Czy granice państw europejskich są wyznaczone poprawnie?
Jak wyglądałyby gdyby użyć algorytmów?
Tak zrobimy – sprawdzimy jak algorytm k-średnich “rozdzieli” na poszczególne kraje miasta biorąc pod uwagę ich położenie geograficzne. I zobaczymy co się stanie jak w Europie będzie mniej państw (oczywiście hipotetycznie, oczywiście na podstawie algorytmu, a nie wojny o ziemię).
Trochę o algorytmach pisałem już wcześniej, tutaj użyjemy najprostszego z algorytmów – k-średnich. Metoda będzie prosta – dla każdego miasta znajdziemy jego współrzędne, później na podstawie współrzędnych dokonamy klasyfikacji do nowych grup. Na początek tej samej ilości grup (państw) jaką mamy obecnie – sprawdzimy czy granice są “odpowiednie”. Później będziemy zmniejszać ilość “nowych państw”.
Przygotowanie danych
Najtrudniejszym zadaniem okazało się znalezienie dużej listy europejskich miast. Im ich więcej tym lepsze będziemy mieć wyniki.
Z pomocą przychodzi Wikipedia, gdzie taka lista istnieje – z niej skorzystamy. Pobieramy dane z Wiki:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
library(rvest) library(dplyr) library(ggplot2) library(ggmap) # tabelka z wikipedii wiki_page <- read_html("https://en.wikipedia.org/wiki/List_of_cities_in_the_European_Union_by_population_within_city_limits") EU_cities <- wiki_page %>% html_node("table") %>% html_table() # interesują nast tylko dwie kolumny - nazwa miasta i kraju EU_cities <- EU_cities[, 2:3] # usuwamy śmieci z nazw EU_cities <- EU_cities %>% rename(City = City, Country = State) %>% mutate(City = gsub("\\[.+\\]", "", City)) %>% mutate(City = gsub("^[[:blank:]]", "", City)) %>% mutate(City = gsub("[[:blank:]]$", "", City)) %>% mutate(Country = gsub("^[[:blank:]]", "", Country)) %>% mutate(Country = gsub("[[:blank:]]$", "", Country)) |
Dzięki Google Maps API (za pośrednictwem ggmap() z pakietu ggmap) znajdziemy współrzędnie miasta. Tym razem nie w pętli, a z wykorzystaniem funkcji z rodziny apply. Te współrzędne scalimy z nazwami miast w jedną tabelę.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# współrzędne z GoogleMaps GetLongLat <- function(string) { t <- geocode(string) return(c(t["lon"], t["lat"])) } EU_cities_cord <- t(sapply(paste(EU_cities$City, EU_cities$Country, sep = ", "), GetLongLat)) # złącz dane z nazwami miast EU_cities_cord <- as.data.frame(EU_cities_cord) EU_cities <- cbind(EU_cities, EU_cities_cord) EU_cities$lon <- as.numeric(EU_cities$lon) EU_cities$lat <- as.numeric(EU_cities$lat) |
Tym sposobem mamy trochę danych. Trochę to mało, więc wykorzystałem listę miast znalezioną na stronie CityMayors – jest ich tam o wiele więcej. Operację wyszukiwania współrzędnych wykonałem identycznie, wcześniej dane ze strony obrobiłem w excelu.
Po znalezieniu współrzędnych i usunięciu tych miast, dla których danych nie udało się znaleźć mamy 822 rekordów z miastami. Całkiem sporo. Fajnie byłoby mieć tak po 100-200 dla każdego kraju (ale pamiętać należy o ograniczeniach w liczbie zapytań do Google Maps API na dobę!).
Państwa Europy
Możemy narysować sobie mapkę tych miast. Żeby było łatwiej przyporządkować miasto do państwa przydałyby się kontury państw. Te znajdziemy w bibliotece rworldmap.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
library(rworldmap) # mapa świata worldMap <- getMap() # tylko Europa EU_map <- worldMap[which(worldMap$REGION=="Europe"), ] # spatial -> data.frame EU_map <- fortify(EU_map) # wykluczamy Grenlandię i okolice Izraela (dlaczego to jest w Europie?) EU_map <- EU_map %>% filter(!id %in% c("Greenland", "Israel", "West Bank", "Gaza")) |
Tak wygląda pusta mapa Europy z zaznaczonymi poszczególnymi państwami:
|
1 2 3 4 5 |
ggplot(EU_map) + geom_polygon(aes(long, lat, group=group, fill=id), color="black") + coord_map(xlim = c(-25, 50), ylim = c(30, 73)) + theme_minimal() + theme(legend.position = "none") |
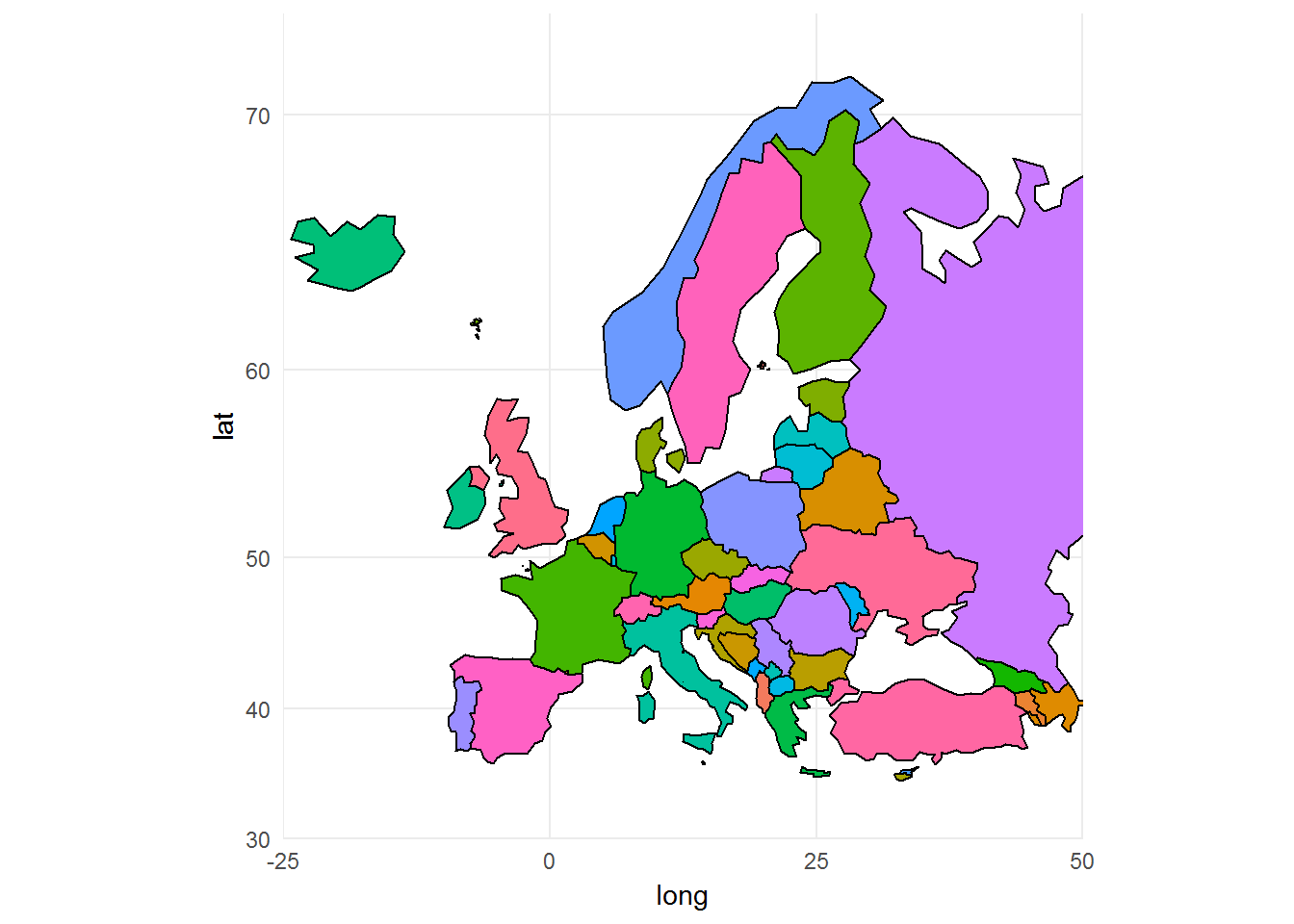
Zaznaczmy na niej miasta – oczywiście jako kolejna warstwa (geom_point).
|
1 2 3 4 5 6 7 8 |
p_before <- ggplot() + geom_polygon(data = EU_map, aes(long, lat, group=group), fill=NA, color="black") + geom_point(data = EU_cities, aes(lon, lat, color=Country, l1=City)) + scale_color_manual(values = rainbow(length(unique(EU_cities$Country)))) + coord_map(xlim = c(-25, 50), ylim = c(30, 73)) + theme_void() + theme(legend.position = "none") |
Dla uważnych czytelników kodu – nie ma czegoś takiego jak parametr l1, ale przyda nam się on w “dymkach” w mapce interaktywnej, wykonanej z użyciem pakietu plotly i wbudowanych weń bibliotek JavaScript. Polecam zapoznanie się z plot.ly, nie tylko w związku z R. Do interaktywnych wykresów jak znalazł. Do map warto jeszcze poznać leaflet.
Miasta Europy
|
1 2 3 |
library(plotly) ggplotly(p_before) |
Najedź myszą na poszczególne punkty na mapie powyżej. Bajer, co? Jedną linijką kodu w R.
Nowa Europa
Czas na zdefiniowanie granic Europy na nowo. Na początek – niech “nowych” państw będzie tyle ile mamy obecnie (czyli 29).
|
1 2 3 4 5 6 7 8 |
# ile państw? k_means <- length(unique(EU_cities$Country)) # klasyfikacja k-means na podstawie współrzędnych EU_cities$Country_knn <- kmeans(EU_cities[,3:4], k_means)$cluster # as.factor() żeby skala kolorów była kategoryczna a nie ciągła EU_cities$Country_knn <- as.factor(EU_cities$Country_knn) |
Już właściwie mamy co trzeba. Ale spróbujmy “nowym krajom” nadać jakieś nazwy. Dla uproszczenia – na podstawie obecnych nazw. Metoda jest następująca:
- podziel miasta na grupy według “nowych krajów”
- do którego ze starych krajów należy ich najwięcej w ramach grupy?
- taką nazwę nadaj nowemu krajowi (grupie)
Wynik takiego działania znajdzie się w tabeli tmp, którą później dołączamy do tabelki z oryginalnymi danymi miast.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
tmp <- EU_cities %>% group_by(Country_knn, Country) %>% summarise(n=n()) %>% ungroup() %>% group_by(Country_knn) %>% mutate(p=n/sum(n)) %>% mutate(Country_knn_name=ifelse(p==max(p), Country, "")) %>% ungroup() %>% select(Country_knn, Country_knn_name) %>% filter(Country_knn_name!="") %>% unique() EU_cities_knn <- left_join(EU_cities, tmp, by="Country_knn") |
Teraz już możemy narysować wynik. I znowu – l1 i l2 służą tylko dla dymków wyplutych przez plotly.
|
1 2 3 4 5 6 7 8 9 10 11 |
p_after <- ggplot() + geom_polygon(data = EU_map, aes(long, lat, group=group), fill = NA, color = "black") + geom_point(data = EU_cities_knn, aes(lon, lat, color=Country_knn, l1=City, l2=Country_knn_name)) + scale_color_manual(values = rainbow(k_means)) + coord_map(xlim = c(-25, 50), ylim = c(30, 73)) + theme_void() + theme(legend.position = "none") ggplotly(p_after) |
I co widzimy?
- większe kraje – Niemcy, Francja, Hiszpania czy Wielka Brytania – zostały podzielone na kilka grup
- nieco mniejsze – na dwie – tak jest z Włochami
- Turcja zagarnęła Grecję, Półwysep Skandynawski podzielił się pomiędzy Norwegię i Finlandię
- Polska rozdzielona jest (linią Konin – Kielce – Przemyśl) na dwie części: północno-wschodnią z – uwaga, uwaga – Wilnem, oraz południową – aż po Wiedeń, Zagrzeb i Timisoarę. Nasze zachodnie ziemie (Szczecin, Poznań, Koszalin) przynależą do Niemiec. Widać zabory!
Nowa Europa – 15 państw
Teraz to samo zrobimy dla mniejszej liczby “nowych państw”. Zamiast 29 weźmy na przykład 15. Aby uzyskać poniższy wynik wystarczy wykonać ostatnie trzy bloki kodu zmieniając jedynie wartość zmiennej k_means.
W takim układzie (w porównaniu do wersji powyżej, nie aktualnej):
- Niemcy wchodzą na północ i właściwie likwidują Norwegię
- Finlandia odbija nam Wilno i okolice, Włosi Zagrzeb, ale nadal sięgamy daleko na południe
- Rumunia zajmuje Turkom tereny Grecji
- na Wyspach Brytyjskich Anglicy biorą wszystko, zajmując jeszcze dodatkowo francuski kawałek na kontynencie
Nowa Europa – 5 państw
No to jeszcze podział na pięć państw:
Wynik takiego podziału kontynentu pokazuje trochę historycznie mocne państwa:
- Anglicy – biorący całe Wyspy, pół Francji, całe Niderlandy
- Hiszpanie – biorący cały półwysep Iberyjski
- Niemcy – cały środek Europy, od Morza Północnego do Śródziemnego, z całymi właściwie Aplami. Mi przypomina to obszar faszyzmu – Hitlera i Mussoliniego przed drugą wojną światową…
- Turcy biorą Bałkany, Grecję i zatrzymują się gdzieś w Transylwanii, zatrzymani przez nas (ponownie ;)
- Polska zagarnia całą Europę środkowo-wschodnią i prawie cały Półwysep Skandynawski. Taki odwet za potop szwedzki ;)
Nowa Europa – Wschodnia i Zachodnia
I na koniec – rozbiór Europy na dwie części (trochę jak Wschód i Zachód) – czy tak wyjdzie?
Granica w połowie, co nie dziwi (połowa miast ma bliżej do środka na wschodzie, druga – na zachodzie), bo algorytm jest jednak prymitywny. Ciekawe jest tylko to, że ta wschodnia część została przypisana do Polski.
Trochę wyjaśnienia
Dlaczego wyszło tak, a nie inaczej? Dlaczego Polska tak dominuje mapę, skoro jesteśmy takim małym krajem (jakby nie było tak jest)?
Przyczyna leży oczywiście tylko i wyłącznie w algorytmie. W danych posiadamy stosunkowo dużo miast (pierwsza 10 państw wg liczby miast):
| Country | n |
|---|---|
| United Kingdom | 166 |
| Germany | 104 |
| France | 85 |
| Spain | 83 |
| Italy | 76 |
| Poland | 55 |
| Netherlands | 51 |
| Romania | 30 |
| Turkey | 26 |
| Portugal | 23 |
A jeśli weźmiemy tylko wschodnią część (od 15 południka na wschód) to już w ogóle dominujemy (pierwsza 5 państw):
| Country | n |
|---|---|
| Poland | 54 |
| Romania | 30 |
| Turkey | 26 |
| Bulgaria | 18 |
| Italy | 14 |
Algorytm szuka punktów skupienia – im więcej więc punktów w jednym obszarze tym większa szansa, że tam będzie punkt skupienia. A później – wkoło tego punktu zbierane są najbliższe punkty i tak powstaje przypisanie do odpowiedniej klasy. Dlatego ważne jest, aby wybrane punkty źródłowe były mniej więcej równomiernie rozłożone i najlepiej gdyby było ich tyle samo w każdej ze źródłowych klas.
Tutaj tego nie mamy. Mamy “nadreprezentację” Wielkiej Brytanii, Niemiec. Dużo blisko położonych miast w Hiszpanii, Polsce, we Włoszech czy Niderlandach. Jak widać “wygrywały” państwa “gęsto upakowane” miastami.
Ale przynać należy, że eksperyment jest ciekawy. Troszeczkę (delikatnie i na siłę) pokazuje też historyczne losy kontynentu. Ktoś powiedział, że matematyka nie jest ciekawa? Że jest nieprzydatna? Nawet historyk czy geograf może zobaczyć, że jest uniwersalna.
W jaki sposób przechowujesz dane do późniejszej analizy? Za każdym razem jak uruchamiam jakiś skrypt, pobieram dane z internetu. W tym przypadku to pół biedy, bo miast nie jest dużo, natomiast co gdy danych jest dużo więcej i nie można ich pobrać w w miarę rozsądnym czasie? Gdzie zapisywać dane, które potem będę porządkował pisząc skrypt w Pythonie/R? Baza SQL? Plik tekstowy?
Najczęściej w plikach .RDS, czasem w .csv jeśli coś chcę zrobić w excelu. Powoli przestawiam się mentalnie na bazę MySQL, ale w sumie na razie bardziej zbieram w niej dane (cron na serwerze coś pobierający i zapisujący do bazy). W dużej mierze chodzi o wygodę pracy – część robię w domu, a część w pracy z mocnym ograniczeniem sieci (portów itp) – pliki trzymane na jakimś SkyDrive na razie sprawdzają się najlepiej…