$to_table <- renderTable({ dane()$table_woj_to %>% select(Wojewodztwo, Liczba_osob) }) # tabela województw # wyniki w zakładce "skąd" output$from_plot_map <- renderPlot({ dane()$mapa_from }) output$from_plot_bar <- renderPlot({ dane()$barplot_from }) output$from_table <- renderTable({ dane()$table_woj_from %>% select(Wojewodztwo, Liczba_osob) }) } ) |
I to wszytko!
Możemy już uruchomić naszą aplikację wpisując w konsoli:
|
1 |
runApp(application) |
Wynik jest następujący (może nieco nie mieścić się w ramce, ale zwróćcie uwagę, że samo się ładnie zawija):
Jeśli coś wyżej nie działa to… może serwer nie wytrzymał? Nie wiem ile może wytrzymać (to darmowy EC2 t2.micro z Amazonu), pierwszy raz puszczam na niego większy ruch.
Prawda, że fajne? Zamiast oglądać wynik w ramce możesz zobaczyć go w pełnym oknie przeglądarki, o tutaj.
Cały skrypt możemy zapisać jako plik app.R i (o ile mamy maszynę z zainstalowanym serwerem Shiny) udostępnić aplikację innym po prostu podając do niej adres. O szczegółach instalacji i konfiguracji serwera najlepiej doczytać na stosownej stronie. Jeśli chodzi o wymagania dla serwera Shiny: potrzebny jest serwer z Linuxem (na przykład Ubuntu) na 64-bitowym komputerze. Kilka takich maszyn (wirtualnych) postawiłem w życiu, więc jeśli bardzo wyraźnie poprosicie to przygotuję odpowiedni wpis.
Tymczasem – przyjemnej zabawy z aplikacją!