W ostatnich dwóch wpisach analizowaliśmy oceny książek na podstawie bazy z serwisu z recenzjami książek a także prowadziliśmy śledztwo polegające na szukaniu autora książki. Tym razem zajmiemy się twórczością jednej autorki.
Tą autorką będzie J.K. Rowling, autorka bestsellerowej serii o Harrym Potterze oraz kilku książek dla dorosłych wydanych pod pseudonimem Robert Galbraith.
Podobnie jak w poprzedniej części potrzebujemy książek w plikach tekstowych. Analizować będziemy angielskie wersje książek (ze względu na analizę wydźwięku – ang. sentiment. W przypadku języka polskiego trudno o słowniki tegoż wydźwięku). Na początek sprawdźmy jakie słowa w poszczególnych książkach są najbardziej popularne:
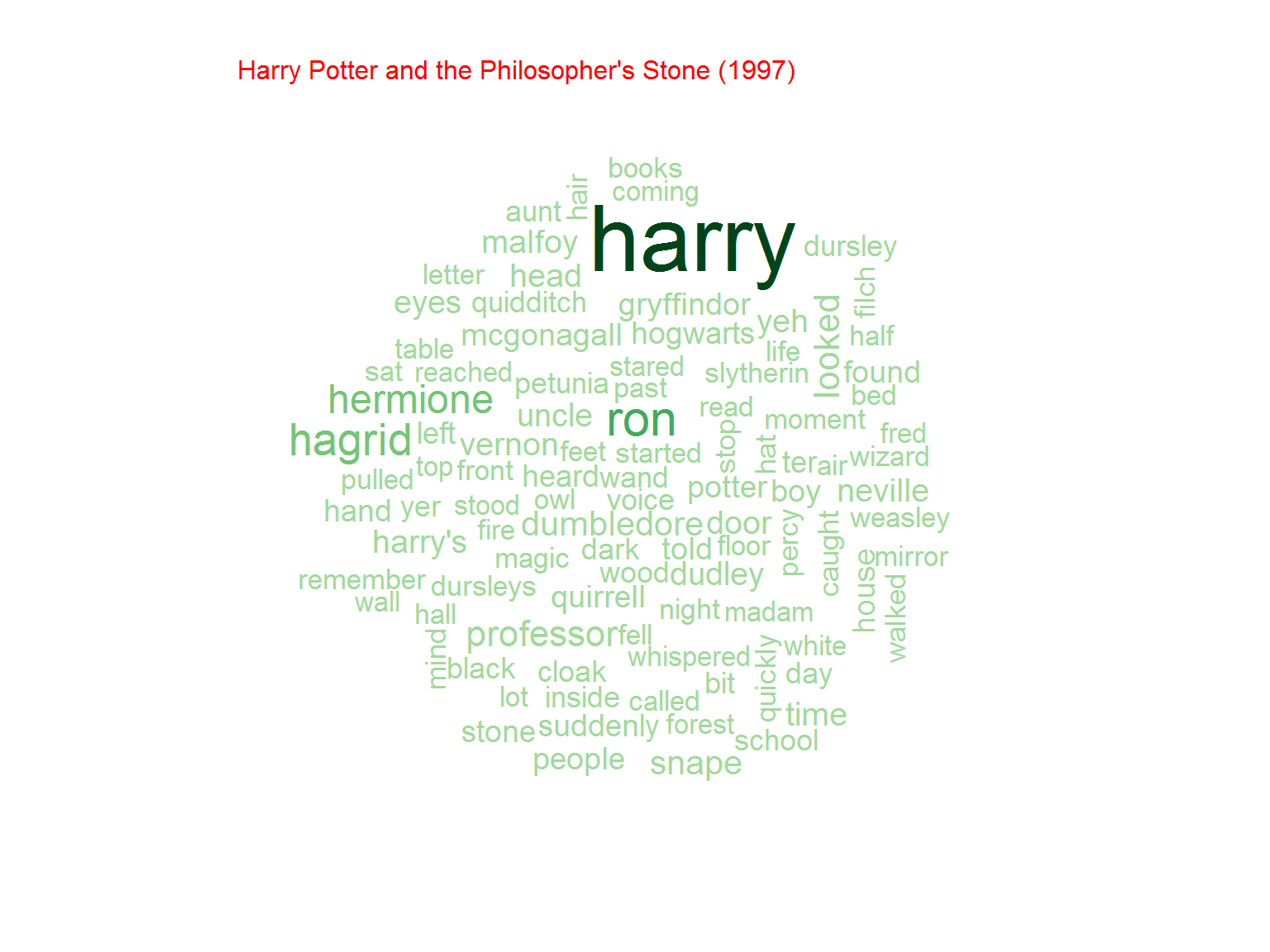
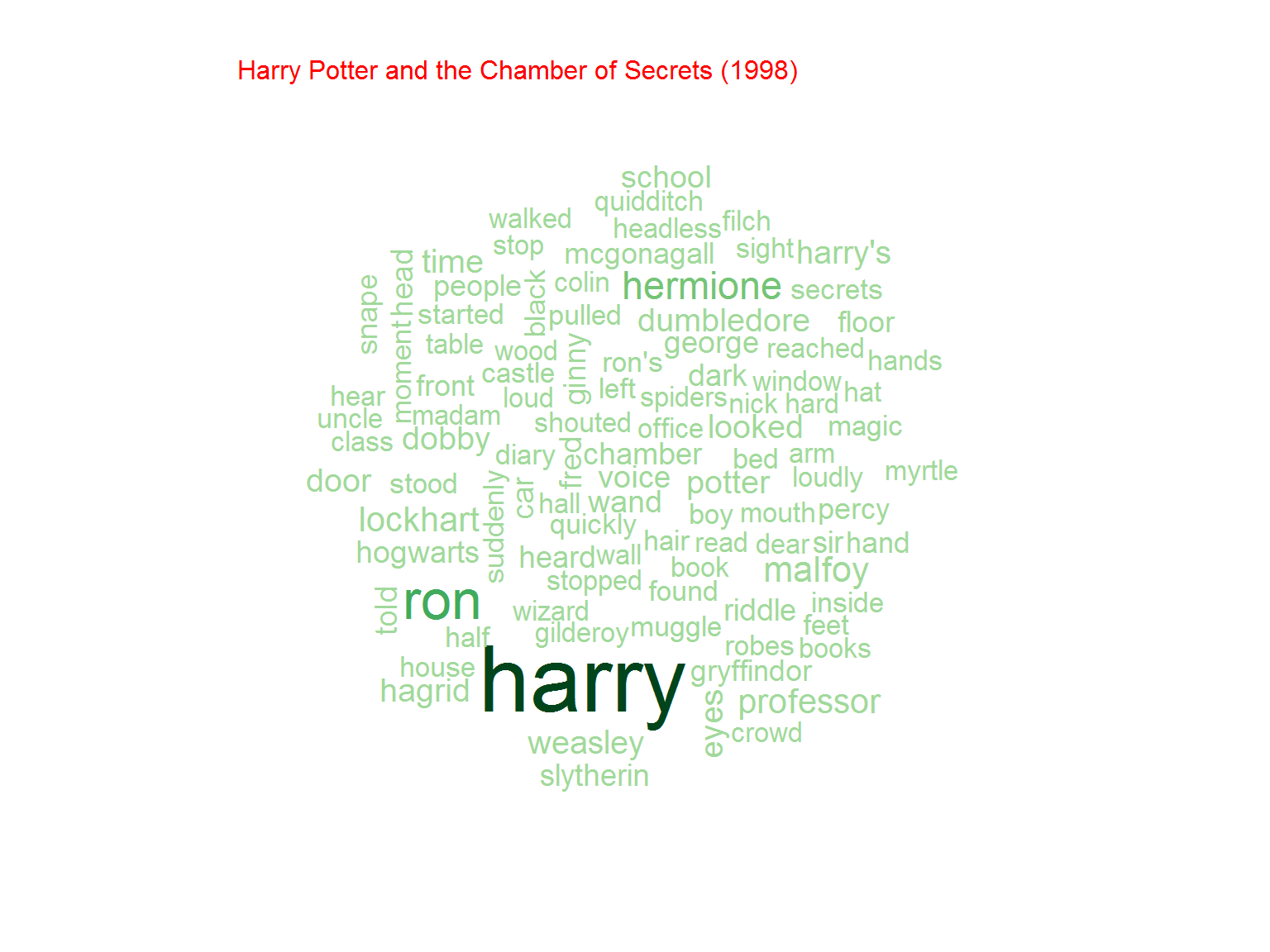
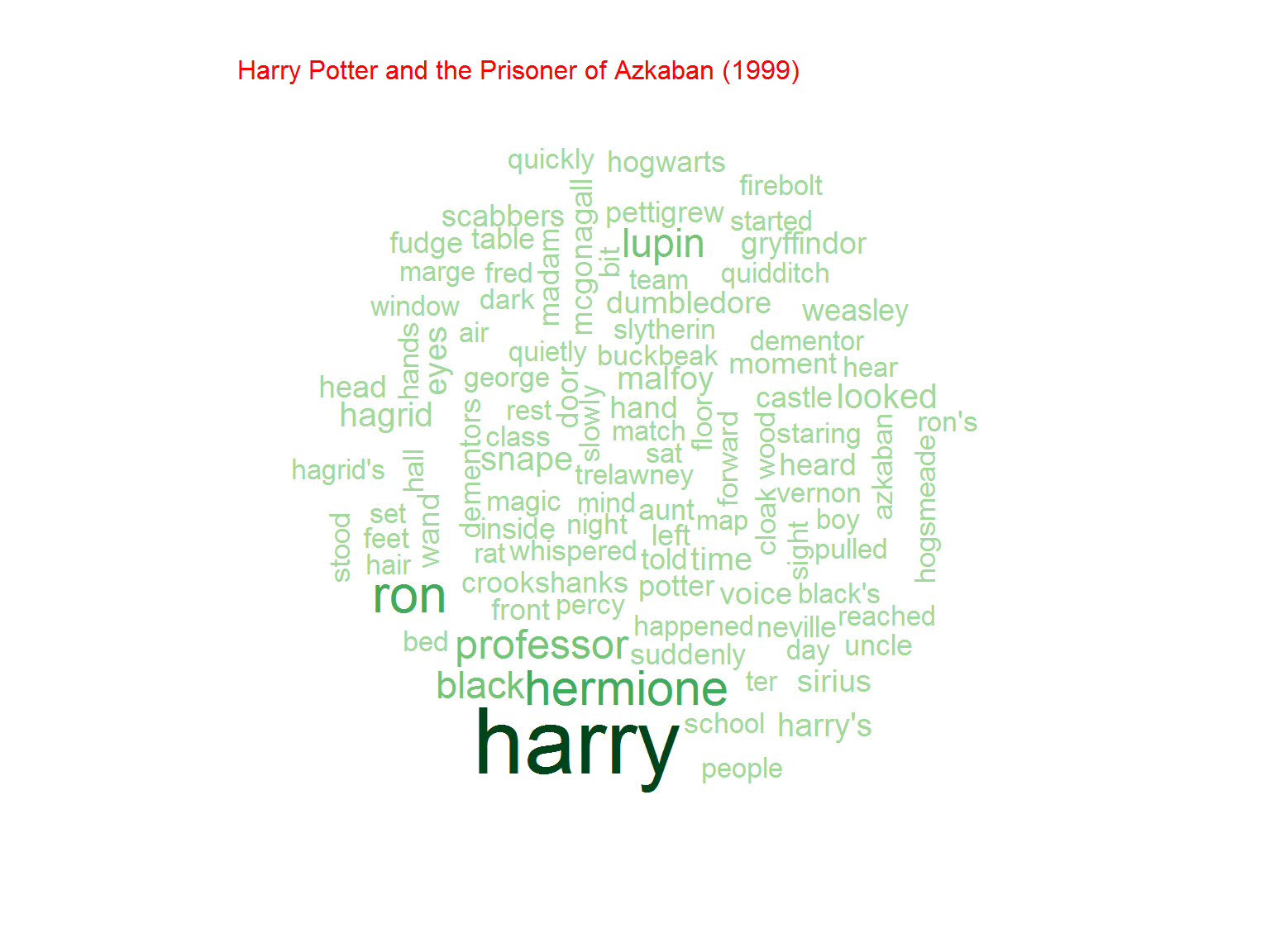
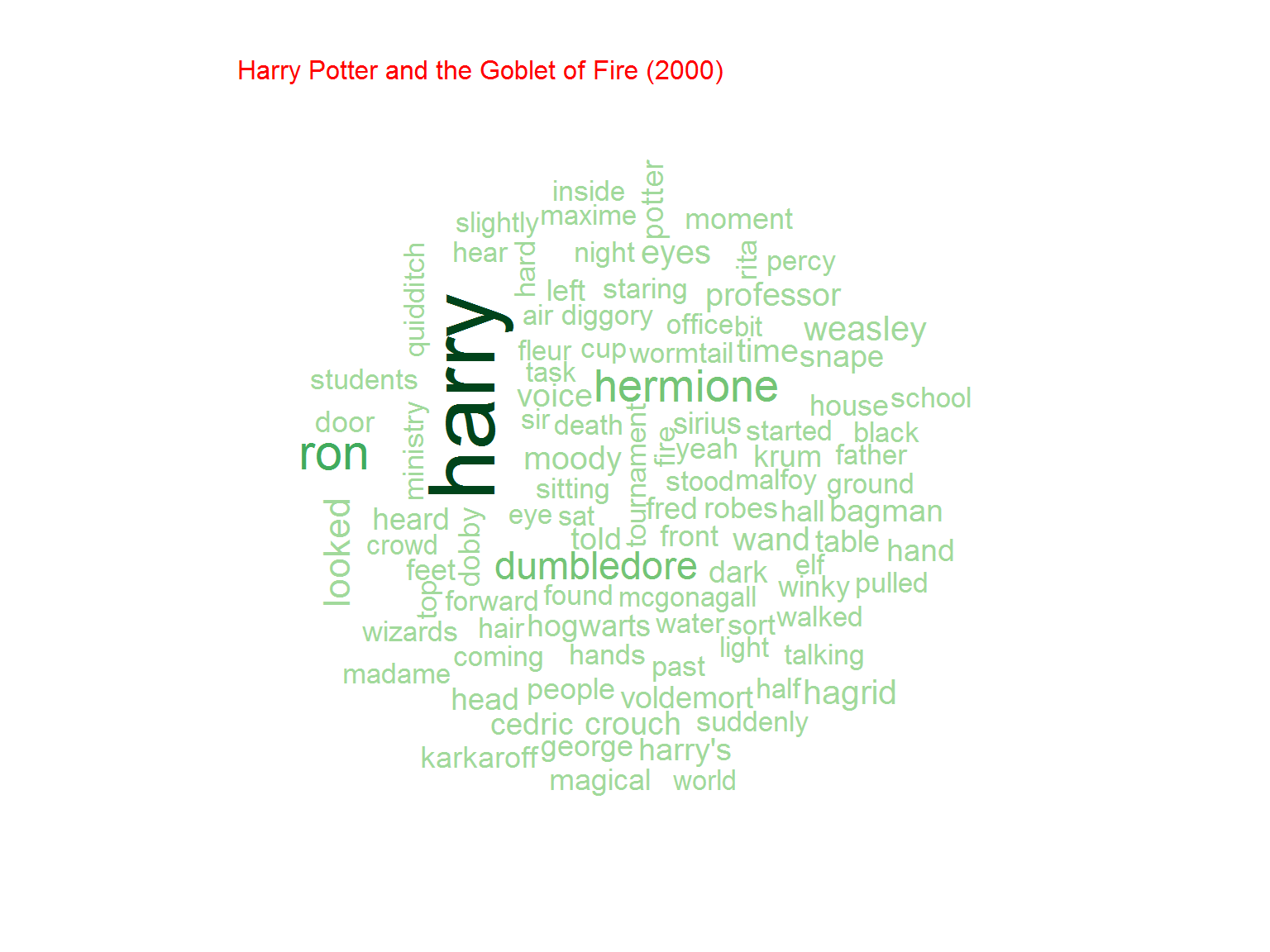
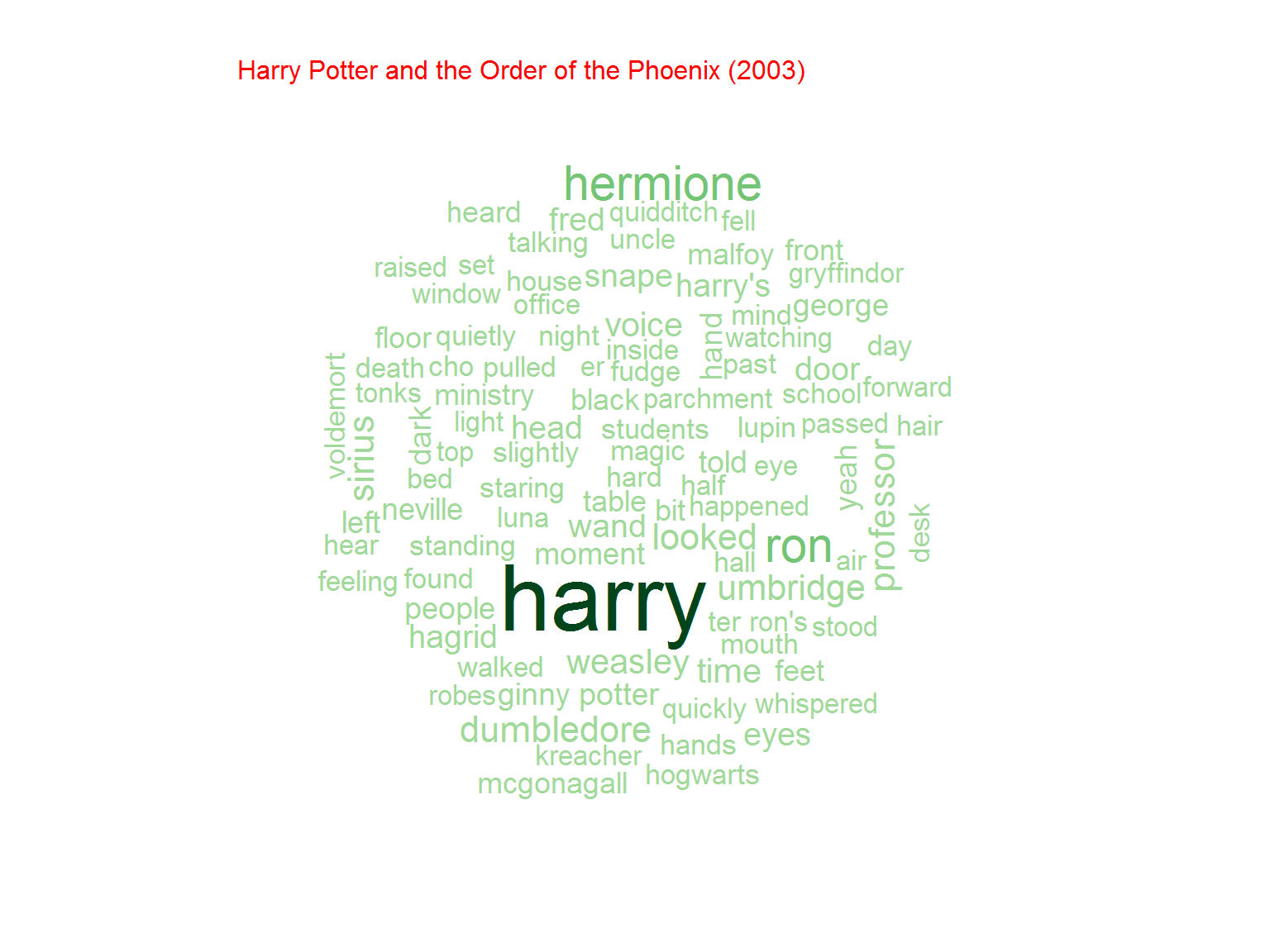
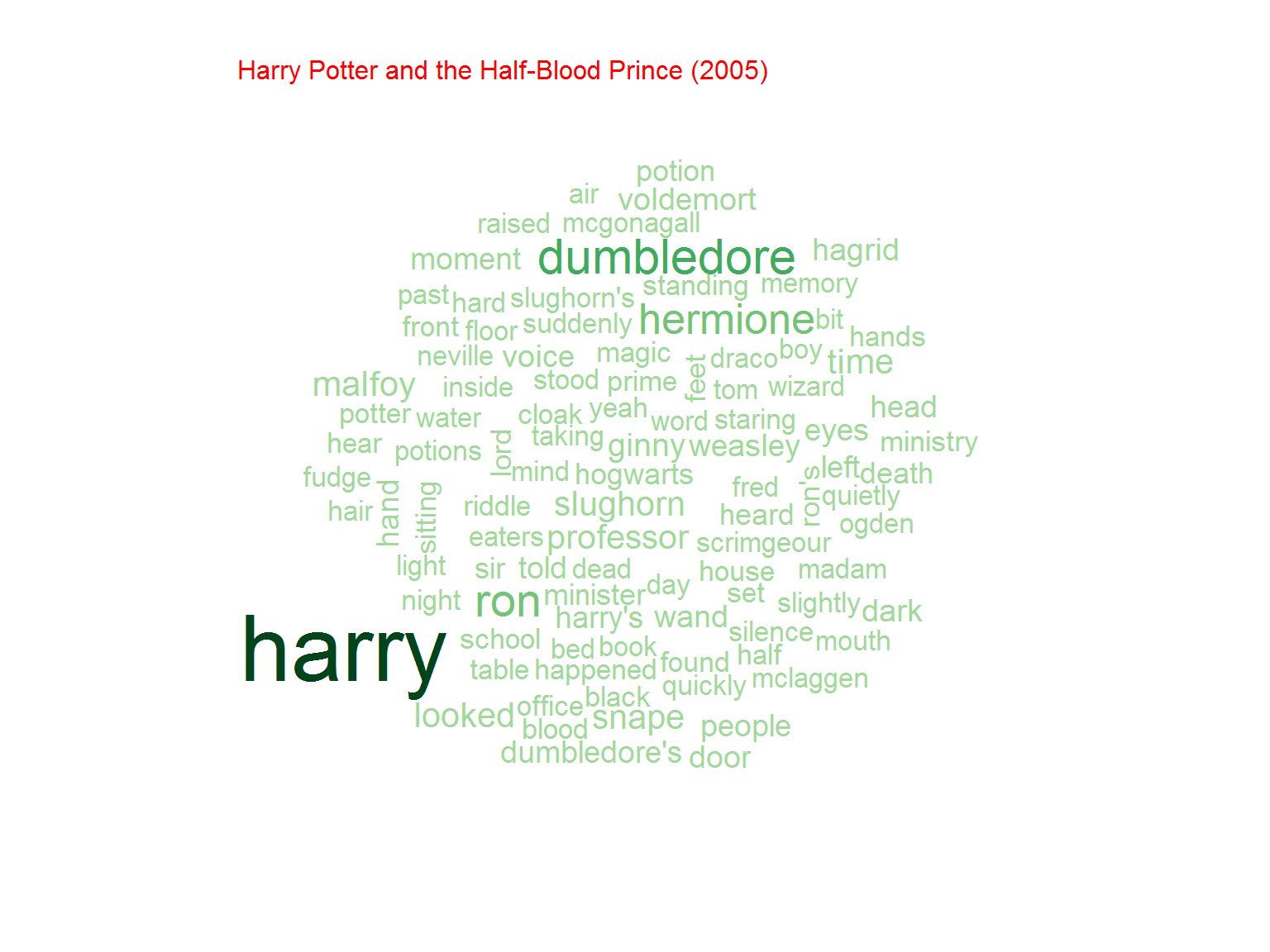
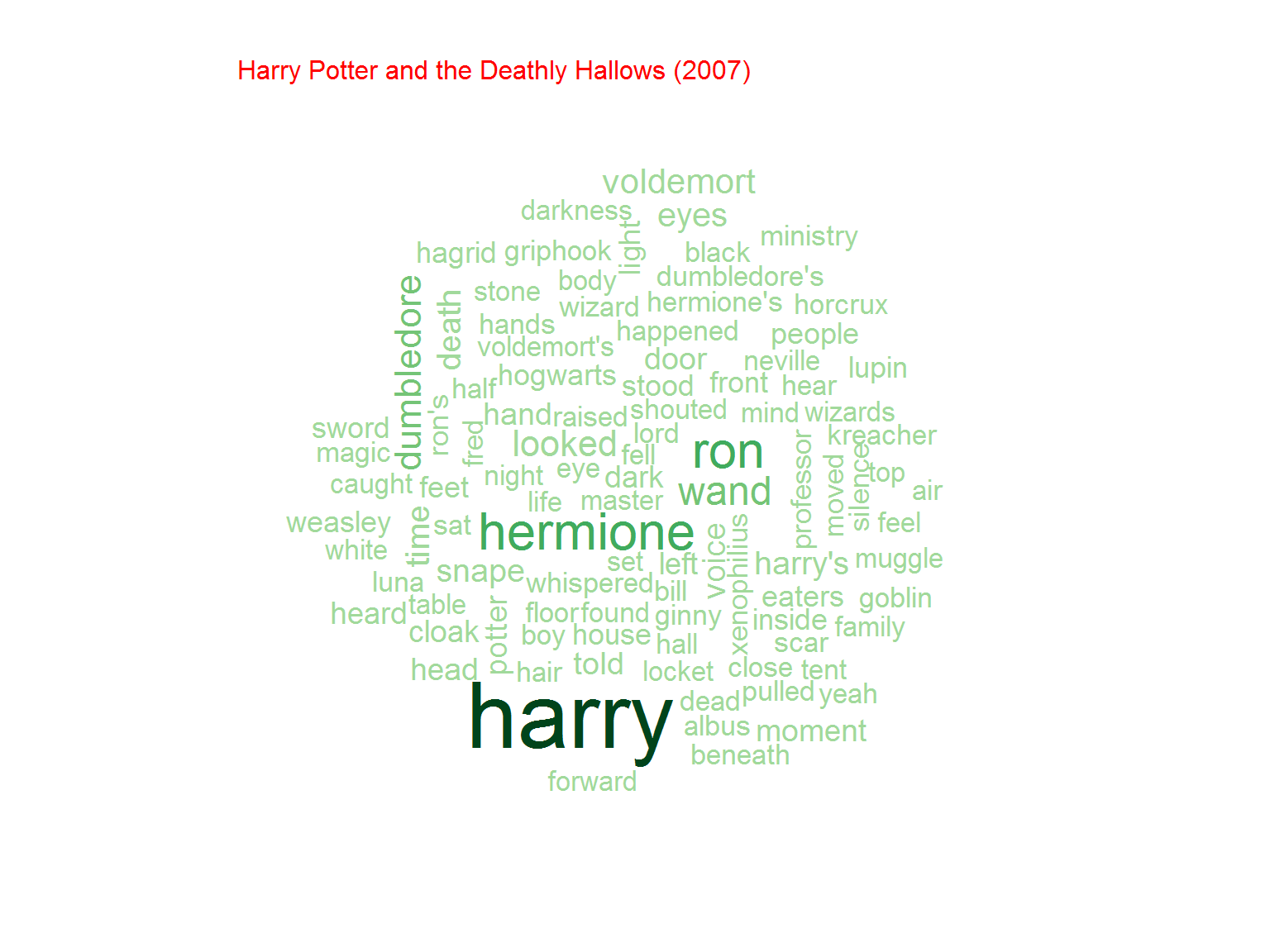
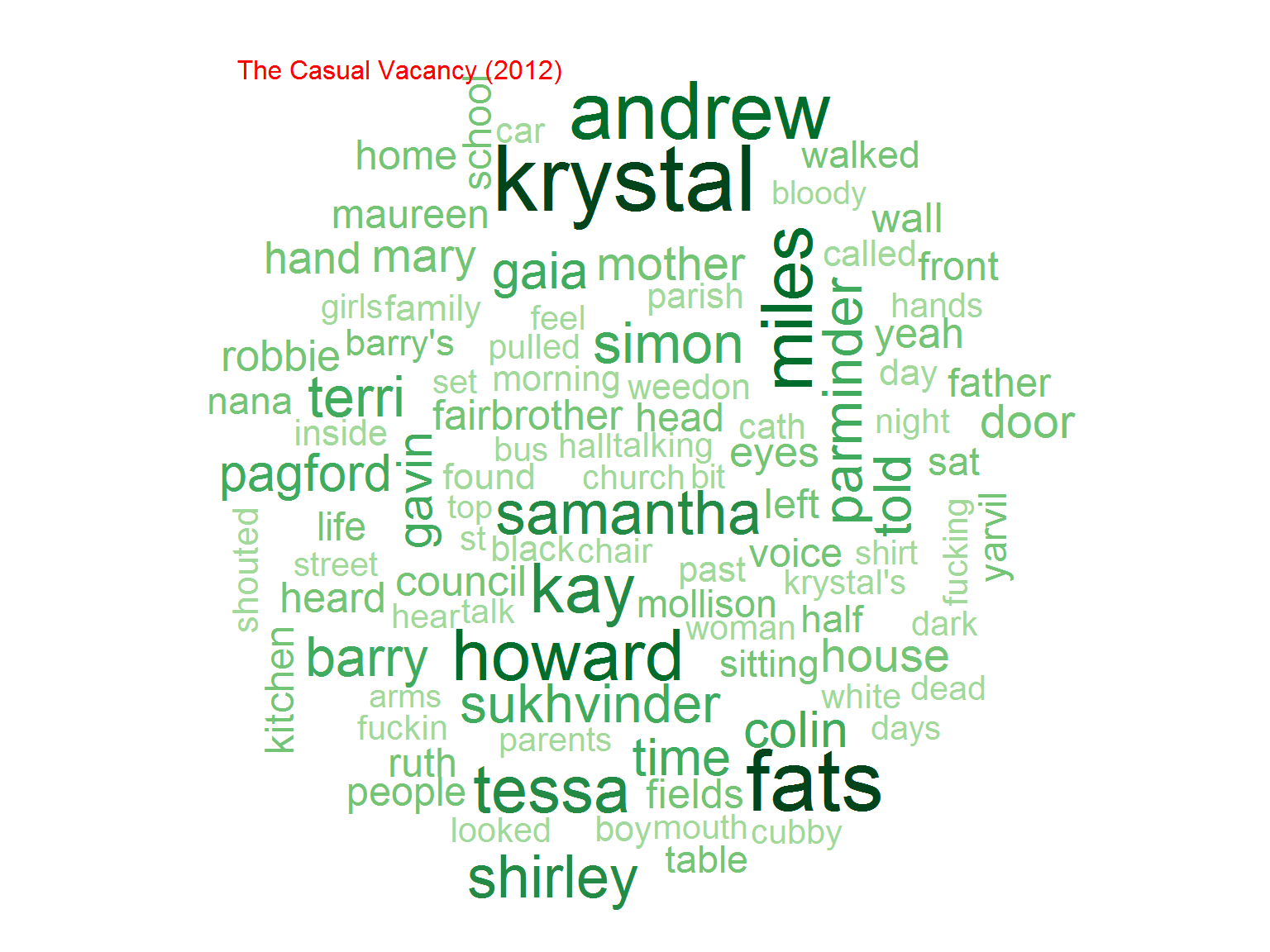
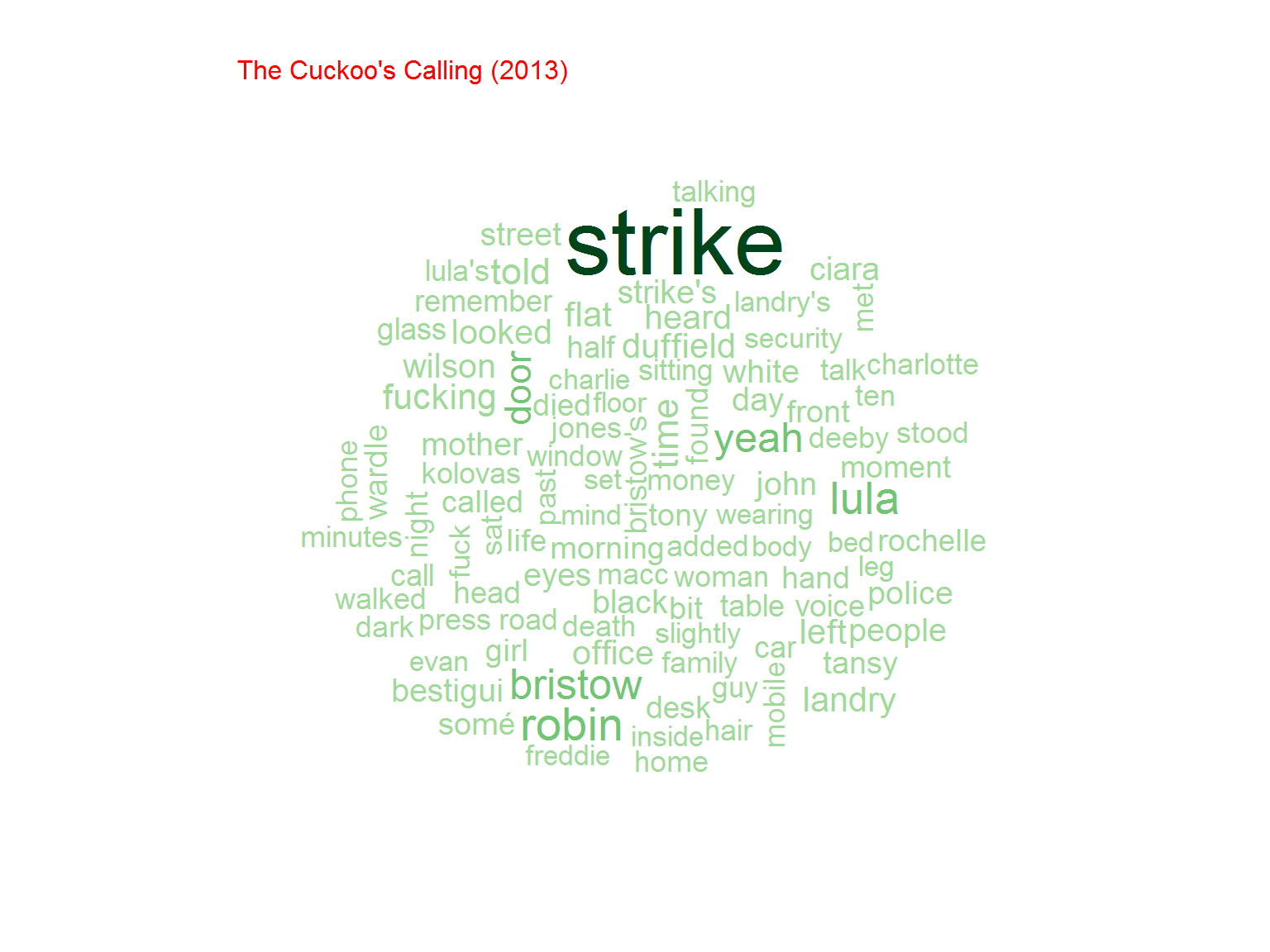


Nie jest dziwnym, że w serii o Potterze najpopularniejsze słowo to “Harry”. Później kolejno imiona poszczególnych bohaterów (Ron, Hermione) ale też na przykład różdżka (wand)
Zobaczmy teraz jak długie są poszczególne książki – sprawdźmy liczbę zdań w każdej z nich:
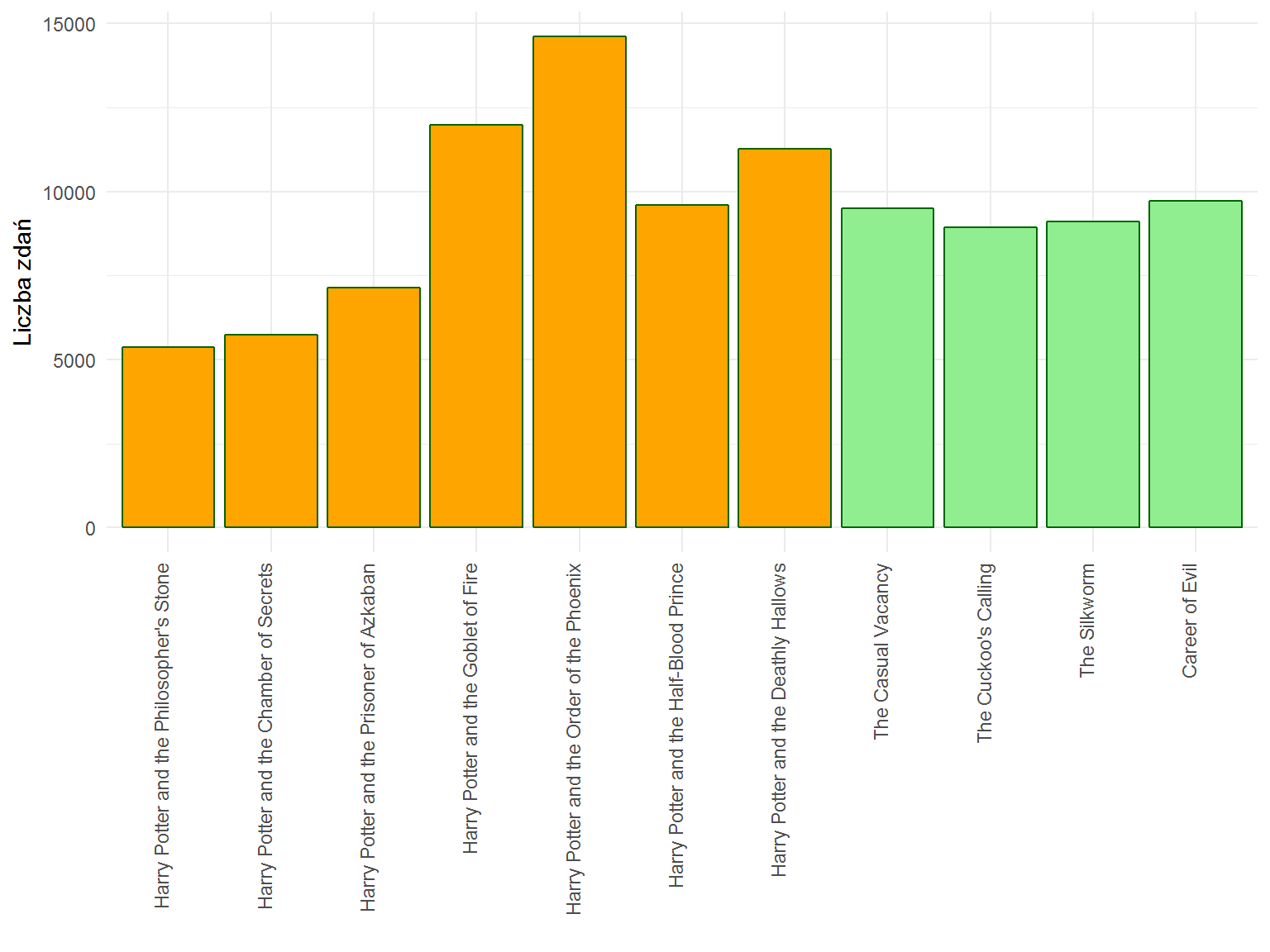
oraz liczbę słów:
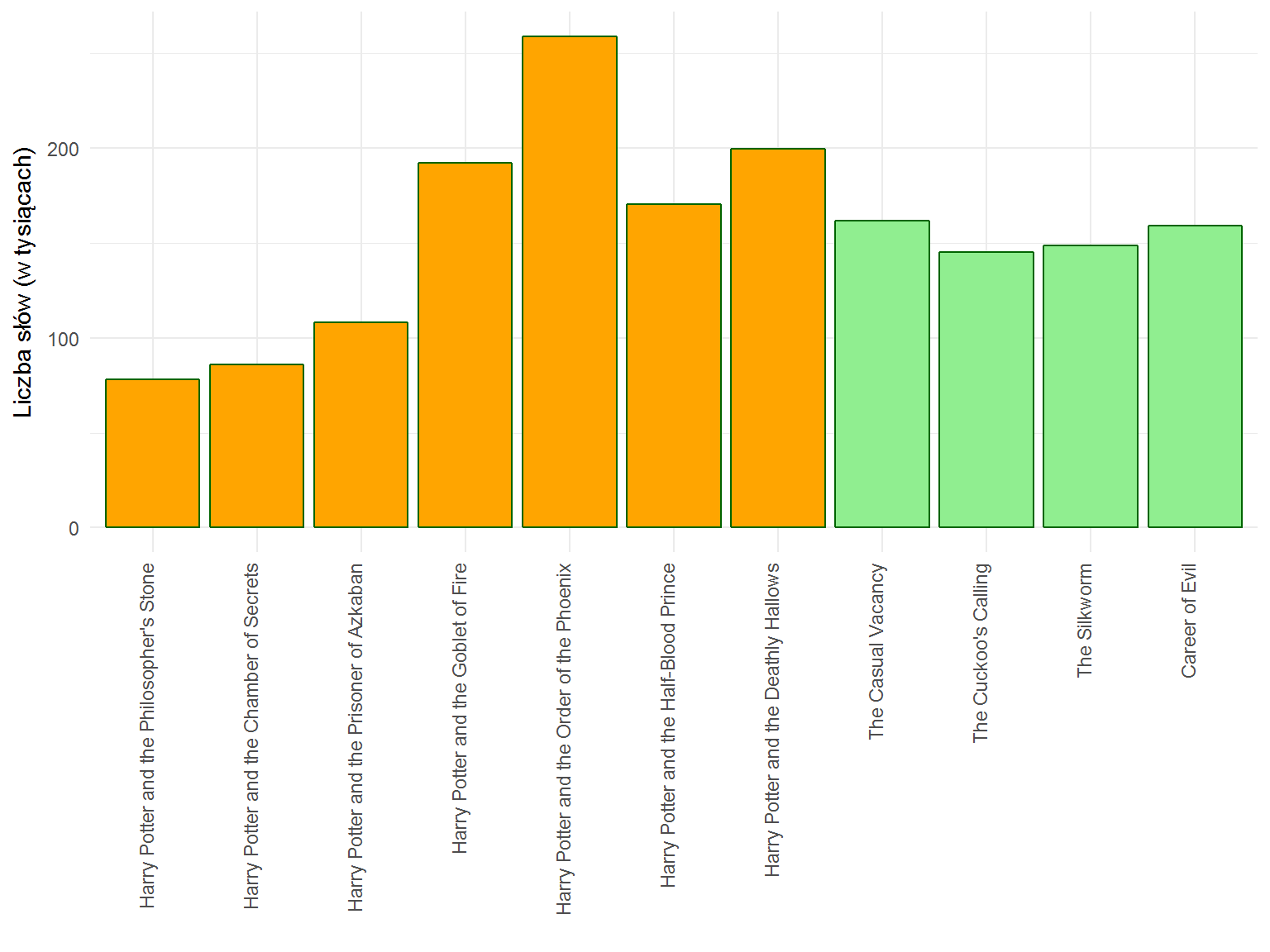
Słupki w obu przypadkach są podobne, co może prowadzić do wniosku, że średnio każde zdanie składa się z podobnej ilości wyrazów:
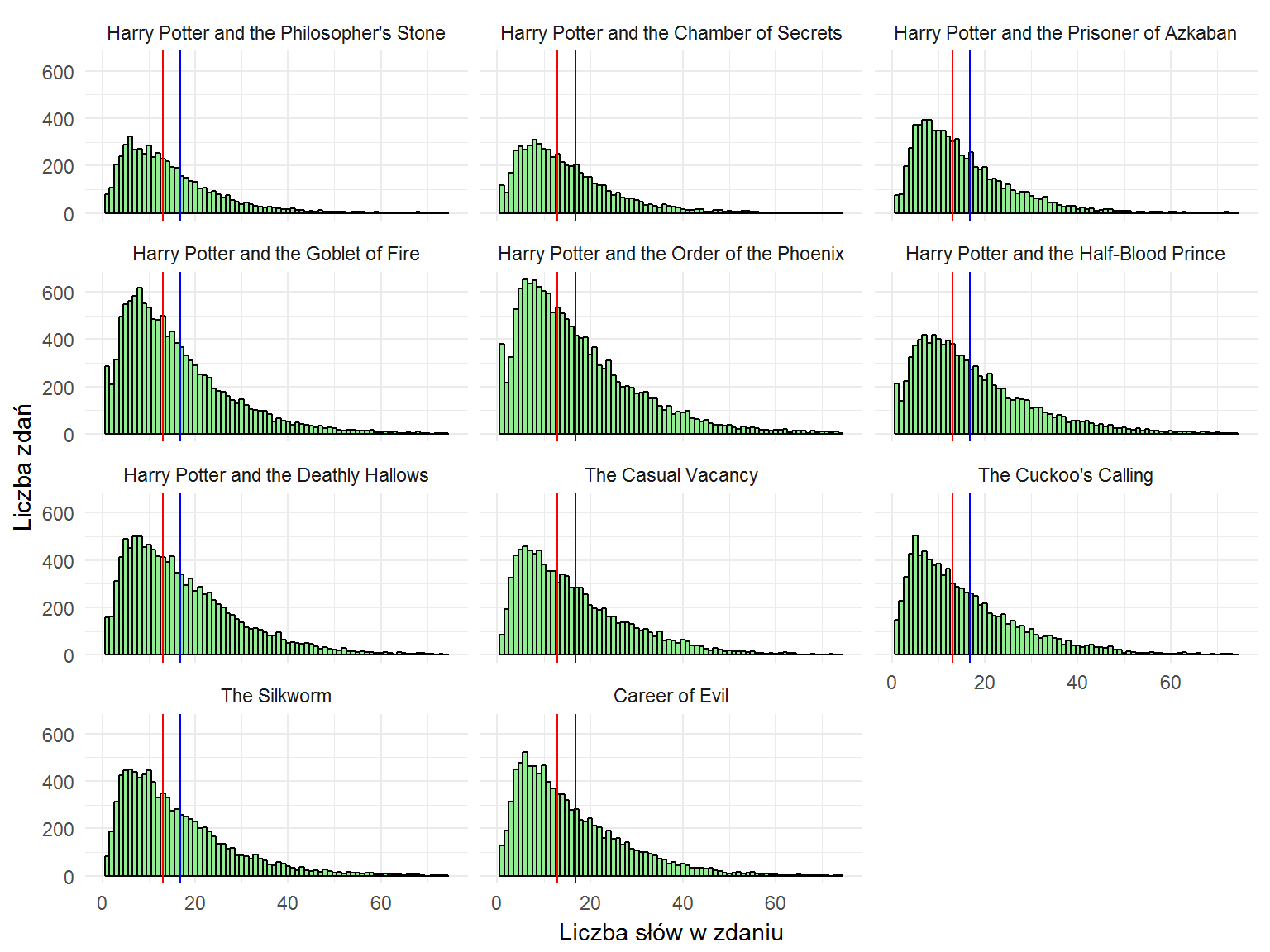
Na powyższym wykresie pionowa czerwona linia oznacza medianę (połowa zdań ma więcej słów, a druga połowa – mniej) zaś niebieska – średnią. Jak widać Rowling właściwie w każdej książce pisze zdania o podobnej długości. Niektóre “kopy” są wyższe – to wynik objętości książki.
Powyższa seria wykresów nie pozwala na szybkie i łatwe porównanie parametrów (średniej i mediany) pomiędzy poszczególnymi książkami. Ale wykres jak poniżej już tak:
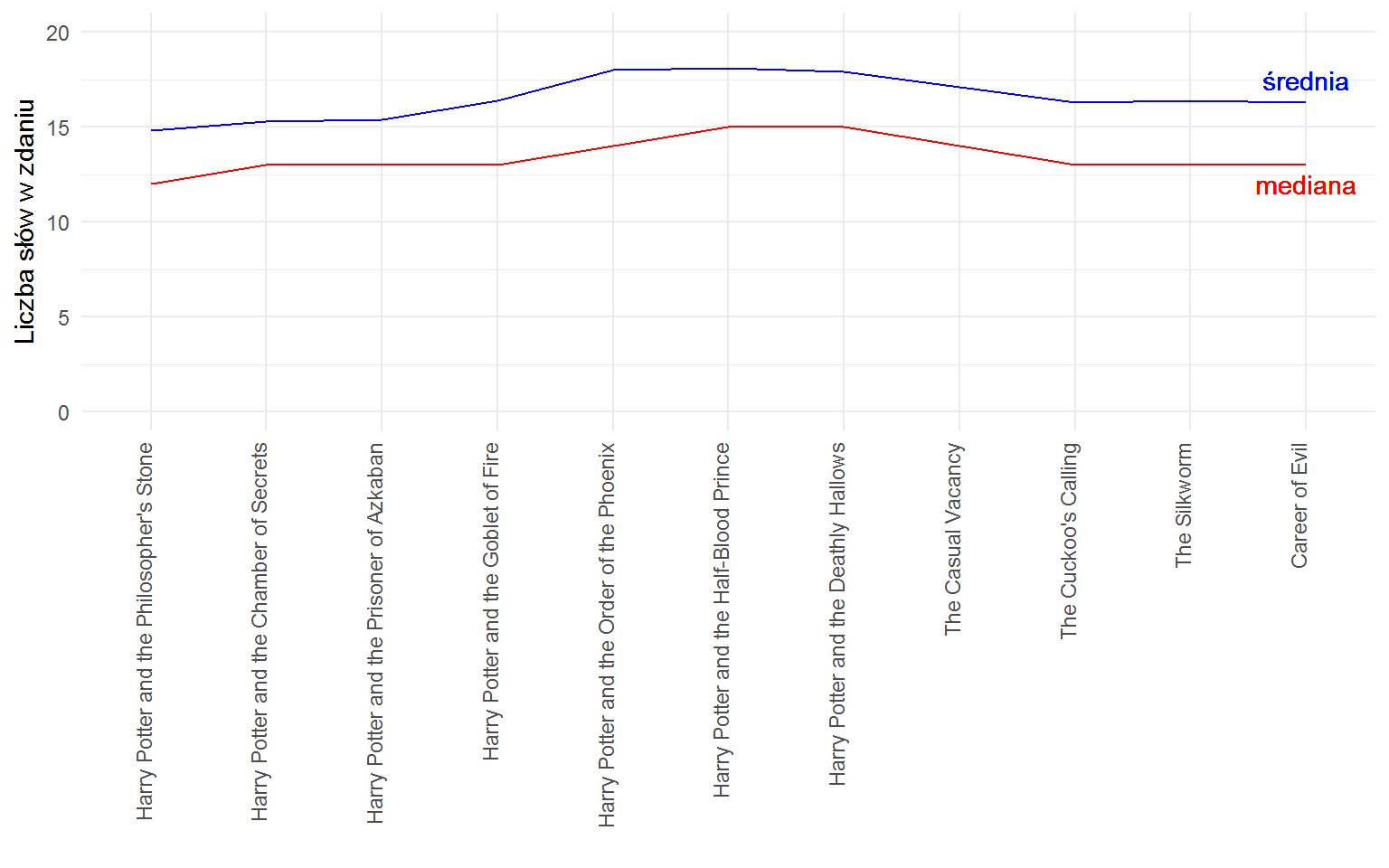
Tutaj wyraźnie widać, że zdania są właściwie prawie zawsze tej samej długości.
Przeanalizujmy na razie samego Pottera. Zobaczmy kiedy (w których momentach książki i w których książkach z serii) pojawiają się poszczególni bohaterowie. Na podstawie chmurki popularnych słów (za chwilę wyjdzie też to w parach słów – bigramach) wytypowałem kilkanaście osób: Harry, Ron, Hermione, Hagrid, Malfoy, Snape, Dumbledore, Voldemort, Vernon, McGonagall, Trelawney, Umbridge, Petunia, Lupin. Zobaczmy:
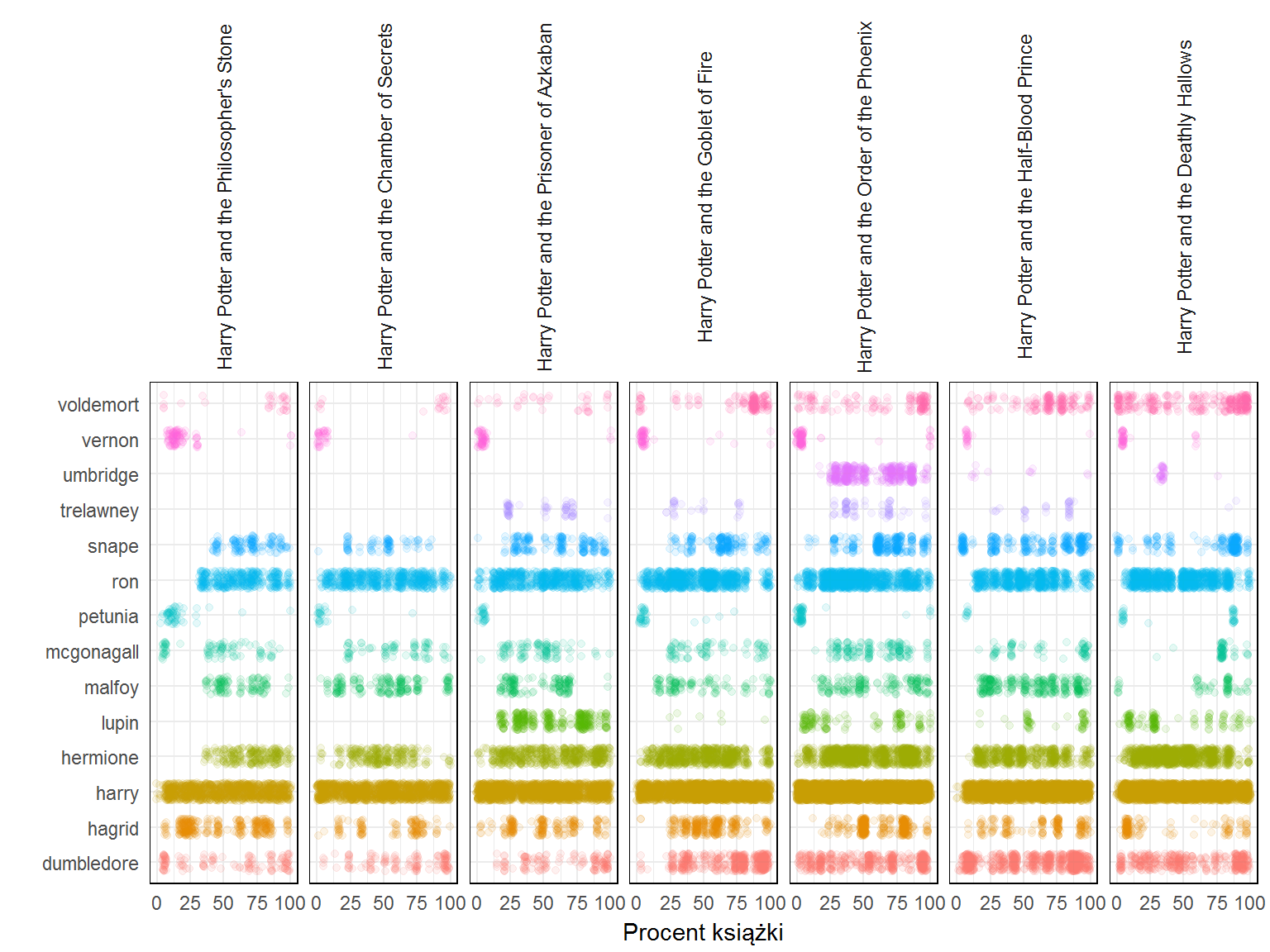
Harry oczywiście występuje cały czas. Ale na przykład Ron i Hermoine pojawiają się gdzieś w 1/3 pierwszej części – wtedy zapewne Harry przybywa do szkoły czarodziei. Tak na przykład Umbridge największy udział ma w części Harry Potter i Zakon Feniksa, w której się pojawia. Petunia z kolei pojawia się na początku każdej z części, podobnie jak Vernon. Być może coś ich łączy?
Na pewno coś łączy Hermonię, Rona, Snape’a czy Mafloy’a lub Hagrida.
Sprawdźmy jak często pojawiają się poszczególne imiona (8 najczęściej występujących). Poniższy wykres obrazuje udział procentowy popularności określonego imienia wśród ósemki najpopularniejszych imion. Czyli – im częściej dane imię pojawia się w części tym wyżej ono znajduje się na wykresie.
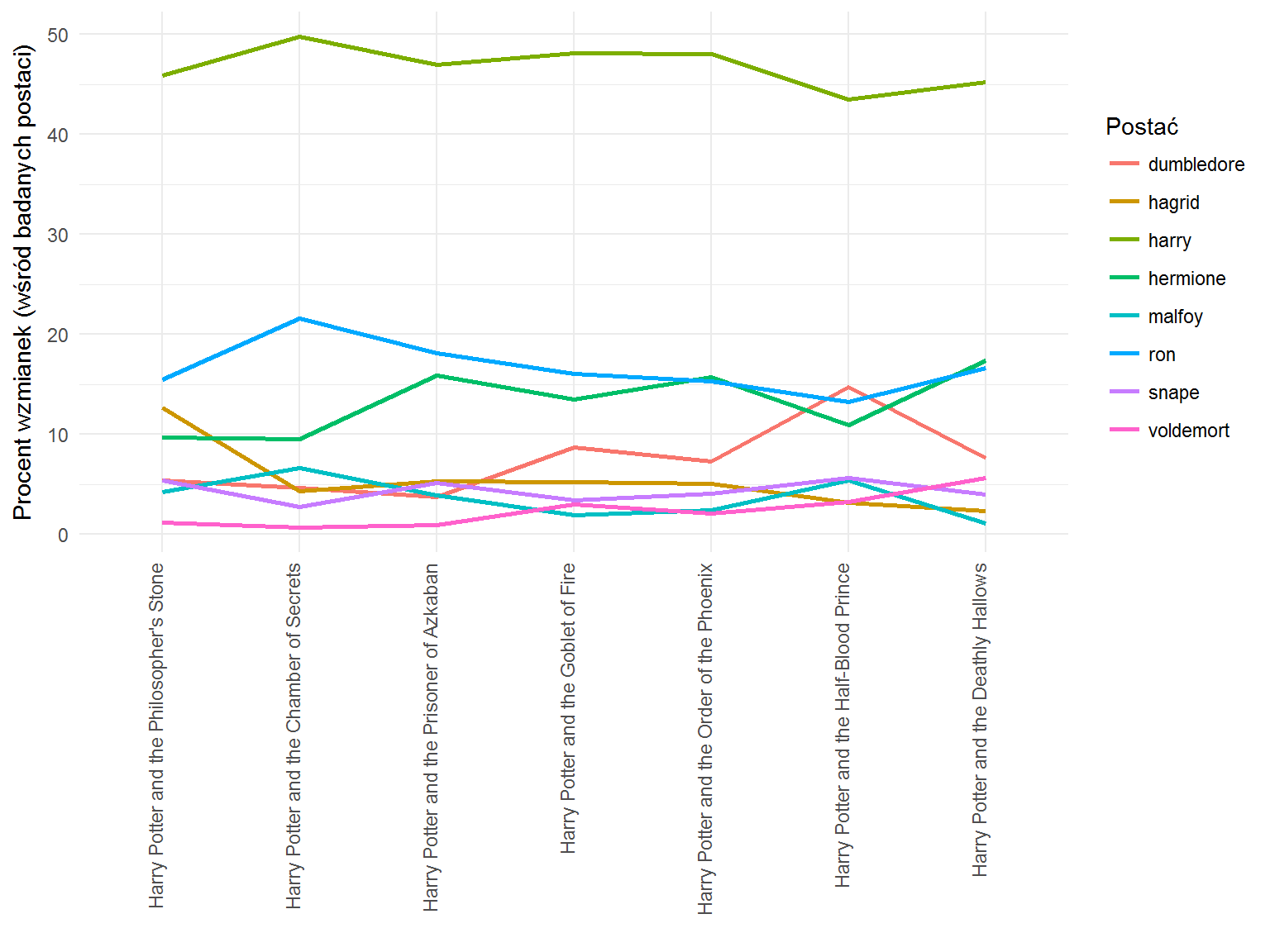
Bez zaskoczenia Harry dominuje całą serię – połowa należy do niego. Ciekawe jest coś innego – udział Rona spada w kolejnych częściach, a delikatnie rośnie udział Hermoine. Z kolei Dumbledore najbardziej aktywny jest w części Harry Potter i Książę Półkrwi. Widać to też na wcześniejszym wykresie
Sprawdźmy teraz gdzie odbywa się akcja (albo o jakich miejscach mowa). Do wyboru mamy (angielskie nazwy): privet drive, diagon alley, hogwarts, azkaban, ministry of magic, grimmauld place.
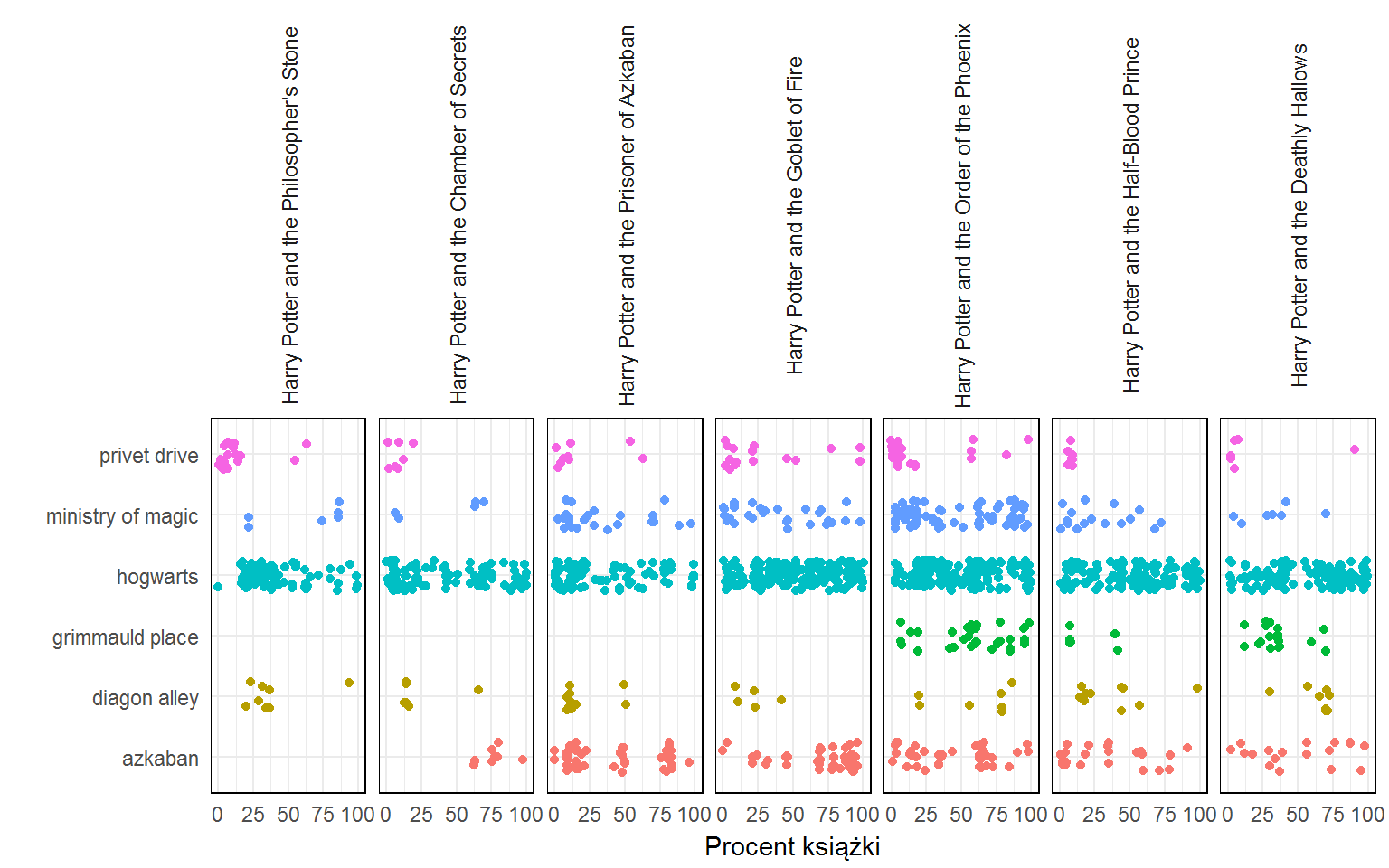
Ciekawostka – “privet drive” pojawia się w tych samych miejscach co Petunia. Coś Wam to mówi?
Na koniec sprawdźmy jakie i jak często występują klątwy i zaklęcia (jak na książkę o magii przystało)?
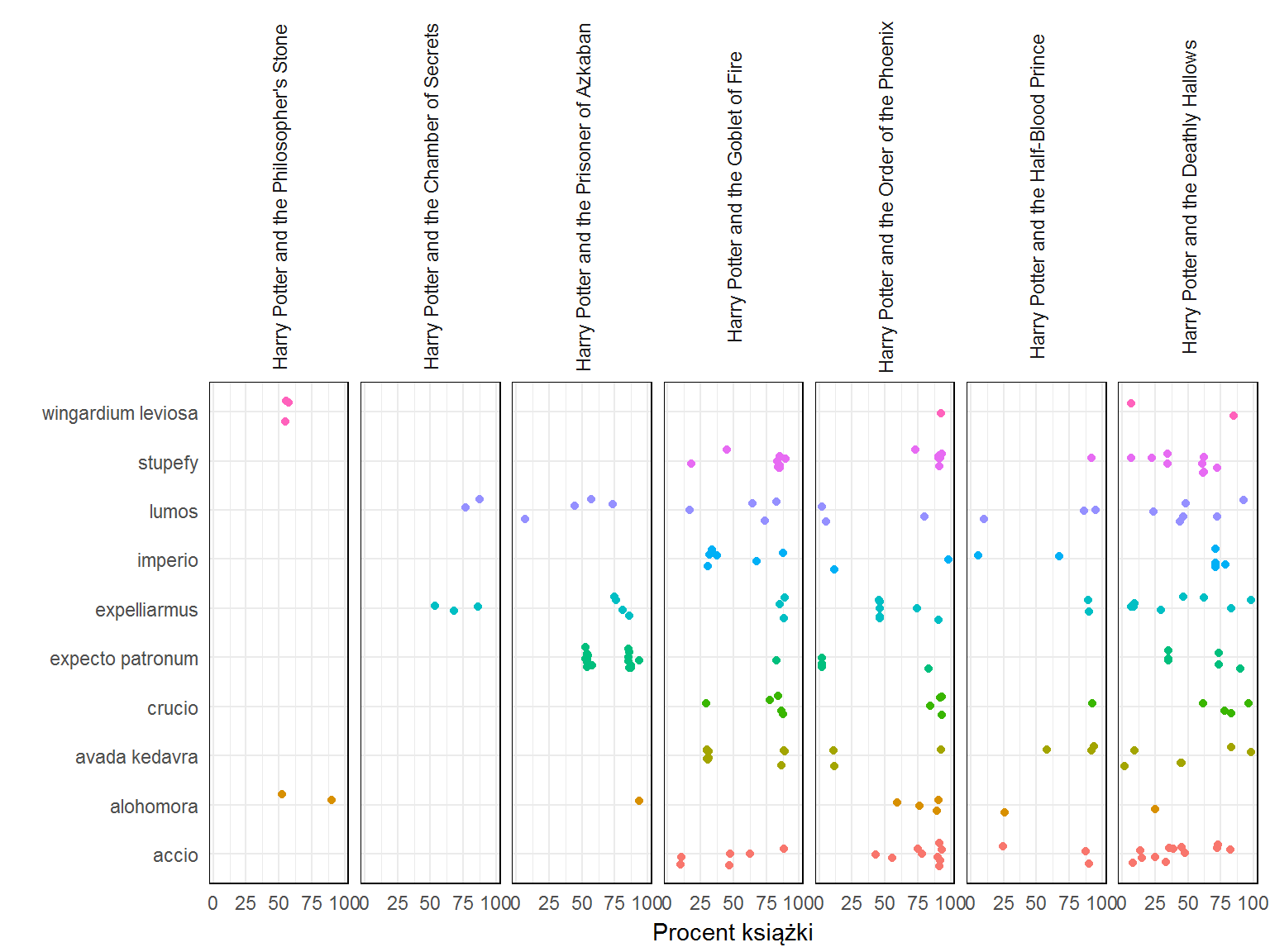
Początkowo zbyt wiele nie czarują, ale im dalej w las tym sprawa wygląda poważniej.
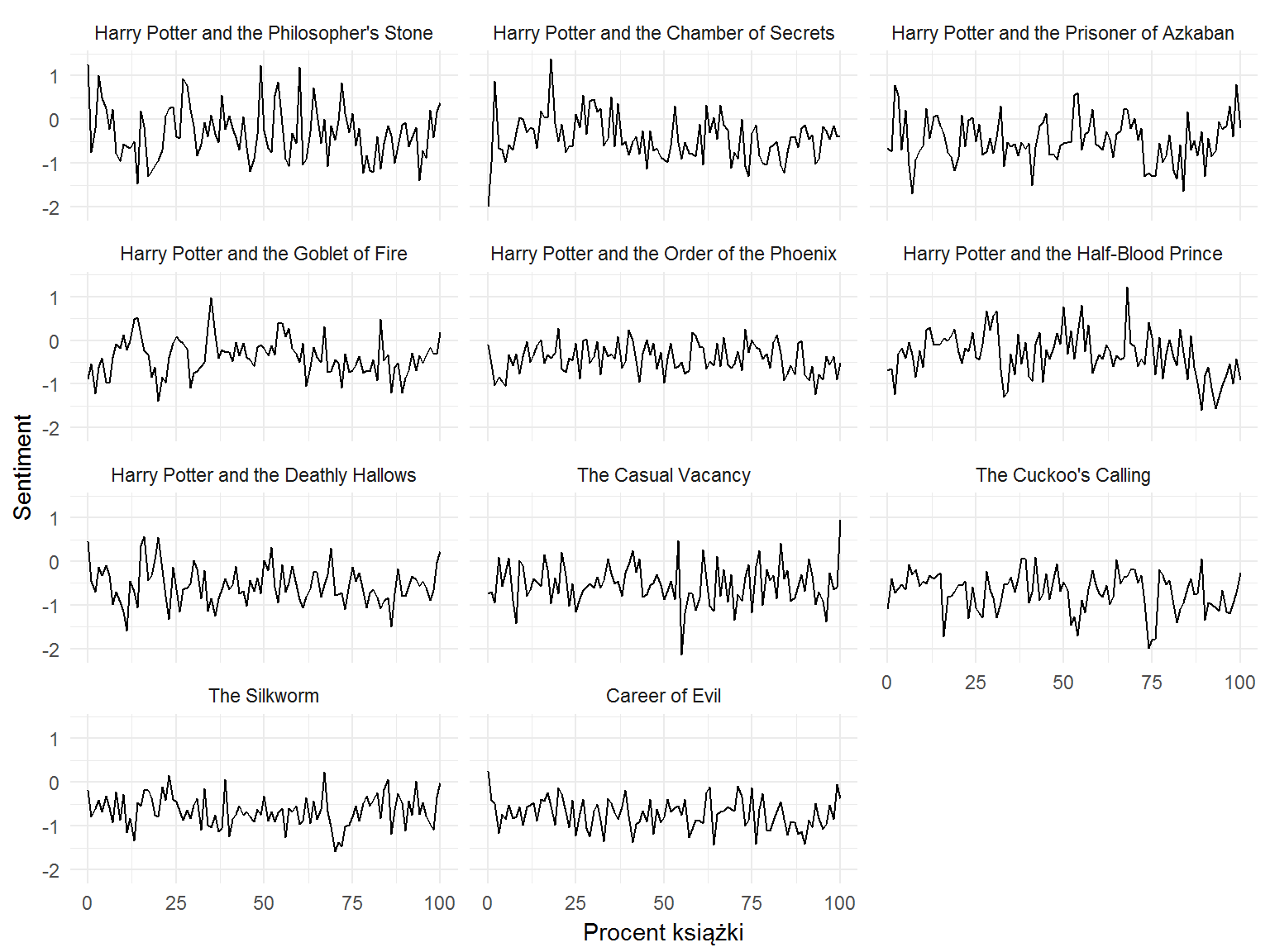
Czas na ciekawsze sprawy – czy książki (już wracamy do całej twórczości Rowling) są coraz bardziej “pozytywne” czy wręcz przeciwnie? “Pozytywne”, bo wydźwięk może być pozytywny lub negatywny (w skali -5 dla negatywnych do +5 dla pozytywnych). Miara polega na przypisaniu każdemu ze słów określonej wartości liczbowej wyrażającej emocje i ich zabarwienie jakie niosą ze sobą słowa.
I tak najbardziej negatywne to m.in. bastard, cock, cocksucker i tym podobne, wszystkie mają po -5 punktów. ass jest już ładogniejsze – ma -4 punkty. Te pozytywne to na przykład breathtaking czy outstanding (po +5 punktów), albo amazing (+4 punkty). Neutralne (0 punktów) to some kind. W słowniku AFINN zawartym w pakiecie tidytext jest 2476 słów. Nie za dużo, ale wystarczająco.
Każde ze słów (w ramach konkretnego zdania) mamy opisane “punktem czasowym” – w którym zdaniu (lub inaczej mówiąc – w którym procencie) książki występuje. Możemy więc policzyć średnią z wydźwięku dla kolejnych “chwil” w książce i je narysować na wykresie. Pisałem o tym trochę w drugiej części tekstu o Pulp Fiction, tam też znajdziecie ciekawy film z krótkim wykładem Kurtem Vonneguta. Polecam poszukać czegoś na temat “Arc of Story”, chociażby tekst 6 Story Arcs Define Western Literature, Data-Mining Study Reveals (gdzie nota bene jest wykres mniej więcej przypominający to co mamy tutaj – dotyczy książki Harry Potter i Insygnia Śmierci).
Zobaczmy jeszcze czy wraz z postępem czasy pani Rowling używa w swoich książkach słów coraz bardziej pozytywnych czy negatywnych?
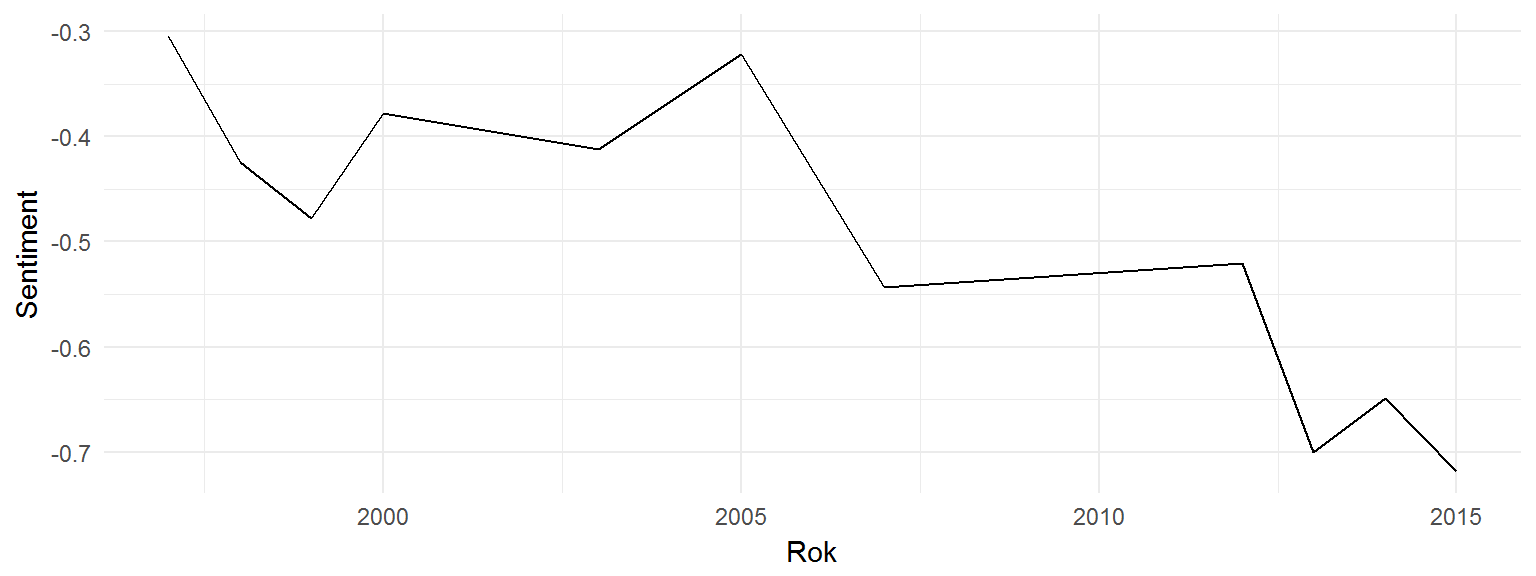
W bardzo dużym uproszczeniu – jest coraz bardziej mrocznie. Ale różnice są na poziomie ułamków punktów.
Teraz – podobnie jak w przypadku śledztwa dotyczącego Remigiusza Mroza i Zygmunta Miłoszewskiego – sprawdźmy czy statystycznie rzecz biorąc wszystkie badane książki napisała Rowling?
Na początek podzielimy książki na dwie grupy – o Harrym Potterze (podpisanych jako J.K.Rowling) i pozostałe (podpisanych pseudonimem Robert Galbraith). Dla każdego ze słów w ramach tych grup policzymy udział procentowy w całej grupie. Na koniec weźmiemy po 10% najbardziej popularnych słów z grup i policzymy współczynnik korelacji pomiędzy częstościami wystąpienia.
Podobieństwo liczone w ten sposób daje nam wartość 0.76. To całkiem sporo, chociaż dla porównania w poprzednim poście autorstwo Enklawy przypisaliśmy Mrozowi na podstawie współczynnika równego 0.88 a Bezcennego przypisaliśmy Miłoszewskiemu ze współczynnikiem 0.83.
Spróbujmy zatem inaczej – nie ma co się ograniczać do najpopularniejszych słów (tym bardziej, że bez filtrowania są to głównie imiona bohaterów i miejsca akcji), skoro można porównać każdą książkę z każdą na podstawie wszystkich wspólnych słów (i ich częstości występowania):
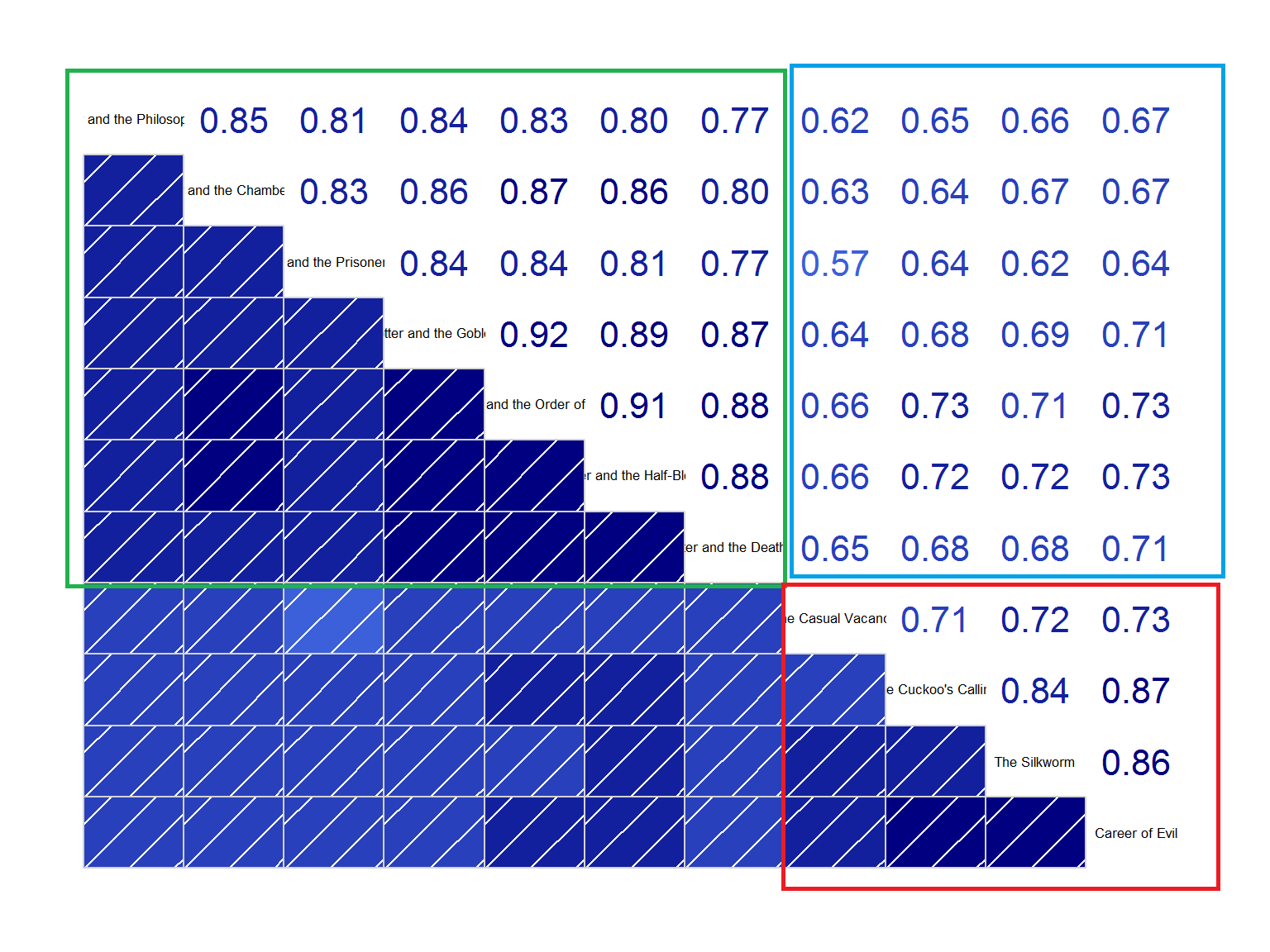
Widać tutaj wyraźnie trzy obszary:
- zaznaczony na zielono obszar książek o Harrym Potterze – wszystkie współczynniki w okolicach 0.77-0.92, co jest bardzo silną korelacją i wręcz graniczy z pewnością, że autorem każdej książki z serii jest ta sama osoba (bo używa tego samego “słownika autora”)
- zaznaczony na czerwono obszar książek podpisanych Robert Galbraith – też widać spójność, chociaż nieco mniejszą (0.71-0.86)
- zaznaczony na niebiesko obszar wątpliwego współautorstwa ze współczynnikiem korelacji w granicach 0.57-0.73 (średnia z nich to 0.62). Ciągle jest to jednak dodatnia korelacja, a w połączeniu z badaniem średniej długości zdań możemy pokusić się o tezę, że to jedna i ta sama osoba pisała obie grupy książek.
Policzmy jeszcze odległość między częstościami użycia słów.
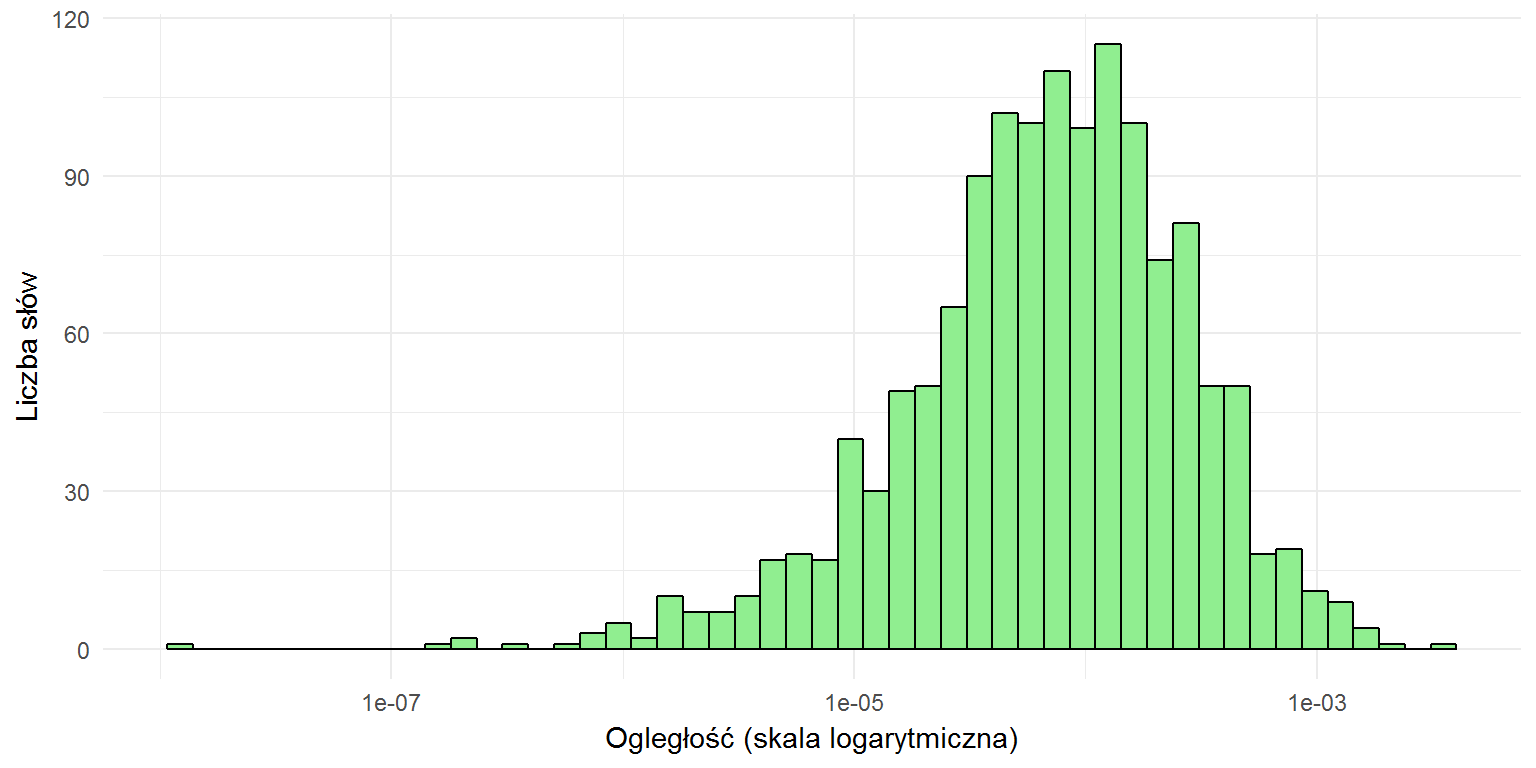
Histogram jest dość zwarty i przypomina rozkład normalny. Zobaczmy to na wykresie punktowym, dodatkowo algorytmem k-średnich grupując słowa (na podstawie częstości w grupie oraz odległości pomiędzy grupami) w pięć klas. Słowa najbliższe (czyli występujące tak samo często w obu grupach) powinny leżeć na przekątnej.
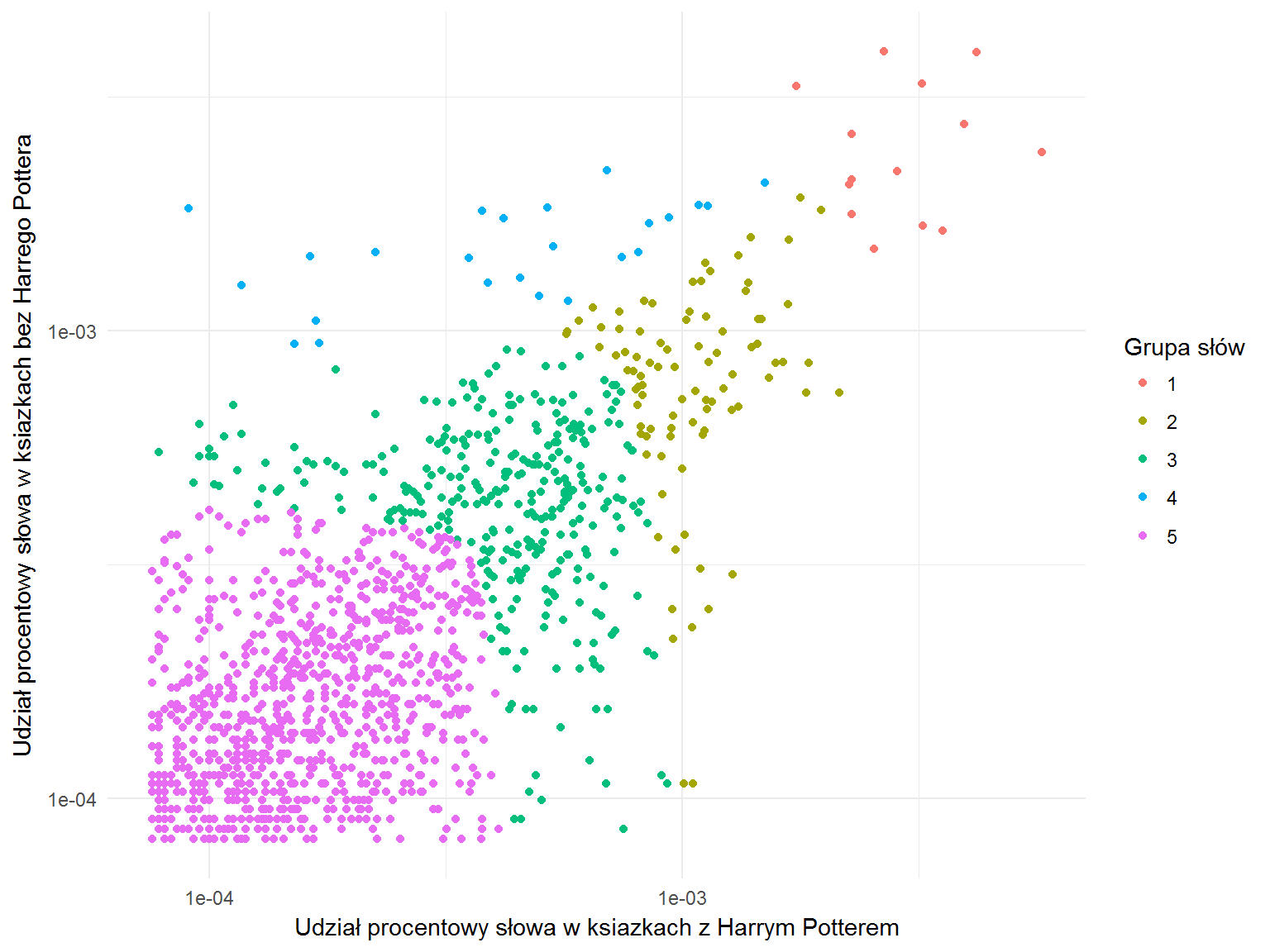
Zobaczmy jakie słowa należą do grupy znajdującej się w prawym górnym rogu – czyli tych, które w obu paczkach książek występują najczęściej:
|
1 2 |
## [1] "black" "dark" "door" "eyes" "hand" "head" "heard" ## [8] "left" "looked" "people" "time" "told" "voice" "yeah" |
Według mnie tutaj wychodzi swoista ułomność języka angielskiego. Są to na tyle ogólne słowa, że pewnie powtarzają się w znakomitej większości angielskich tekstów…
To może słowa, które występują równie często w obu grupach (przekątna wykresu)?
|
1 2 3 4 5 6 |
## "accept" "approached" "bank" "bench" "cheek" ## "choose" "country" "cracked" "decided" "edged" ## "forgot" "fork" "friendly" "frightened" "instant" ## "leave" "lock" "missed" "mysterious" "obvious" ## "pieces" "playing" "signs" "threatening" "undoubtedly" ## "wear" "wearing" "yard" |
Tutaj już chyba lepiej.
Na koniec przyjrzyjmy się bigramom, czyli zbitkom dwuwyrazowym. Na początek chmurki:
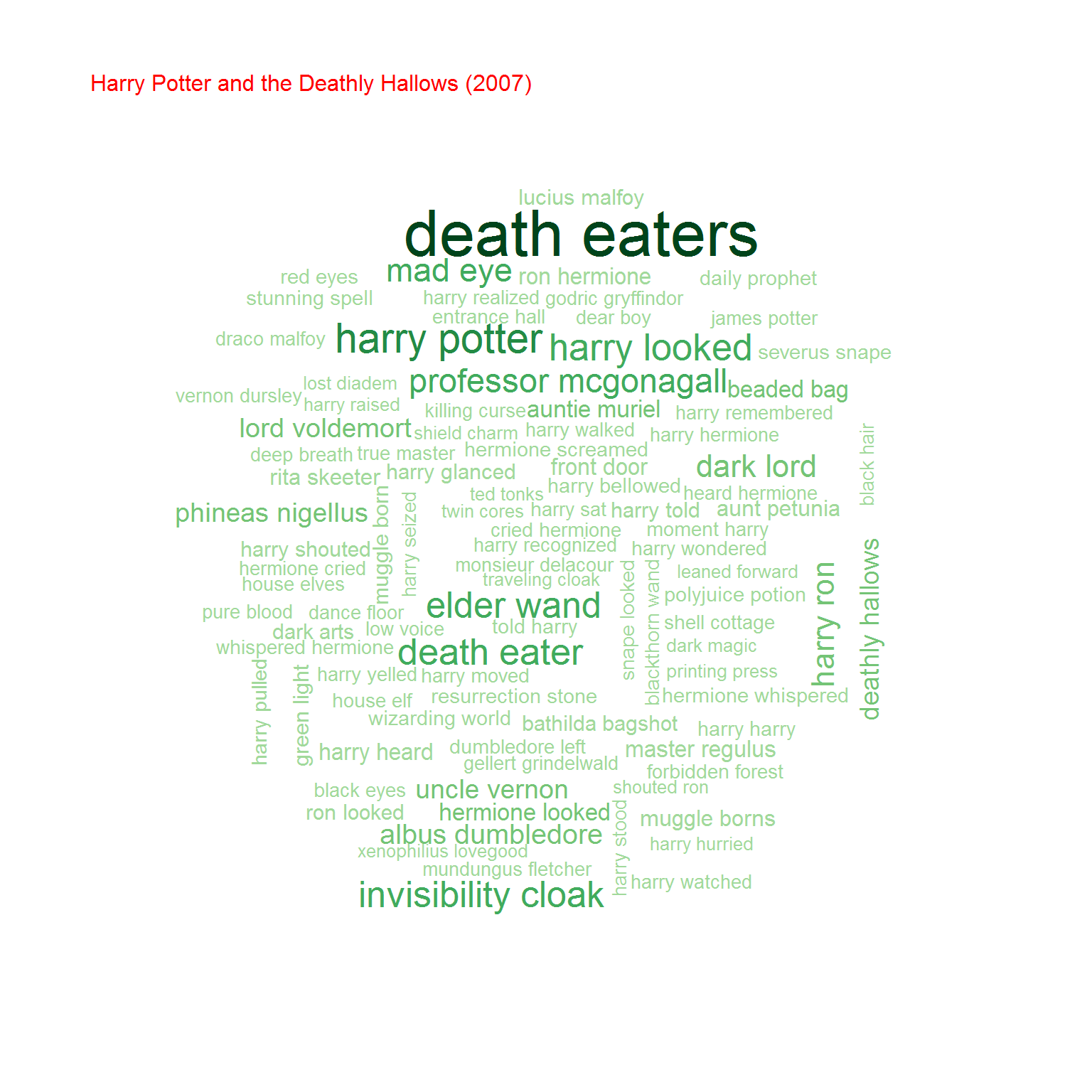
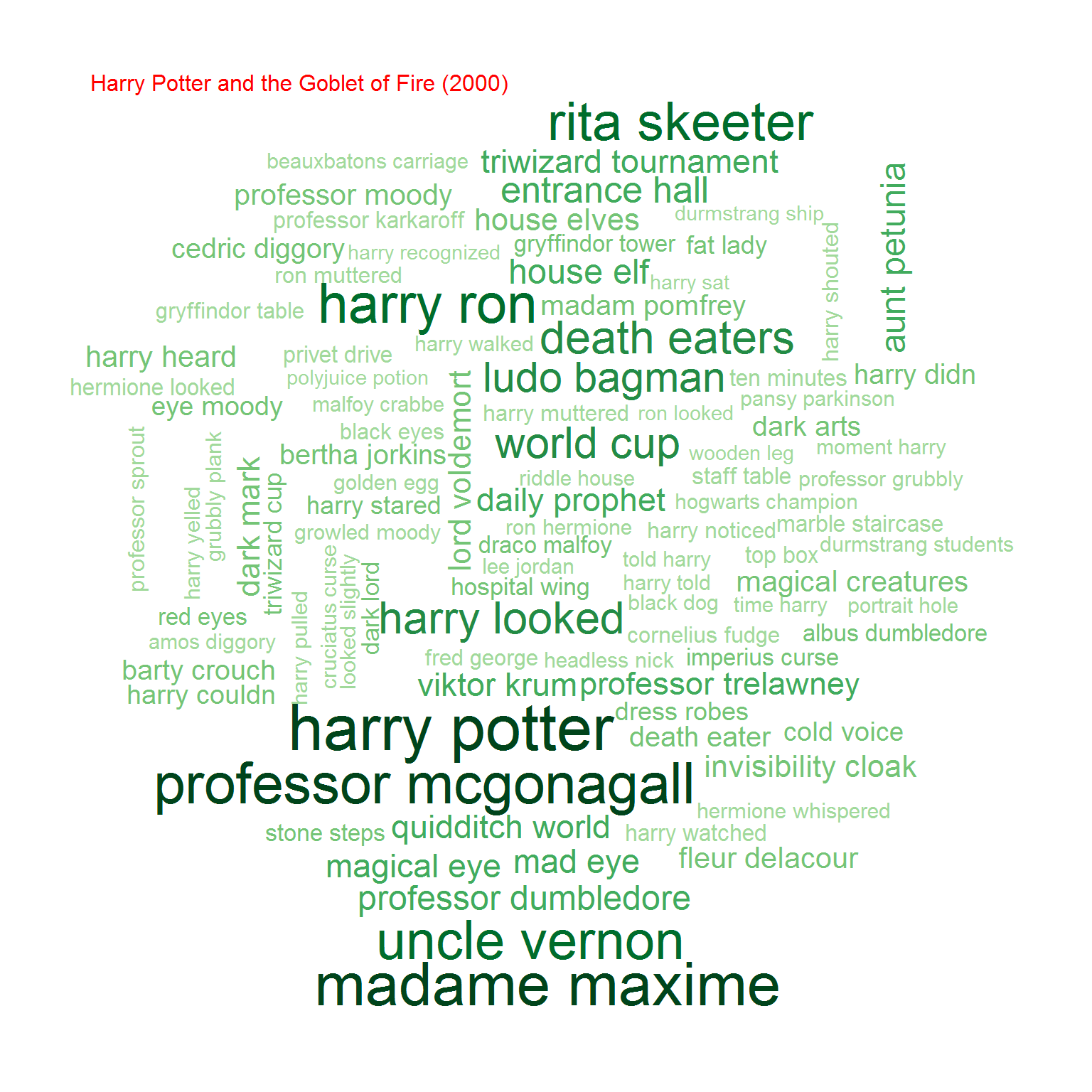
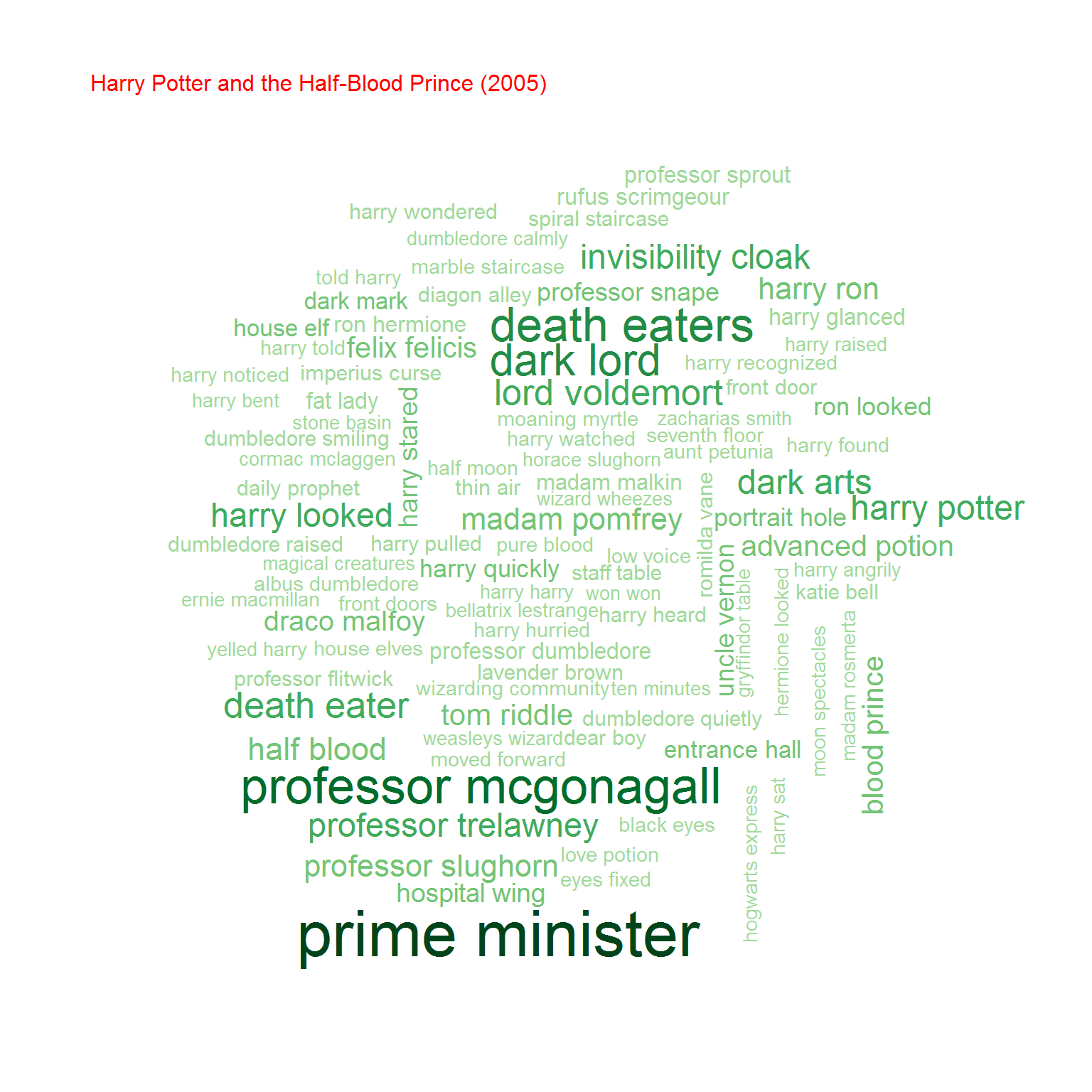
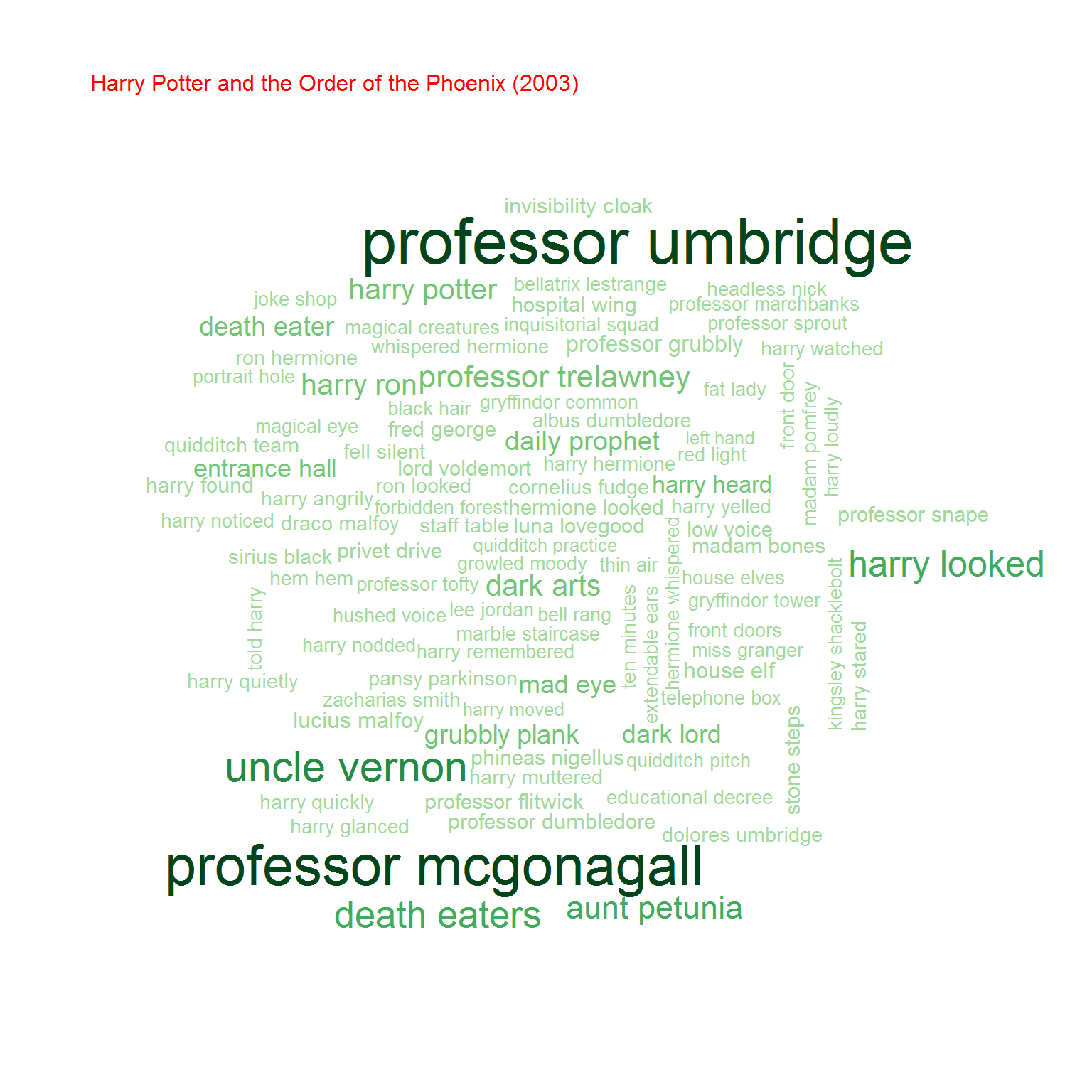
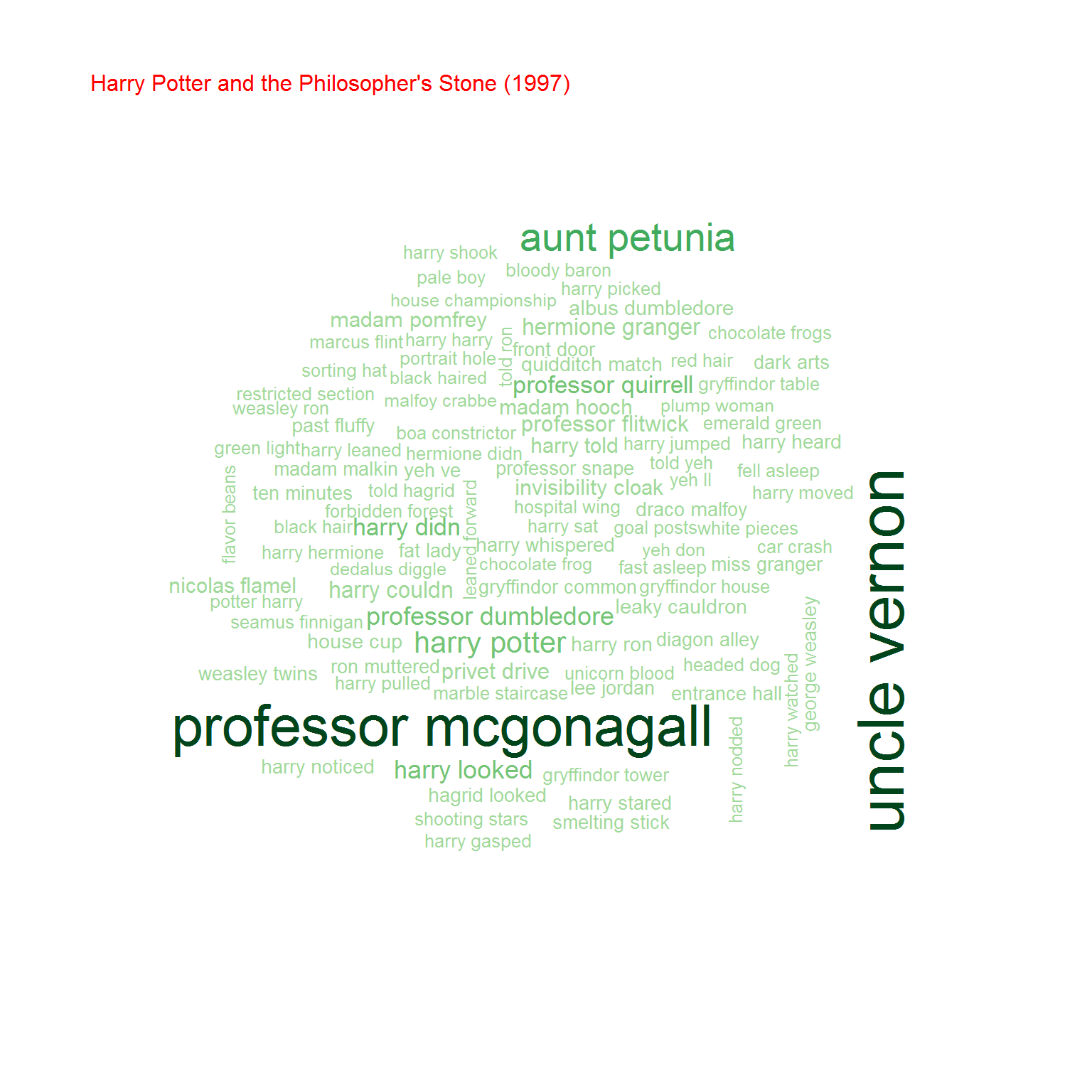
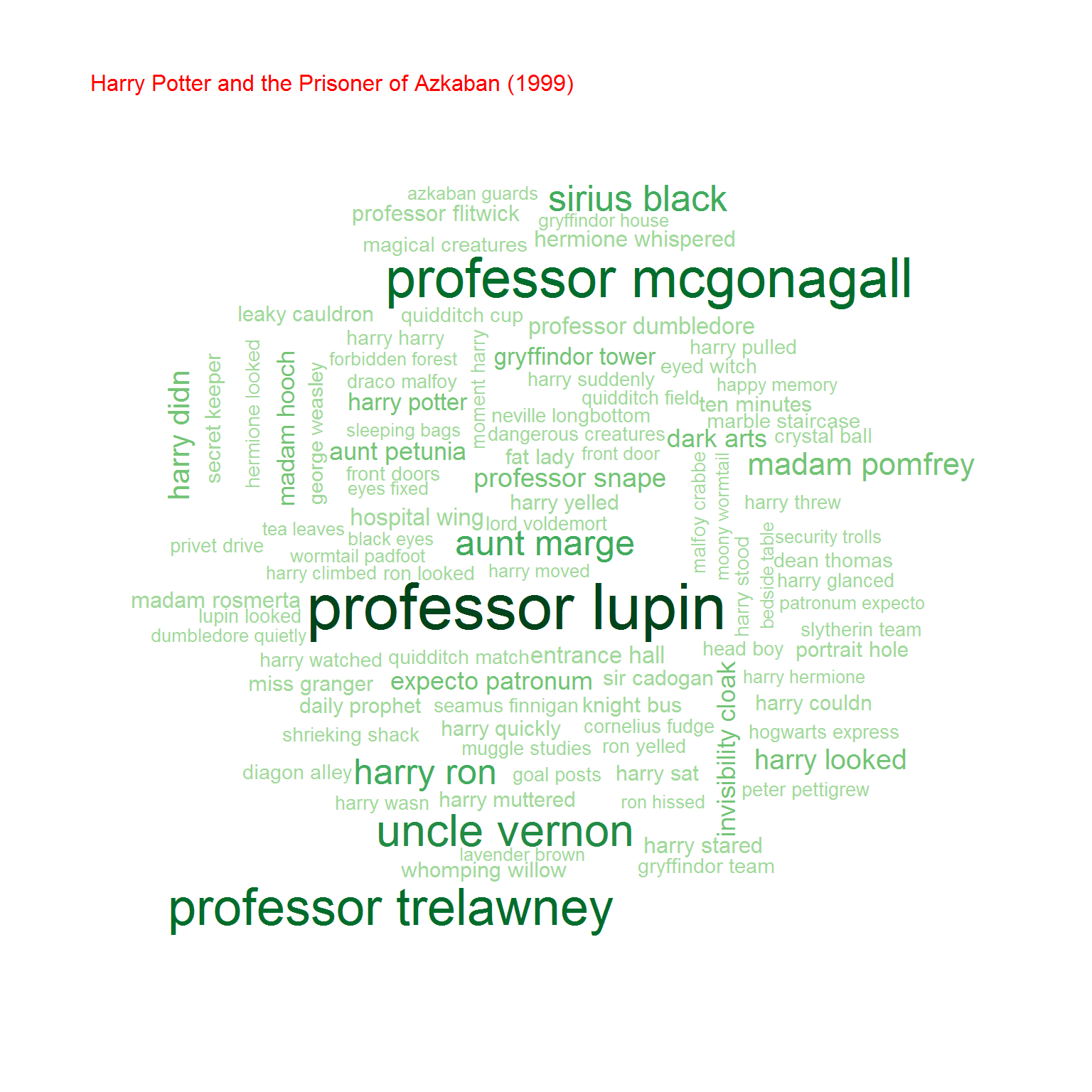
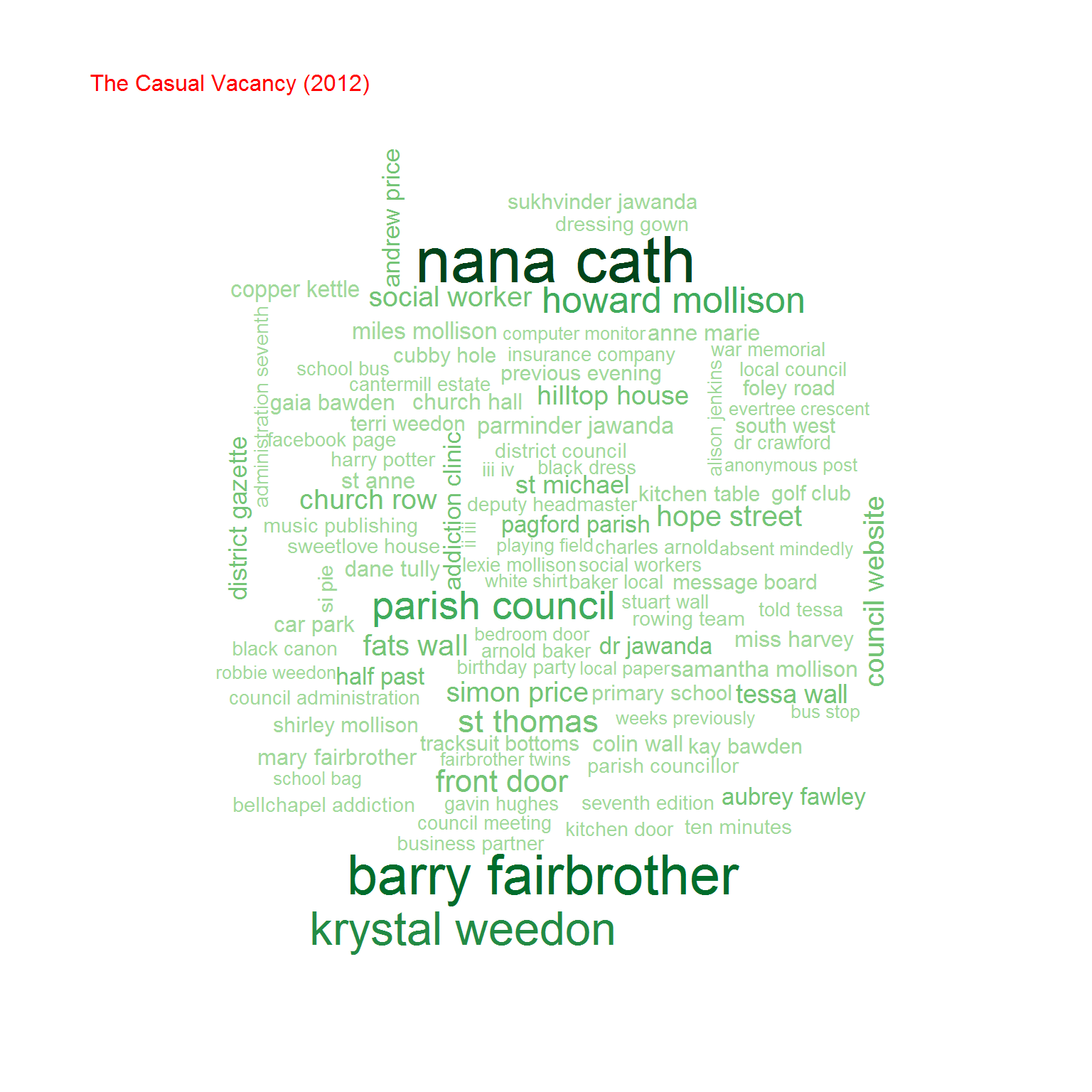
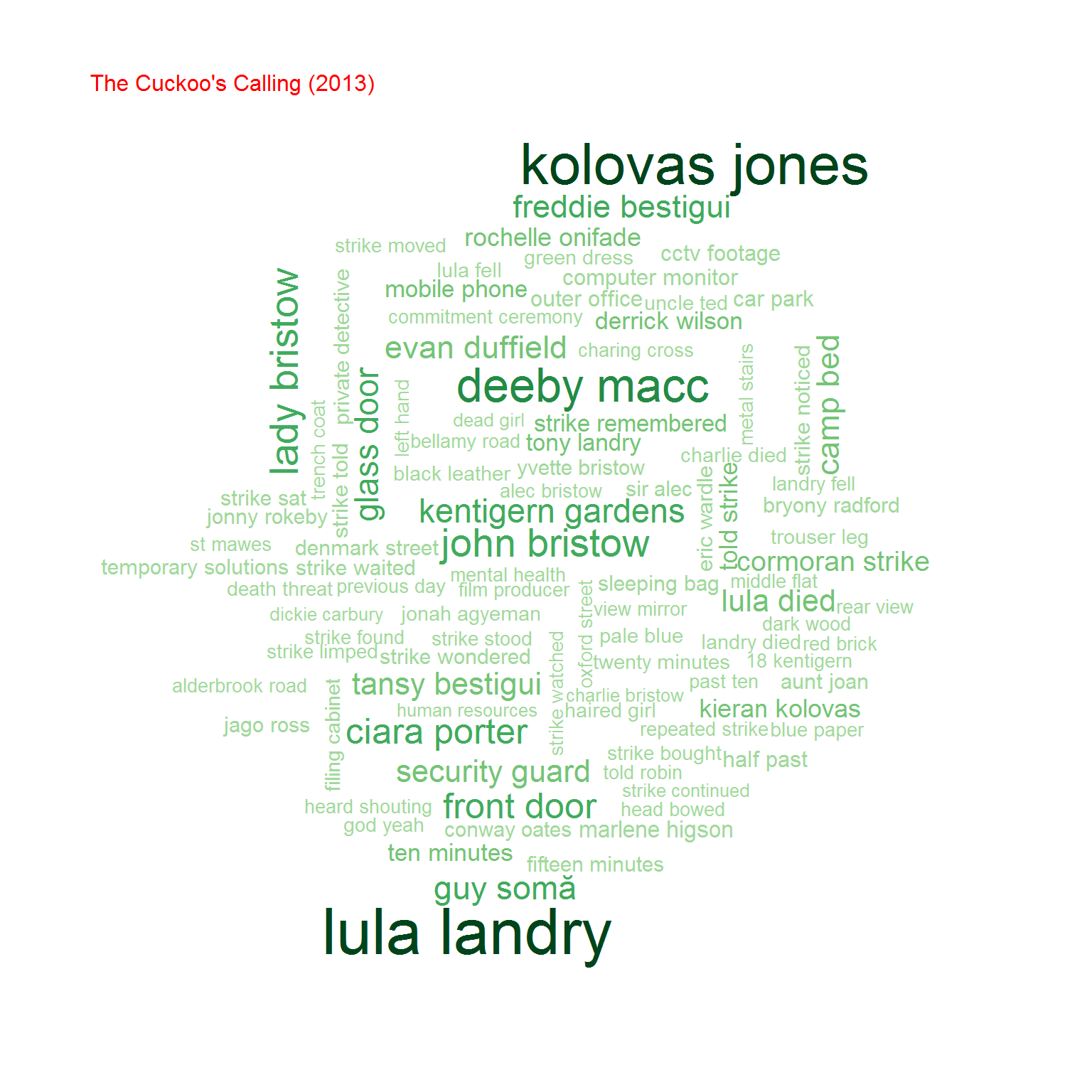
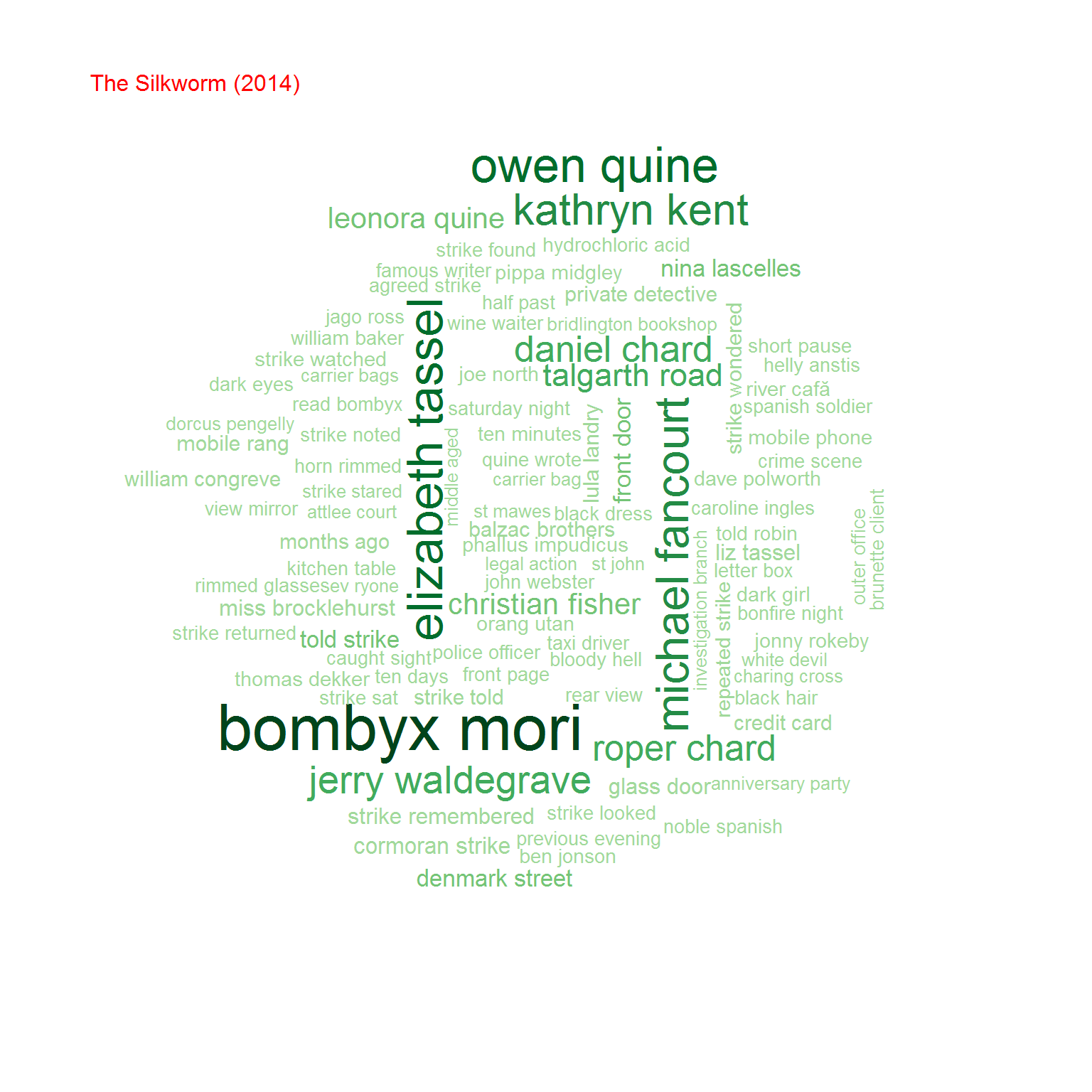
Możemy też policzyć współczynnik korelacji (zupełnie tak samo jak poprzednio) pomiędzy częstościami wystąpień bigramów w obu grupach książek. Oczywiście biorąc pod uwagę cześć wspólną zbiorów bigramów.
Ten współczynnik to 0.27 czyli zdecydowanie mniej niż poprzednie okolice 0.7 (0.76 dla wspólnych słów z 10% najpopularniejszych w ramach grupy czy też jakieś 0.62 wynikające z macierzy korelacji (wszystkie słowa w ramach wszystkich książek). Ciągle jest to jednak korelacja dodatnia. Osobiście uważam, że badanie współautorstwa tekstów najlepiej robić właśnie na bigramach – pojedyncze słowa nie powiedzą wiele o stylu. Ale zapewne badacze literatury mają jakieś sposoby, pewnie o wiele bardziej skomplikowane.
Dla porządku zobaczmy jeszcze listę 10 najpopularniejszych bigramów występujących tak samo często w książkach z Harrym Potterem jaki bez niego:
|
1 2 3 4 |
## "harry potter" "entrance hall" "front door" ## "glass door" "prime minister" "marble staircase" ## "stone steps" "previous evening" "half past" ## "black eyes" |
Na zakończenie coś czego być może nie domyśliliście się czytając powyższy tekst. Nie czytałem ani jednej książki J.K.Rowling, ani też nie widziałem żadnego filmu o Harrym Potterze. Skąd wiedziałem o popularnych miejscach, imionach i zaklęciach? Analizowałem, ale też posiłkowałem się tekstem A textual analysis of Harry Potter by an amateur data analyst. Źródło inspiracji do wpisu było inne, ale przecież ktoś musiał to już wcześniej robić, skoro ta potteromania taka wielka…
Dla zainteresowanych – kod na GitHubie.
Tak sobie myślę, że ta analiza była by jeszcze ciekawsza, gdyby usunąć z niej imiona postaci oraz miejsca charakterystyczne dla tych ksiażek. Wtedy szuka się po rzeczywistym stylu wypowiadania się autorki i nie bierze się cech charakterystycznych wyłącznie dla wybranej serii.
Tak jak napisałem w tekście – nie czytałem książek Rowling. W związku z tym trudno by mi było wyjąć słowa charakterystyczne już na początku. Te słowa pojawiły się co prawda (i same odsłoniły) podczas analizy, więc można z tego skorzystać.
Fajnie, że moi Czytelnicy wpadają na takie pomysły – temu to wszytko ma służyć. Ja daję Wam wędkę, a Wy sami kombinujcie ryby :)