Chcesz wiedzieć skąd pochodzą mieszkańcy Twojej gminy? Albo jak narysować mapę dowolnej wartości na poziomie gmin, powiatów lub województw?
Coś podobnego zrobiło jakiś czas temu BIQdata, po sieci krążyło ostatnio to samo dla Stanów Zjednoczonych. Dzisiaj nauczymy się jak to zrobić samodzielnie. A w następnej części przygotujemy aplikację (wow!).
Jedziemy zatem z pakietami, a później szczegółową instrukcją na zdobycie danych.
|
1 2 3 |
library(tidyverse) library(broom) library(rgdal) |
Baza nazw gmin, powiatów i województw
Potrzebujemy danych o nazwach gmin, powiatów i województw przyporządkowanych do kodów TERYT. Takie dane znajdziemy w GUSie na odpowiedniej stronie, z której pobieramy archiwum TERC / podstawowa i rozpakowujemy ZIPa, z którego potrzebny nam plik CSV.
|
1 |
Baza_TERYT <- read_csv2("TERC_Urzedowy_2017-09-21.csv") |
Oglądamy sobie dane i wydzielamy kolejno regiony (odpowiednie fragmenty kodu TERYT są puste):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
wojewodztwa <- Baza_TERYT %>% filter(is.na(POW)) %>% select(WOJ, Wojewodztwo = NAZWA) powiaty <- Baza_TERYT %>% filter(is.na(GMI), NAZWA_DOD != "województwo") %>% select(WOJ, POW, Powiat = NAZWA) %>% mutate(TERYT_POW = paste0(WOJ, POW)) gminy <- Baza_TERYT %>% filter(!is.na(GMI)) %>% select(WOJ, POW, GMI, RODZ, Gmina = NAZWA, NAZWA_DOD) %>% mutate(NAZWA_DOD = ifelse(NAZWA_DOD == "dzielnica", "dzielnica Warszawy", NAZWA_DOD)) %>% mutate(TERYT = paste0(WOJ, POW, GMI, RODZ), Nazwa_gminy = paste0(Gmina, " (", NAZWA_DOD, ")")) %>% left_join(powiaty, by = c("WOJ" = "WOJ", "POW" = "POW")) %>% left_join(wojewodztwa, by = c("WOJ" = "WOJ")) %>% select(TERYT, Nazwa_gminy, Powiat, Wojewodztwo) |
Przy okazji na poziomie gmin dodaliśmy informacje o powiecie i województwie go którego należy gmina oraz jej rodzaju.
W tabeli z powiatami możemy sprawdzić, że mamy osobno Wałbrzych i powiat wałbrzyski – pisałem o tej zmianie jakoś ostatnio.
Dane o migracji
Też są w GUSie w bazie Demografia, konkretnie jest to tabela 2g dostępna przez ścieżkę:
- Migracje ludności
- Migracje wewnętrzne
- 2016
- 2g – Migracje wewnętrzne ludności na pobyt stały według gminy poprzedniego i obecnego miejsca zamieszkania
- Ogólnopolskie
Rozpakowujemy archiwum, z którego wyciągamy plik excela. Oglądamy sobie tabelę w Excelu i widzimy, że interesujące nas dane zaczynają się od komórki E5. Ja wyciąłem to co zbędne (nagłówki do wiersza 6 i kolumny A-D oraz F) zostawiając jedynie tabelę z pierwszą kolumną równą kodowi TERYT gminy obecnego zamieszkania, wiersze od kodu TERYT gminy poprzedniego zamieszkania. Przy okazji znaki “#” zamieniłem na zera. Usunąłem również sumy (ostatni wiersz i ostania kolumna). Tak przygotowane dane zapisałem w pliku CSV. Wszystko to można zrobić również w R, ale tym razem szybciej robi się to w Excelu.
Przygotowany plik CSV musimy jeszcze nieco przemodelować, to już w R:
|
1 2 3 4 5 6 7 8 |
migracje_org <- read_csv2("migracje.csv") # robimy z niego długą tabelę (unpivot) migracje <- migracje_org %>% gather(key = From_TERYT, value = Liczba_osob, -TERYT) %>% rename(To_TERYT = TERYT) %>% # i usuwamy te kombinacje, gdzie nie było przepływu osób (żeby zmniejszyć ilość danych) filter(Liczba_osob != 0) |
Możemy zobaczyć kilka pierwszych wierszy:
|
1 |
head(migracje) |
| To_TERYT | From_TERYT | Liczba_osob |
|---|---|---|
| 0201022 | 0201011 | 109 |
| 0201032 | 0201011 | 6 |
| 0201044 | 0201011 | 3 |
| 0201045 | 0201011 | 14 |
| 0201052 | 0201011 | 8 |
| 0201062 | 0201011 | 42 |
i sprawdzić czy nie pokręciliśmy nazw kolumn – czy z gminy 0201011 do gminy 0201062 przeprowadziły się 42 osoby? Tak wynika z tabeli w Excelu, a jak jest w naszych danych w R:
|
1 2 |
migracje %>% filter(From_TERYT == "0201011", To_TERYT == "0201062") |
| To_TERYT | From_TERYT | Liczba_osob |
|---|---|---|
| 0201062 | 0201011 | 42 |
Wszystko jest ok, więc możemy jechać dalej!
Mapy
Potrzebujemy plików SHP – jak w poprzednich postach skorzystamy z danych ze strony CODGiK, pobieramy pliki PRG – jednostki administracyjne, rozpakowujemy i możemy używać. Ja jeszcze zmieniłem w nazwach plików polskie znaki na takie bez ogonków i zostawiłem same małe literki (gmin to akurat nie dotyczy, ale dotyczy innych plików i przydatne jest przy korzystaniu z tych samych plików w różnych systemach operacyjnych – Linux i Windows)
Weźmiemy oczywiście mapkę gmin – na ich poziomie mamy dane:
|
1 2 3 |
gminy_mapa <- readOGR("../!mapy_shp/gminy.shp", layer = "gminy") gminy_mapa <- spTransform(gminy_mapa, CRS("+init=epsg:4326")) gminy_mapa <- tidy(gminy_mapa, region = "jpt_kod_je") |
Mapy są bardzo dokładne, a nie potrzebujemy aż takiej dokładności granic gminy w widoku całego kraju. Dla szybszego rysowania możemy je nieco uprościć, na przykład zaokrąglając dokładność współrzędnych.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
gminy_mapa_small <- gminy_mapa %>% # grupujemy dane o mapie po obrysie (z uwzględnieniem "dziurek") group_by(id, group, piece, hole) %>% # ukłaamy w odpowiednim porządku (linie rysowane są zgodnie z kolejnością punktów) arrange(order) %>% # zaokrąglamy liczby do dwóch miejsc po przecinku mutate(long = round(long, 2), lat = round(lat, 2)) %>% ungroup() %>% # porządek nadamy na nowo, możemy go więc teraz usunąć select(-order) %>% # zostawiamy tylko unikalne punkty - usuwamy duplikaty distinct() %>% # ponownie grupujemy po obszarach group_by(id, group, piece, hole) %>% # i nadajemy nowy porządek pozostałym punktom mutate(order = row_number()) %>% ungroup() |
Zmniejszyliśmy wielkość danych około 24 razy! Jeśli to za mało – można zaokrąglić dokładność współrzędnych do 3 miejsc po przecinku.
Zobaczmy czy mapa gmin wygląda sensownie?
|
1 2 3 4 |
gminy_mapa_small %>% ggplot() + geom_polygon(aes(long, lat, group=group), fill = "white", color = "gray50") + coord_map() |

Cała Polska w podziale na gminy. Z wyjątkiem – Warszawa (i zdaje się, że inne duże miasta podobnie). Dzielnice niestety nie są dostępne w pliku gminy.shp, są w bodaj jednostki_ewidencyjne.shp. Olejemy to jednak ;)
A jeśli chcemy tylko wybrane województwo albo powiat? To taki hint na przyszłość, może będzie Wam do czegoś potrzebne – wystarczy tabelę z mapą wyfiltrować po początkowych znakach (dwóch dla województwa, czterech dla powiatu) i narysować tylko to. Weźmy województwo małopolskie (w tabelce kodów TERYT dla województw widzimy, że to kod 12), przy okazji innymi kolorami zaznaczając powiaty:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
gminy_mapa_small %>% # tylko województwo małopolskie filter(substr(id, 1, 2) == "12") %>% # wybieramy kawałek kodu TERYT do oznaczenia powiatu mutate(powiat = substr(id, 1, 4)) %>% # dodajemy nazwę powiatu z tabeli przygotowanej wcześniej left_join(powiaty, by = c("powiat" = "TERYT_POW")) %>% ggplot() + geom_polygon(aes(long, lat, group=group, fill = Powiat # kolor wypełnienia - nazwa powiatu w tabeli powiaty ), color = "gray50") + coord_map() |

Widać ząbki na granicach wynikające z zaokrągleń.
Mięso
Mamy już wszystko gotowe i możemy przystąpić do przygotowania odpowiedniej funkcji, która da nam odpowiednie dane dla wybranej gminy. Przygotujemy ją po kawałku, a na koniec opakujemy wszystkie kolejne kroki w funkcję.
Wybierzmy sobie gminę, którą będziemy analizować – niech taką gminą będzie Kraków (o kodzie TERYT = 1261011). Na początek przeanalizujemy skąd ludzie przybyli do Krakowa w 2016 roku?
|
1 2 |
gmina_TERYT <- "1261011" kierunek <- "to" |
Te dwie zmienne uczynimy później parametrami funkcji.
Wybieramy więc interesujące nas dane. Na początek nazwa gminy i województwo do którego należy. To będzie potrzebne do wykresów:
|
1 2 3 4 |
gmina_TERYT_name <- gminy %>% filter(TERYT == gmina_TERYT) %>% mutate(Nazwa = paste0(Nazwa_gminy, ", woj. ", Wojewodztwo)) %>% .$Nazwa |
Otrzymujemy wartość Kraków (gmina miejska), woj. MAŁOPOLSKIE czyli tak, jak chcieliśmy. Mała uwaga na marginesie: zamiast .$Nazwa można użyć funkcji pull(), ale dostępna jest ona w pakiecie dplyr w wersji powyżej 0.7. A że moje posty z różnych przyczyn piszę na R w wersji 3.2.1 to nie mogę na niej zainstalować nowszej wersji dplyr.
Wybierzmy z tabeli o migracjach tylko fragment danych, których potrzebujemy – skąd ludzie przyjeżdżają do naszej gminy?
|
1 2 3 4 5 6 7 |
if(kierunek == "to") { migracje_gmina <- migracje %>% filter(To_TERYT == gmina_TERYT) %>% select(TERYT = From_TERYT, Liczba_osob) plot_title <- paste0("Skąd przyjechali w 2016 roku ludzie do gminy\n", gmina_TERYT_name, "?") } |
Upakowane to w warunku if(), bo będzie gotowym fragmentem funkcji. Od razu przygotowaliśmy sobie tytuł do wykresów: Skąd przyjechali w 2016 roku ludzie do gminy Kraków (gmina miejska), woj. MAŁOPOLSKIE?
Teraz najważniejsza rzecz – dodać liczbę osób, które zmieniły miejsce zamieszkania do mapy.
|
1 |
migracje_mapa <- left_join(gminy_mapa_small, migracje_gmina, by = c("id" = "TERYT")) |
Możemy już narysować mapkę:
|
1 2 3 4 5 6 7 8 9 |
migracje_mapa %>% ggplot() + geom_polygon(aes(long, lat, group=group, fill = Liczba_osob), color = "gray80") + scale_fill_gradient(low = "darkred", high = "orange", na.value = "white") + coord_map() + labs(title = plot_title, subtitle = "Mapa gmin", x = "", y = "", fill = "Liczba osób, które zmieniły miejsce zameldowania") + theme(legend.position = "bottom") |
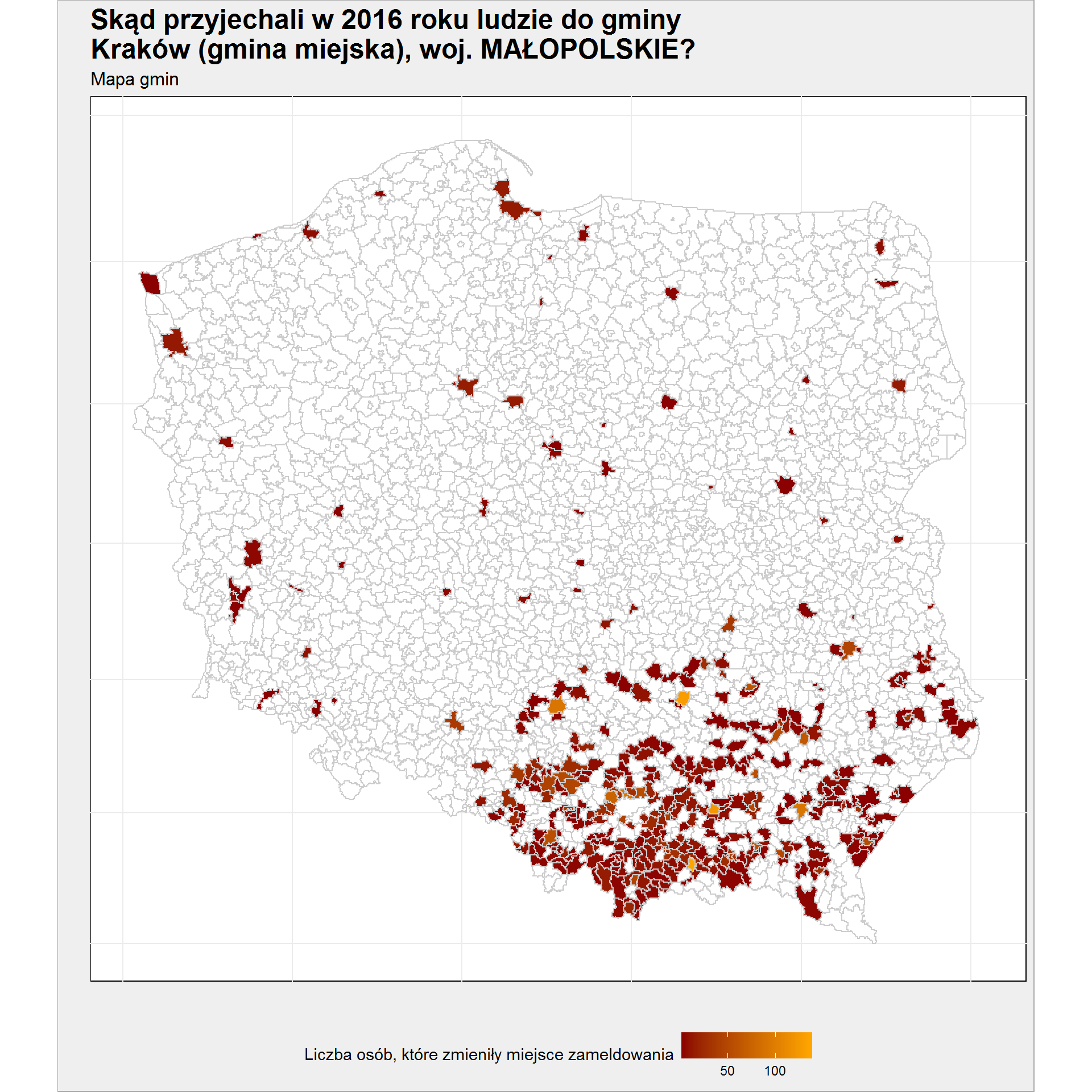
Widzimy, że głównie do Krakowa przyjeżdżają ludzie z jego okolic. To oczywiście naturalne. Ale są pojedyncze gminy z drugiego krańca Polski.
W tym miejscu właściwie kończy się część, o którą często pytacie. Zamiast liczby osób, które zmieniły miejsce zamieszkania może być liczba sprzedanych lizaków, liczba kontaktów z klientami i cokolwiek zechcecie. Rozwiązanie jest uniwersalne i przebiega według algorytmu:
- dane przygotowujemy w tabeli z dwoma kolumnami: kod TERYT jednostki oraz wartość którą chcemy pokazać na mapie
- w zależności od poziomu danych (gmina, powiat, województwo) przygotowujemy odpowiednią mapę (z pliku SHP)
- łączymy (left_join()) mapę z danymi według klucza TERYT
- rysujemy (ggplot() + geom_polygon()) całość używając do wypełnienia konturów naszej wartości
Możemy z poziomu gmin agregować dane do wyższych poziomów – powiatów lub województw. I znowu narysować je na odpowiedniej mapie. My jednak przygotujemy innego rodzaju wykresy.
Na początek dodamy do informacji o migracjach do Krakowa nazwy gmin, powiatów i województw:
|
1 |
migracje_gmina <- migracje_gmina %>% left_join(gminy, by = c("TERYT" = "TERYT")) |
Zobaczmy top 20 gmin skąd przybyli nowi mieszkańcy Krakowa (według liczby osób, które zmieniły miejsce zamieszkania):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
migracje_gmina %>% top_n(20, Liczba_osob) %>% arrange(Liczba_osob) %>% mutate(Nazwa_gminy = factor(Nazwa_gminy, levels = Nazwa_gminy)) %>% mutate(pow_woj = paste0(Powiat, " (", tolower(Wojewodztwo), ")")) %>% ggplot() + geom_col(aes(Nazwa_gminy, Liczba_osob, fill = as.factor(pow_woj))) + coord_flip() + labs(title = plot_title, subtitle = "Dwadzieścia najpopularniejszych gmin", x = "", y = "Liczba osób, które zmieniły miejsce zameldowania", fill = "Powiat (województwo)") + theme_minimal() |
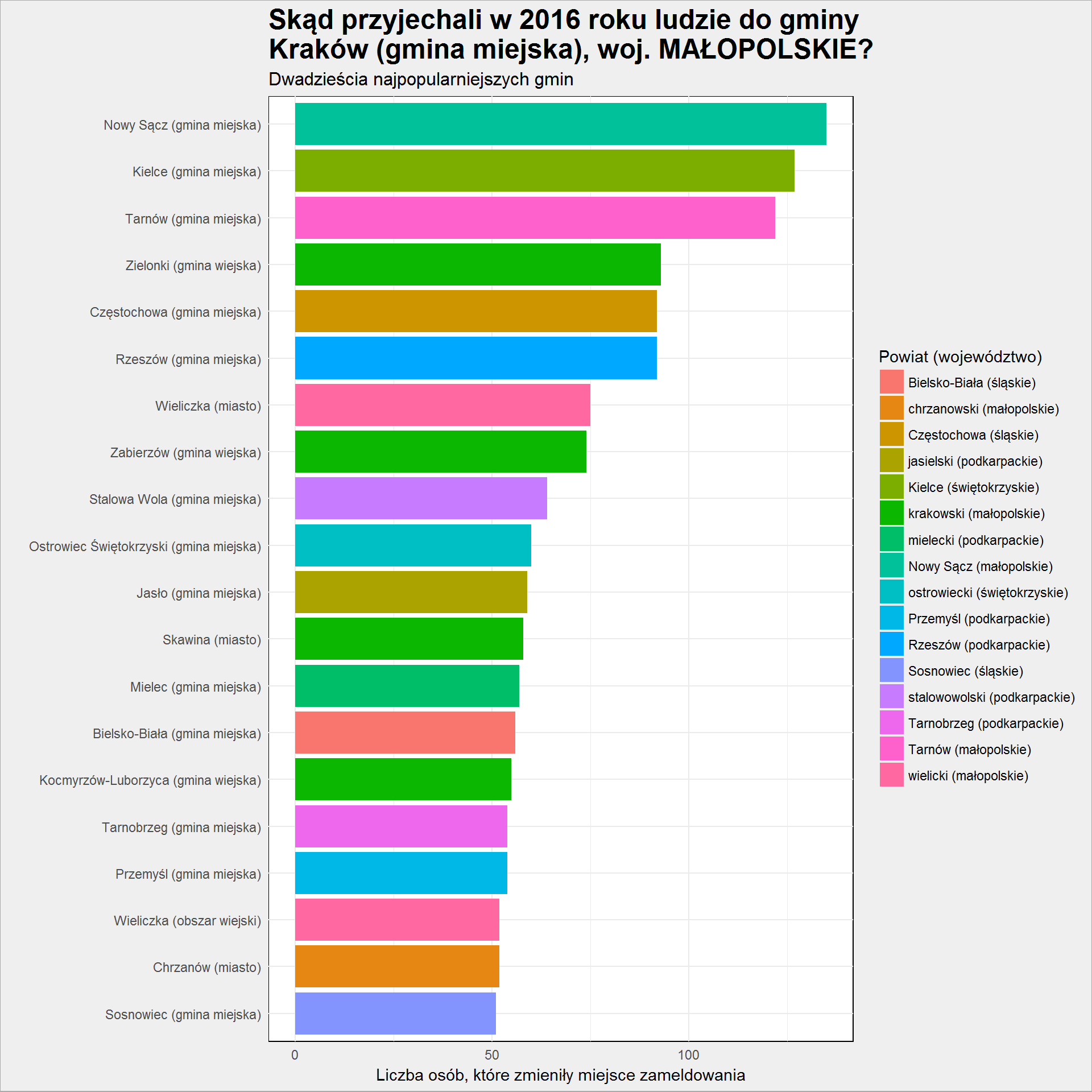
Dominują duże miejscowości w okolicach Krakowa: Nowy Sącz i Tarnów. Spodziewam się, że z tych miast (a także z Kielc i Częstochowy) przyjeżdżają studenci i po zakończeniu studiów osiedlają się na stałe. Na mapie widzieliśmy dużo gmin, a tutaj ich prawie nie widać. To dlatego, że bierzemy pod uwagę bezwzględną liczbę mieszkańców.
Gdybyśmy policzyli jaki procent na przykład mieszkańców Kielc wyemigrował do Krakowa układ powyższych słupków byłby zapewne inny. Bo przecież 20 osób z gminy liczącej 3 tysiące mieszkańców (0.66%) to co innego niż 100 osób ze 100-tysięcznego miasta (0.1%). Ale do tego potrzebowalibyśmy jeszcze jednej warstwy danych – liczby mieszkańców każdej z gmin w tym samym czasie (czyli na przykład na koniec 2015 roku), a tutaj od ręki mamy dane na poziomie powiatów (dla zainteresowanych: znowu baza Demografia ścieżka dotarcia to: I. STAN I STRUKTURA LUDNOŚCI, Ludność, 2015, Ludność stan w dniu 31 XII, 03 – Ludność według płci, województw i powiatów, Ogólnopolskie) lub dane na poziomie gmin z Narodowego Spisu Powszechnego, ale z 2011 roku (link) w nieco trudniejszym formacie (każde województwo w innej zakładce) i trochę mniej wprost (nie ma rozbicia po kodach TERYT na obszar wiejski i miejski gmin wiejsko-miejskich – jest całość, a rozbicie trzeba sobie wykoncypować samodzielnie z podziału na ludność zamieszkującą część miejską i wiejską). “Rabialne” w każdym razie.
Wróćmy do naszych migracji. Wiemy już z jakich gmin przyjechali nowi (jak na rok 2016) mieszkańcy Krakowa, a teraz zagregujmy to do powiatów (i pokażmy top 20):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
pow_table <- migracje_gmina %>% group_by(Powiat, Wojewodztwo) %>% summarise(Liczba_osob = sum(Liczba_osob)) %>% ungroup() %>% arrange(desc(Liczba_osob)) pow_table %>% top_n(20, Liczba_osob) %>% arrange(Liczba_osob) %>% mutate(Powiat = factor(Powiat, levels = Powiat)) %>% ggplot() + geom_col(aes(Powiat, Liczba_osob, fill = Wojewodztwo)) + coord_flip() |
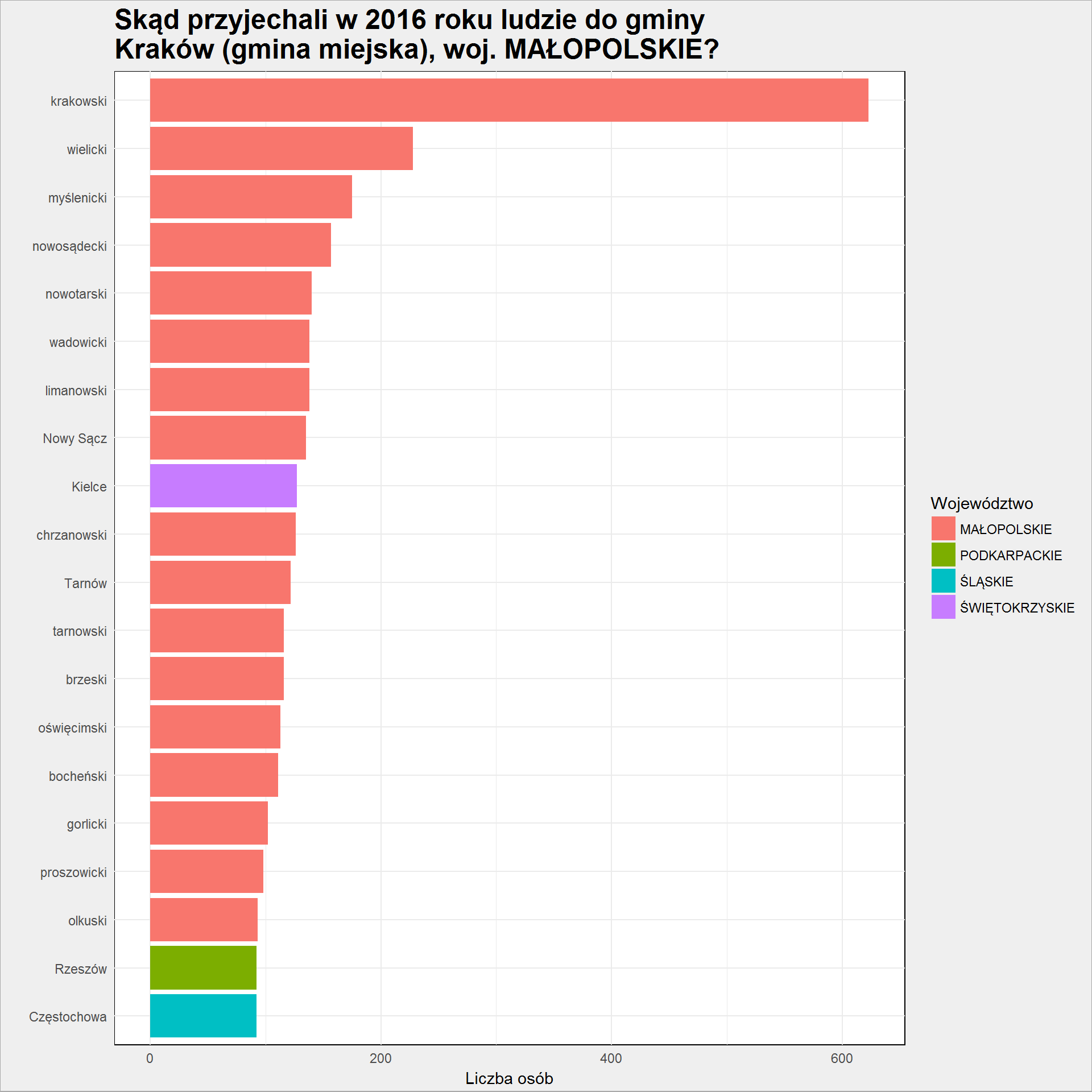
i województw (agregując powiaty):
|
1 2 3 4 5 6 7 8 9 10 11 12 |
woj_table <- pow_table %>% group_by(Wojewodztwo) %>% summarise(Liczba_osob = sum(Liczba_osob)) %>% ungroup() %>% arrange(desc(Liczba_osob)) woj_table %>% arrange(Liczba_osob) %>% mutate(Wojewodztwo = factor(Wojewodztwo, levels = Wojewodztwo)) %>% ggplot() + geom_col(aes(Wojewodztwo, Liczba_osob, fill = Wojewodztwo), show.legend = FALSE) + coord_flip() |
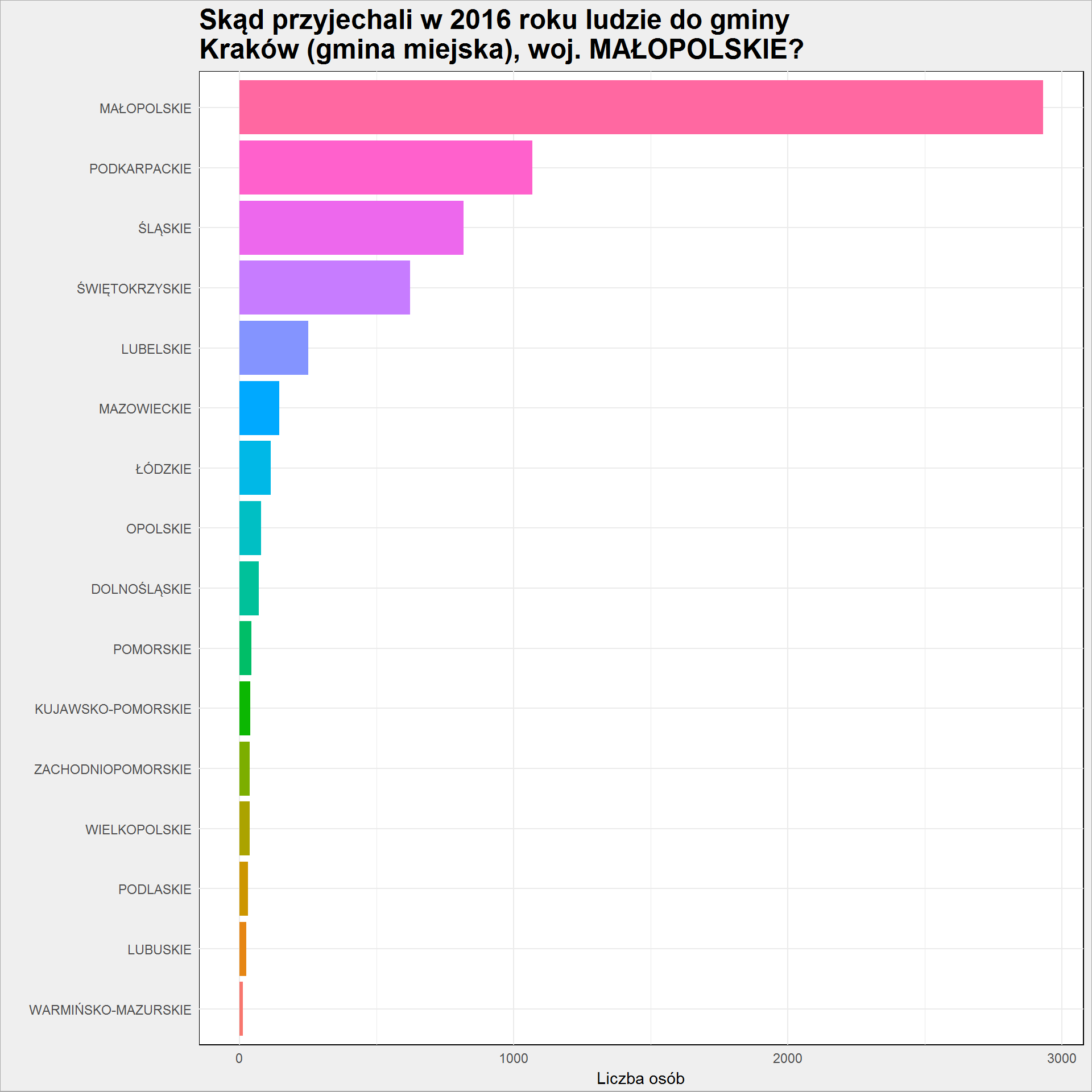
Już na mapie widzieliśmy, że najwięcej przybyszy jest z okolic Krakowa, z województwa małopolskiego. Co więcej – z powiatu krakowskiego.
Chcecie zobaczyć co to za powiat, jakie gminy i ile ludzi przybyło z niego do miasta królewskiego? Jasne, że tak! Powiat krakowski to kod TERYT:
|
1 |
powiaty %>% filter(Powiat == "krakowski") |
| WOJ | POW | Powiat | TERYT_POW |
|---|---|---|---|
| 12 | 06 | krakowski | 1206 |
Zawęzimy więc do niego dane z mapą:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
migracje_mapa %>% # tylko jeden powiat + Kraków filter(substr(id, 1, 4) == "1206" | id == gmina_TERYT) %>% # dodajmy środek gminy - tam umieścimy jej nazwę group_by(id) %>% mutate(mlong = mean(long), mlat = mean(lat)) %>% ungroup() %>% # dodajmy nazwę gminy left_join(gminy, by = c("id" = "TERYT")) %>% # "złamanie" linii mutate(Nazwa_gminy = gsub(" (", "\n(", Nazwa_gminy, fixed = TRUE)) %>% ggplot() + geom_polygon(aes(long, lat, group=group, fill = Liczba_osob), color = "gray50") + geom_text(aes(mlong, mlat, label = Nazwa_gminy), size = 4, color = "black") + coord_map() + scale_fill_gradient(low = "orange", high = "yellow", na.value = "gray90") |
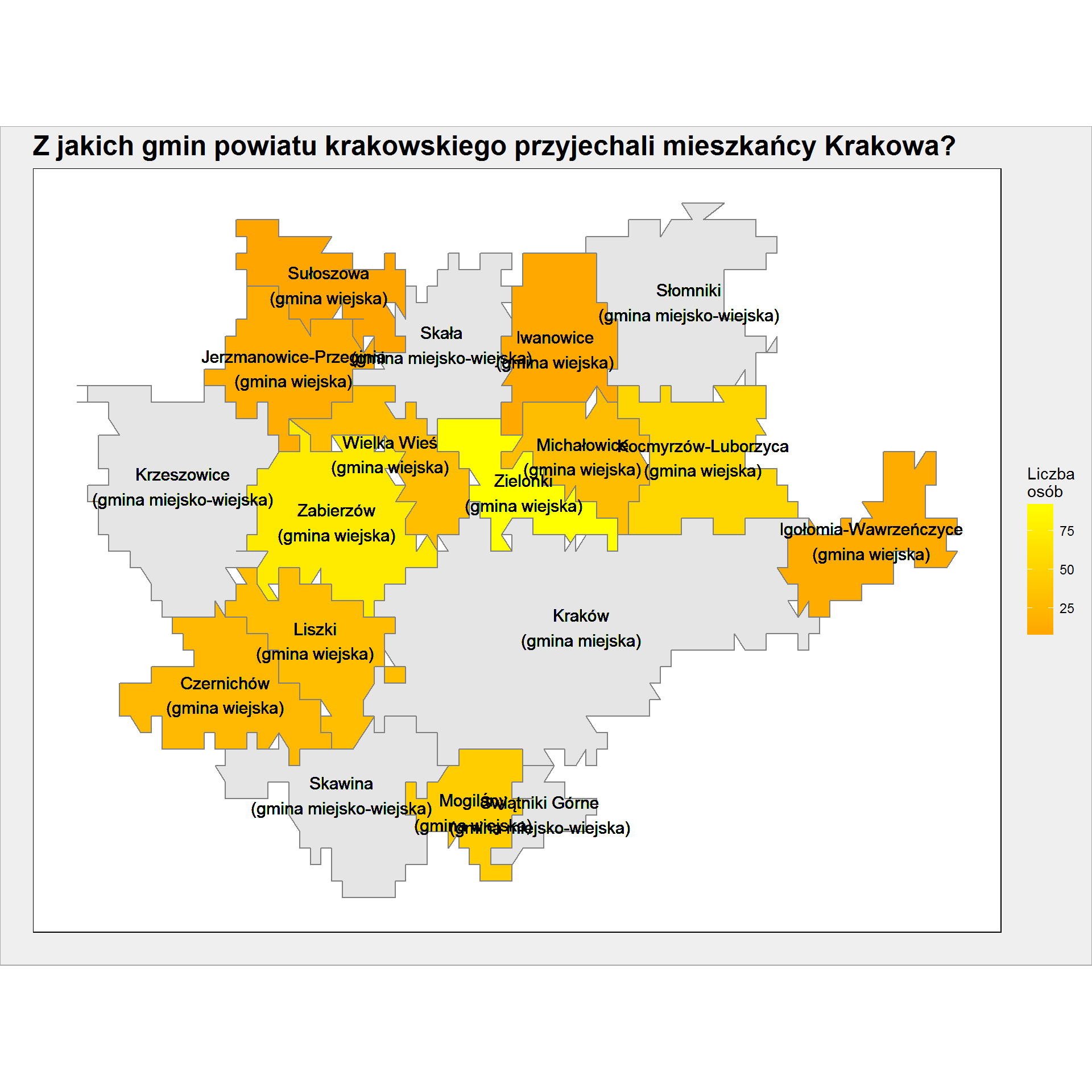
Widać kanciastość granic gmin (to wynik zaokrąglenia współrzędnych przy przygotowaniu mapy), ale widać też dokładnie z której gminy w sąsiedztwie Krakowa przybyli mieszkańcy (Zielonki, Zabierzów i Kocmyrzów-Luborzyca to pierwsza trójka).
Teraz to samo zrobimy dla kierunku odwrotnego. Zmianie podlega tylko jeden fragment: określający tytuł wykresu oraz wybierający odpowiednio dane z tabeli o wszystkich migracjach. Dodamy po prostu kolejny warunek:
|
1 2 3 4 5 6 7 |
if(kierunek == "from") { migracje_gmina <- migracje %>% filter(From_TERYT == gmina_TERYT) %>% select(TERYT = To_TERYT, Liczba_osob) plot_title <- paste("Dokąd wyjechali w 2016 roku ludzie z gminy", gmina_TERYT_name, "?") } |
Usuńmy jeszcze zbędne zmienne (poskładamy kod z tymi samymi nazwami zmiennych, chodzi o to, żeby nie pomieszały się (głównie w głowie) zmienne lokalne z globalnymi):
|
1 |
rm(gmina_TERYT, gmina_TERYT_name, kierunek, migracje_gmina, migracje_mapa, plot_title, pow_table, woj_table) |
Teraz całość możemy upakować w jedną funkcję, która na podanie kodu TERYT badanej gminy i kierunku zmian zwróci nam w liście wszystkie interesujące nas informacje:
- mapę Polski z odpowiednio pokolorowanymi gminami
- wykres słupkowy z dwudziestoma gminami z których przybyło (lub do których wyjechało) najwięcej osób
- tabelę z danymi zagregowanymi do powiatów
- tabelę z agregacją do województw
Oto cały kod:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
Migration <- function(gmina_TERYT, kierunek) { gmina_TERYT_name <- gminy %>% filter(TERYT == gmina_TERYT) %>% mutate(Nazwa = paste0(Nazwa_gminy, ", woj. ", Wojewodztwo)) %>% .$Nazwa # bez ruchu wewątrz gminy - przy dużych miastach i migracjach dzielnica-dzielnica wprowadza to zamieszanie migracje_gminy <- migracje %>% filter(To_TERYT != From_TERYT) if(kierunek == "to") { migracje_gminy <- migracje_gminy %>% filter(To_TERYT == gmina_TERYT) %>% select(TERYT = From_TERYT, Liczba_osob) plot_title <- paste("Skąd przyjechali w 2016 roku ludzie do gminy\n", gmina_TERYT_name, "?") } if(kierunek == "from") { migracje_gminy <- migracje_gminy %>% filter(From_TERYT == gmina_TERYT) %>% select(TERYT = To_TERYT, Liczba_osob) plot_title <- paste("Dokąd wyjechali w 2016 roku ludzie z gminy\n", gmina_TERYT_name, "?") } migracje_mapa <- left_join(gminy_mapa_small, migracje_gminy, by = c("id" = "TERYT")) migracje_gminy <- migracje_gminy %>% left_join(gminy, by = c("TERYT" = "TERYT")) # słupki z 20 najpopularniejszymi gminami barplot <- migracje_gminy %>% top_n(20, Liczba_osob) %>% arrange(Liczba_osob) %>% mutate(Nazwa_gminy = factor(Nazwa_gminy, levels = Nazwa_gminy)) %>% mutate(pow_woj = paste0(Powiat, " (", tolower(Wojewodztwo), ")")) %>% ggplot() + geom_col(aes(Nazwa_gminy, Liczba_osob, fill = as.factor(pow_woj))) + coord_flip() + labs(title = plot_title, subtitle = "Dwadzieścia najpopularniejszych gmin", x = "", y = "Liczba osób, które zmieniły miejsce zameldowania", fill = "Powiat (województwo)") # mapa map <- migracje_mapa %>% ggplot() + geom_polygon(aes(long, lat, group=group, fill = Liczba_osob), color = "gray80") + scale_fill_gradient(low = "darkred", high = "orange", na.value = "white") + coord_map() + labs(title = plot_title, subtitle = "Mapa gmin", x = "", y = "", fill = "Liczba osób, które zmieniły miejsce zameldowania") + theme(legend.position = "bottom") # powiaty pow_table <- migracje_gminy %>% group_by(Powiat, Wojewodztwo) %>% summarise(Liczba_osob = sum(Liczba_osob)) %>% ungroup() %>% arrange(desc(Liczba_osob)) # wojewodztwa woj_table <- pow_table %>% group_by(Wojewodztwo) %>% summarise(Liczba_osob = sum(Liczba_osob)) %>% ungroup() %>% arrange(desc(Liczba_osob)) return(list(map = map, bar = barplot, pow = pow_table, woj = woj_table)) } |
Sprawdźmy czy wszystko działa poprawnie dla naszego Krakowa (w kierunku jaki wyżej przeanalizowaliśmy) – na przykład na top 20 powiatów:
|
1 |
Migration("1261011", "to")$pow %>% top_n(20, Liczba_osob) |
| Powiat | Wojewodztwo | Liczba_osob |
|---|---|---|
| krakowski | MAŁOPOLSKIE | 623 |
| wielicki | MAŁOPOLSKIE | 228 |
| myślenicki | MAŁOPOLSKIE | 175 |
| nowosądecki | MAŁOPOLSKIE | 157 |
| nowotarski | MAŁOPOLSKIE | 140 |
| limanowski | MAŁOPOLSKIE | 138 |
| wadowicki | MAŁOPOLSKIE | 138 |
| Nowy Sącz | MAŁOPOLSKIE | 135 |
| Kielce | ŚWIĘTOKRZYSKIE | 127 |
| chrzanowski | MAŁOPOLSKIE | 126 |
| Tarnów | MAŁOPOLSKIE | 122 |
| brzeski | MAŁOPOLSKIE | 116 |
| tarnowski | MAŁOPOLSKIE | 116 |
| oświęcimski | MAŁOPOLSKIE | 113 |
| bocheński | MAŁOPOLSKIE | 111 |
| gorlicki | MAŁOPOLSKIE | 102 |
| proszowicki | MAŁOPOLSKIE | 98 |
| olkuski | MAŁOPOLSKIE | 93 |
| Częstochowa | ŚLĄSKIE | 92 |
| Rzeszów | PODKARPACKIE | 92 |
Porównaj teraz tabelę z odpowiednim wykresem wyżej. Musi się zgadzać, a ewentualna zamiana Częstochowy z Rzeszowem jest nieistotna, bo liczba osób w obu przypadkach jest jednakowa.
Porównajmy jednak dwie liczby w obu kierunkach. Powyżej w tabeli mamy 623 osób, które przeprowadziły się z powiatu krakowskiego do Krakowa. A w drugą stronę? Możemy już korzystać z naszej funkcji, zatem:
|
1 |
Migration("1261011", "from")$pow %>% top_n(10, Liczba_osob) |
| Powiat | Wojewodztwo | Liczba_osob |
|---|---|---|
| krakowski | MAŁOPOLSKIE | 1796 |
| wielicki | MAŁOPOLSKIE | 1026 |
| myślenicki | MAŁOPOLSKIE | 265 |
| Warszawa | MAZOWIECKIE | 241 |
| bocheński | MAŁOPOLSKIE | 131 |
| wadowicki | MAŁOPOLSKIE | 104 |
| proszowicki | MAŁOPOLSKIE | 87 |
| limanowski | MAŁOPOLSKIE | 75 |
| Tarnów | MAŁOPOLSKIE | 66 |
| brzeski | MAŁOPOLSKIE | 53 |
Jak widać jest to 1796 osób! Ludzie migrują z dużych miast na przedmieścia. To samo jest w przypadku Wrocławia i Poznania.
Chcielibyście pewnie wiedzieć ile osób z okolic Łukowa (z rejestracją LLU) trafiło do Warszawy? Dane mamy na poziomie gmin (i co za tym idzie – dzielnic Warszawy), w związku z tym musimy użyć powiatu. Wszystkie gminy Warszawy mają kod TERYT zaczynający się od 1465. Powiat łukowski to zaś 0611. Chwilka na przygotowanie kodu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
migracje %>% # do Warszawy filter(substr(To_TERYT, 1, 4) == "1465") %>% # z powiatu łukowskiego filter(substr(From_TERYT, 1, 4) == "0611") %>% # dodajmy nazwy dzielnic left_join(gminy, by = c("To_TERYT" = "TERYT")) %>% # ludzie mogli być z różnych gmin w powiecie łukowskim - musimy to zagregować group_by(Nazwa_gminy) %>% summarise(Liczba_osob = sum(Liczba_osob)) %>% ungroup() %>% # posortujmy wynik arrange(desc(Liczba_osob)) %>% # policzmy % dla każdej z dzielnicy mutate(Procent = 100*Liczba_osob/sum(Liczba_osob)) |
| Nazwa_gminy | Liczba_osob | Procent |
|---|---|---|
| Białołęka (dzielnica Warszawy) | 20 | 13.4 |
| Wola (dzielnica Warszawy) | 18 | 12.1 |
| Targówek (dzielnica Warszawy) | 17 | 11.4 |
| Mokotów (dzielnica Warszawy) | 15 | 10.1 |
| Praga-Południe (dzielnica Warszawy) | 15 | 10.1 |
| Ursynów (dzielnica Warszawy) | 10 | 6.7 |
| Wawer (dzielnica Warszawy) | 10 | 6.7 |
| Wilanów (dzielnica Warszawy) | 10 | 6.7 |
| Bielany (dzielnica Warszawy) | 8 | 5.4 |
| Bemowo (dzielnica Warszawy) | 7 | 4.7 |
| Śródmieście (dzielnica Warszawy) | 7 | 4.7 |
| Włochy (dzielnica Warszawy) | 5 | 3.4 |
| Ursus (dzielnica Warszawy) | 4 | 2.7 |
| Żoliborz (dzielnica Warszawy) | 3 | 2.0 |
Rzeczywiście najwięcej trafiło na Białołękę (zgodnie z obiegową opinią). Ale nie jest to jakaś dramatyczna różnica.
Teraz pewnie chcesz zobaczyć skąd pochodzą mieszkańcy Twojej gminy? Albo chcesz zobaczyć dokąd emigrują? Narzędzia są gotowe. A w drugiej części przygotujemy aplikację do tego (w imię “There’s an app for this!”).
niewiele wiedząc o R próbowałem wyrysować to co pokazujesz idąc krok po kroku za twoją instrukcją i w tym miejscu napotykam błąd, którego nie potrafię usunąć,
> gminy_mapa <- tidy(gminy_mapa, region = "jpt_kod_je")
BŁĄD: isTRUE(gpclibPermitStatus()) is not TRUE
gdy go zignorowałem i poszedłem dalej tzn próbowałem zastosować kolejną porcję kodu to wyskakuje błąd
niestosowalna metoda dla 'group_by_' zastosowana do obiektu klasy "c('SpatialPolygonsDataFrame', 'SpatialPolygons', 'Spatial')"
jakiś pomysł?
To problem, który da się ominąć instalując na nowo pakiety:
install.packages('rgeos', type='source')install.packages('rgdal', type='source')
kurcze, nie wiem czemu spodziewalem sie jakiegos powiadomienia na maila, jak odpowiesz, a że go nie było, to mordowałem się sam i w końcu znalazłem to samo rozwiązanie o którym piszesz:)
mimo to oczywiscie wielkie dzieki, a caly material bardzo ciekawy
Właśnie dodałem plugin do powiadomień o komciach.
Pingback: Migracje Polaków w 2016 roku - aplikacja | Łukasz Prokulski
Hej,
super materiał.
Staram się odtworzyć i utknąłem na etapie instrukcji
gminy_mapa <- readOGR("../!mapy_shp/gminy.shp", layer = "gminy")
Plik z COIGDK zgrałem, gminy.shp jest (84mb). I niestety cały czas mam komunikat
Error in ogrInfo(dsn = dsn, layer = layer, encoding = encoding, use_iconv = use_iconv, :
Cannot open data source
Pewnie jakiś głupi błąd. Ale nie mam pojęcia jaki. Będę wdzięczny za wskazówkę.
M
ps. biblioteka (rgdal) i ścieżka do pliku zaktualizowana… :)
Masz sam plik .shp czy wszystkie gminy.*? Bo to może być problem. Jeśli oczywiście ścieżka do pliku jest poprawna (a obstawiam że to jest problem).