Czy popularność rowerów Veturilo w Warszawie od czegoś zależy?
Dzisiaj, po majowej przerwie (spędzonej między innymi na rowerze) zajmiemy się nieco większymi zbiorami danych.
Na początek kilka słów o przygotowaniu danych.
Rowery Veturilo
Od początku marca (od bodaj 11) zbierałem dane wystawione przez NextBike (operatora rowerów m.in. Veturilo) dla kilkudziesięciu miast. Ograniczyłem się tylko do Warszawy, dane były pobierane co 5 minut. Jak wyglądają te dane możecie sprawdzić sami – to dostępny online plik XML. W pliku znaleźć można wszystkie potrzebne nam informacje:
- ID i numer stacji rowerowej
- współrzędne (długość i szerokość geograficzna) stacji oraz jej nazwę
- liczbę stanowisk na stacji – wszystkich oraz wolnych
- liczbę rowerów dostępnych na stacji
- numery poszczególnych rowerów przypiętych w stacji
- kilka innych, mniej istotnych elementów
W zeszłym roku było maksymalnie pięć numerów przypiętych rowerów, teraz są wszystkie. A przynajmniej na to wygląda. Daje to możliwość prześledzenia trasy jaką przebył rower o konkretnym numerze. Oczywiście nie trasy jaką przejechał, a tylko w których stacacj był “zadokowany”.
Danych jest bardzo dużo, szczególnie jak zbiera się je przez dwa miesiące, co 5 minut, a stacji jest około 300. Mamy więc jakieś 5.18 miliona wierszy.
Jak zbierałem dane? Otóż w najprostrzy (i tego żałuję) sposób – pobierałem przy pomocy skryptu napisanego w PHP XMLa i każde z jego pól wpisywałem do bazy danych, dodatkowo opatrując datą i godziną. Nie przetwarzałem niczego wstępnie, po prostu co pięć minut przepisywałem XMLa do bazy MySQL. Po dwóch miesiącach okazało się to problematyczne (na mojej maszynie).
Trzeba było po pobraniu XMLa przetworzyć go delikatnie: wybrać tylko istotne kolumny, odpowiednio zmienić typy danych, datę rozbić na “atomy” (rok, miesiąc, dzień, godzina i minuty), a pole z numerami rowerów rozbić na kilka(naście) wierszy i to wstawić do oddzielnej bazy. Dzięki temu można oszczędzić późniejszej pracy przy przygotowaniu danych. Dlatego ważna jest wcześniejsza analiza wymagań w projektach i porządna analiza tego, do czego dane będą użyte. I w jaki sposób.
Tak czy inaczej – udało się dane odpowiednio przekształcić. Jednak przy tej ilości trzymanie wszystkiego w pamięci staje się problemem. Dlatego – przy użyciu pakiety dplyr – przetworzone dane zapisałem w bazie SQLite, czyli tak na prawdę lokalnym pliku udającym bazę typy SQL. dplyr pozwala używać w pewnym sensie zdalnie takich danych (mogą to być również dane w MySQL czy kombajnach do rzeczywiście dużych danych typu Spark) dokładnie tak samo jak tych w data.frame trzymanych w pamięci. Dopiero na koniec, kiedy potrzebujemy na przykład narysować dane (przez ggplot2) potrzebujemy je mieć w pamięci – obliczenia, grupowanie itp operacje wykonywane są po stronie serwera, a poprzez wywołanie collect() wynik pobieramy do pamięci. Znakomite rozwiązanie!
Pogoda
Podobnie jak z rowerami zrobiłem z danymi o pogodzie. Różnica jest tylko taka, że tym razem nie pobierałem XMLa, a czytałem zawartość strony z danymi wprost ze stacji meteo Wydziału Fizyki Politechniki Warszawskiej. I robiłem to co pół godziny, a nie co pięć minut (bo dane pogodowe nie są aż tak dynamiczne jak ruch rowerów na stacjach). Te dane zapisałem do bazy MySQL, a następnie zaciągnąłem do R, oczyściłem i zapisałem lokalnie do pliku RDS. Nie ma ich dużo (kilka tysięcy wierszy, siedem kolumn), więc będę używał ich z tabeli w pamięci.
Z tak przygotowanymi danymi można zacząć zabawę
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SQLite_db_file <- "veturilo_2017-05-08.sqlite3" library(dplyr) library(ggplot2) library(lubridate) theme_set(theme_minimal()) # połączenie do bazy danych o rowerach sqllite_db <- src_sqlite(SQLite_db_file) # dane o pogodzie weather <- readRDS("pogoda.RDS") |
Wykorzystanie rowerów – dzień po dniu
Od tego zaczniemy. Zobaczymy czy liczba rowerów Veturilo jeżdżących po Warszawie zależy od pory dnia i od dnia tygodnia?
|
1 2 3 4 5 6 7 8 9 10 11 |
# połączenie do tabeli w bazie danych # dalej traktujemy ją jak zwykłe data.frame veturilo_data <- tbl(sqllite_db, "veturilo") # ile rowerów jest na stacjach w danej chwili? bikes_on_stations <- veturilo_data %>% group_by(year, month, day, hour, minute) %>% summarise(n_bikes = sum(bikes)) %>% ungroup() %>% collect() %>% mutate(time = make_datetime(year, month, day, hour, minute)) |
Mamy liczbę rowerów na stacjach, a potrzebujemy liczbę rowerów w ruchu. Najprościej więc odjąć liczbę rowerów na stacjach od wszystkich rowerów. Tyle, że rowery są naprawiane, wymieniane, dodawane. A w ogóle to nie należy wierzyć firmom w to co piszą na swoich stronach. Ile jest więc rowerów w obiegu?
Zobaczmy jak wygląda rozkład ilości rowerów na stacjach – opisowo i graficznie:
|
1 2 3 4 5 6 7 8 |
summary(bikes_on_stations$n_bikes) ## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 16 3132 3334 3237 3460 6866 mean(bikes_on_stations$n_bikes) + sd(bikes_on_stations$n_bikes) ## [1] 3601.901 hist(bikes_on_stations$n_bikes, breaks = 50) |
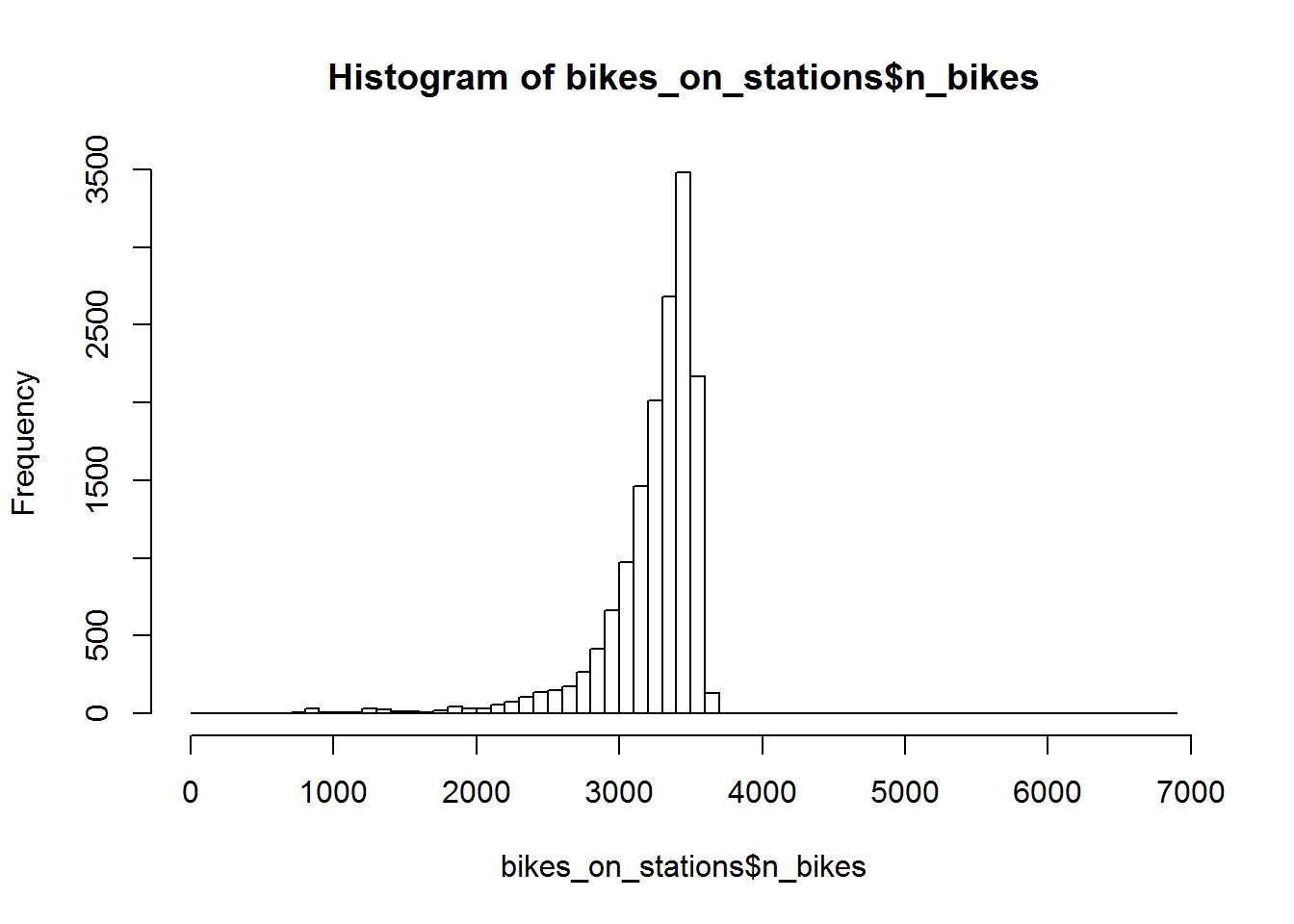
Jak widać średnio jest nieco ponad 3200 rowerów, 75% wszystkich to mniej niż 3460. Maksimum wskazuje jednak liczbę prawie dwukrotnie większą – 6866. Wynikać to może z jakiegoś błędu – na przykład dane zostały pobrane dwa razy w tej samej chwili. Aby wyeliminować takie kwiatki (nie będziemy śledzić kiedy i ile ich jest) usuniemy wszytko co jest większe niż średnia plus jedno odchylenie standardowe (to ta liczba około 3602 wyżej).
|
1 2 3 4 5 |
bikes_on_stations <- bikes_on_stations %>% filter(n_bikes <= mean(n_bikes)+sd(n_bikes)) # ile w sumie dostępnych rowerów? bikes_in_run <- max(bikes_on_stations$n_bikes) |
Uznajemy zatem, że maksymalnie jest 3601 rowerów, z czego informację o tym ile jest na stacjach mamy w danych. Wszystkie rowery minus te przypięte to liczba rowerów wypożyczonych, a ta kształtowała się następująco na przestrzeni ostatnich dwóch miesięcy:
|
1 2 3 4 5 |
bikes_on_stations %>% ggplot() + geom_point(aes(time, bikes_in_run-n_bikes), color="lightgray", size=0.8) + geom_smooth(aes(time, bikes_in_run-n_bikes), se=FALSE, color="darkred") + labs(x="Czas", y="Liczba wypożyczonych rowerów Veturlio") |
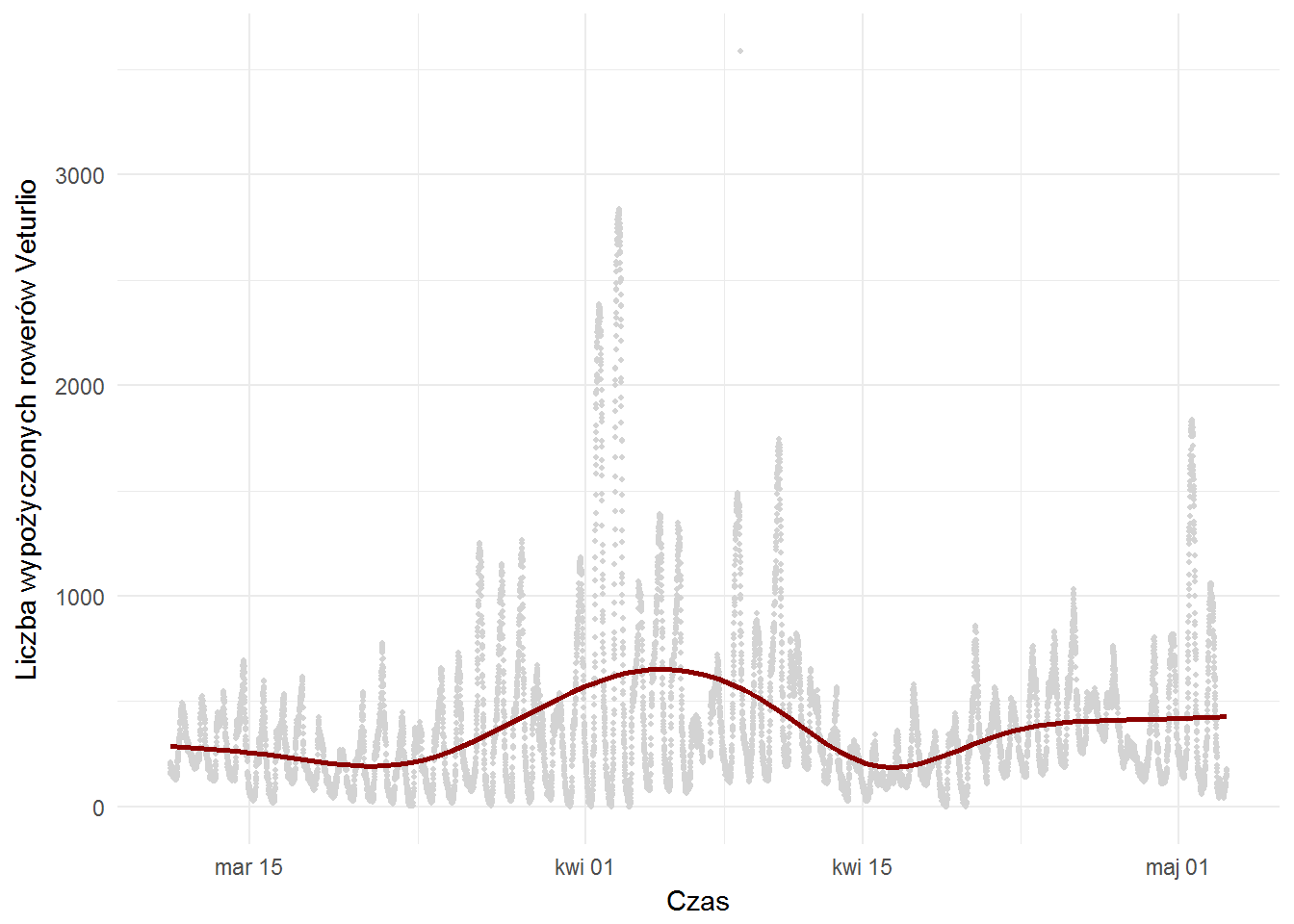
Z początkiem kwietnia zaczęło się sensowne jeżdżenie, zastanawiające są te wysokie piki gdzieś w okolicach 2 kwietnia. Pik w pierwszych dniach maja to ewidentnie “majówka”. Co najbardziej charakterystyczne to falki pokazujące kiedy jest dzień, a kiedy noc.
Wykorzystanie rowerów – godzina po godzinie
No właśnie, zobaczmy w jakich godzinach jeździ najwięcej rowerów? Weźmy uśrednioną (z dwóch miesięcy) wartość dla konkretnej godziny.
|
1 2 3 4 5 6 |
bikes_on_stations %>% group_by(hour) %>% summarise(n_bikes = mean(bikes_in_run-n_bikes)) %>% ggplot() + geom_line(aes(hour, n_bikes)) + labs(x="Godzina", y="Średnia liczba rowerów w ruchu") |
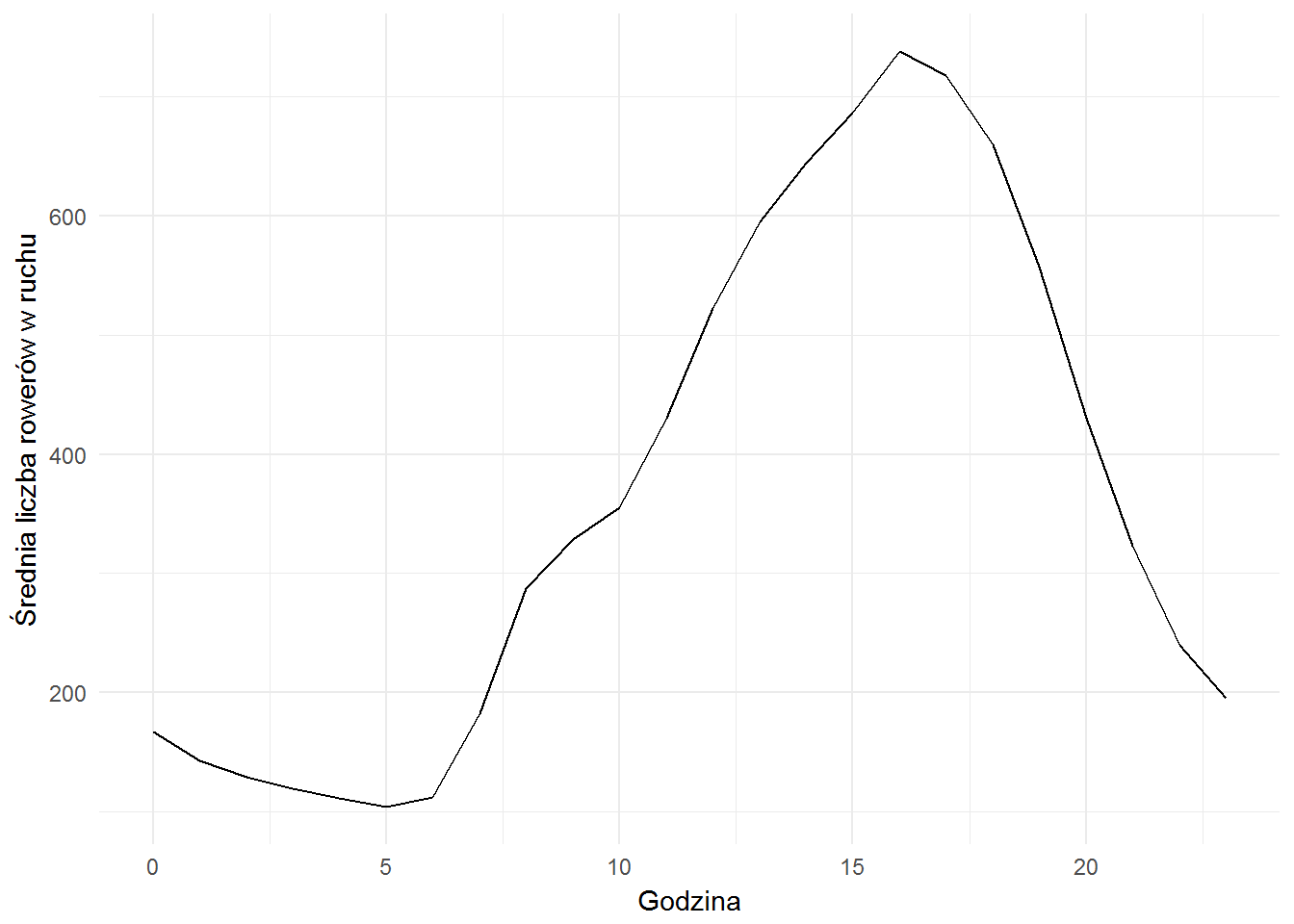
Wnioski dość oczywiste i łatwe do przewidzenia – w nocy rowery śpią, jazda zaczyna się rano (widzicie ten garb przed 10?), a najwięcej cyklistów jest po południu. Ludzie po pracy biorą rower i jadą w miasto (albo do domu).
Właśnie – na pewno po pracy? Dodajmy do naszych danych informacje o dniu tygodnia i przy okazji wskaźnik (tak/nie, prawda/fałsz) o tym czy dzień jest roboczy czy nie:
|
1 2 3 4 5 |
bikes_on_stations$wday <- factor(wday(bikes_on_stations$time), levels = c(2,3,4,5,6,7,1), labels = c("pn", "wt", "sr", "cz", "pt", "sb", "nd")) bikes_on_stations$work_day <- ifelse(bikes_on_stations$wday %in% c("pn", "wt", "sr", "cz", "pt"), TRUE, FALSE) |
Z tymi dniami roboczymi to poprawnie byłoby dodać jeszcze wszelakie święta (Poniedziałek Wielkanocny, 1 i 3 maja). Ale bez tego zobaczmy jak wygląda ten sam rozkład godzinowy, ale z uwzględnieniem rozbicia na dni pracujące i nie:
|
1 2 3 4 5 6 |
bikes_on_stations %>% group_by(work_day, hour) %>% summarise(n_bikes = mean(bikes_in_run-n_bikes)) %>% ggplot() + geom_line(aes(hour, n_bikes, color=work_day)) + labs(x="Godzina", y="Średnia liczba rowerów w ruchu", color="Dzień\nroboczy") |
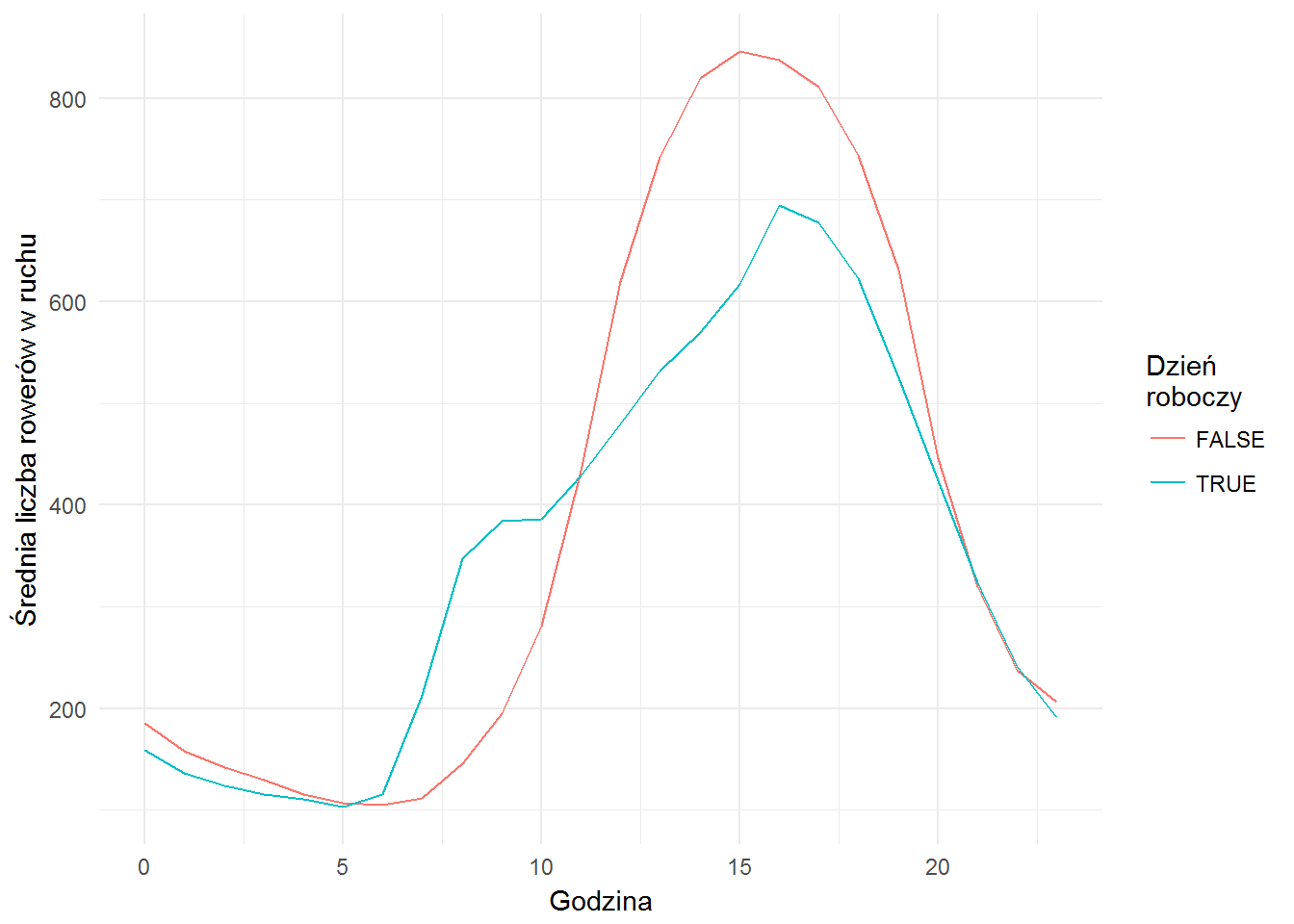
Tutaj garb w okolicy 8-9 rano w dni robocze stał się wyraźniejszy. Ludzie rowerem dojeżdżają do pracy. Później (szczyt w okolicach 16-17) z niej wracają. W weekendy cykliści ruszają w miasto tuż przed południem i kończą około 20. Bo o 20 zapada zmrok. Gdyby mieć dane z całego roku i rozłożyć je po miesiącach widać byłoby, że maksimum weekendowych wycieczek przesuwa się w kierunku godziny zachodu Słońca.
A teraz zrobimy heatmapę – w jaki dzień tygodnia i o jakiej godzinie najtrudniej o rower? Najtrudniej, czyli zamiast liczyć średnią rowerów dostępnych policzymy po prostu liczbę (też średnią) rowerów przypiętych na stacjach. Im bardziej czerwono tym mniej rowerów:
|
1 2 3 4 5 6 7 |
bikes_on_stations %>% group_by(wday, hour) %>% summarise(n_bikes = mean(n_bikes)) %>% ggplot() + geom_tile(aes(wday, hour, fill=n_bikes), color="lightgray") + scale_fill_gradient(high="#dddddd", low="red") + labs(x="Dzień tygodnia", y="Godzina", fill="Liczba rowerów\nna stacjach") |
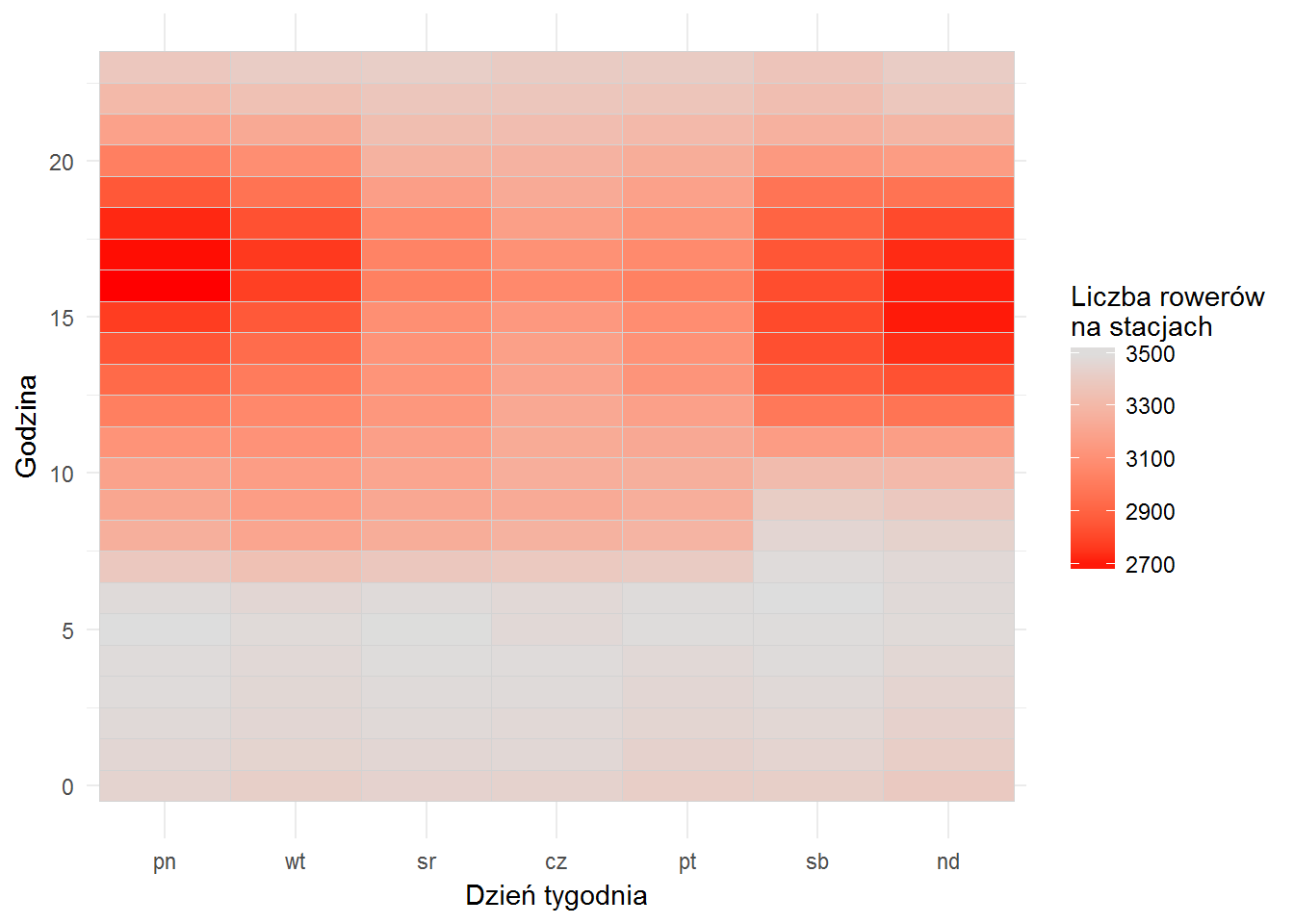
Zgodnie z przypuszczeniami – w nocy nie ma problemu, problem jest w popołudniowym szczycie, szczególnie w niedzielę i poniedziałek, co akurat mnie zdziwiło, podobnie jak środek tygodnia. Być może odpowiedzialna jest za to pogoda. W końcu marzec i kwiecień nie należały do najpiękniejszych w tym roku.
Pogoda
Właśnie – pogoda. Przeanalizujmy ją trochę.
W danych mamy kilka informacji:
- temperaturę powietrza
- temperaturę odczuwalną
- prędkość wiatru, a także jego prędkość w porywach
- wilgotność (nie mamy wprost informacji o opadach)
- ciśnienie atmosferyczne
Zanim zaczniemy operować na samej pogodzie przygotujmy odpowiednio dane. Jak wspomniałem – dane rowerowe są 5-minutowe (pobierane co pięć minut), pogodowe – 30-minutowe. Żeby je móc połączyć potrzebujemy takich samych agregatów – uśrednianie do godziny wystarczy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# uśredniamy liczbę rowerów w ruchu z dokładnością do godziny bikes_weather_hours <- bikes_on_stations %>% group_by(year, month, day, hour) %>% summarise(n_bikes = mean(bikes_in_run-n_bikes)) %>% ungroup() # uśredniamy dane o pogodzie - z dokładnością do godziny weather_hours <- weather %>% mutate(year = year(time), month = month(time), day = day(time), hour = hour(time)) %>% group_by(year, month, day, hour) %>% summarise(temp = mean(temp), temp_odcz = mean(temp_odcz), wiatr = mean(wiatr), porywy = mean(porywy), wilgotnosc = mean(wilgotnosc), cisnienie = mean(cisnienie)) %>% ungroup() |
Teraz połączymy dane i usuniemy to, czego zabrakło:
|
1 2 3 4 5 6 7 8 |
bike_weather <- inner_join(bikes_weather_hours, weather_hours, by=c("year"="year", "month"="month", "day"="day", "hour"="hour")) %>% na.omit() # un-pivot, na potrzeby ggplot library(tidyr) bike_weather_gather <- gather(bike_weather, key=cecha, value=wartosc, n_bikes, temp, temp_odcz, wiatr, porywy, wilgotnosc, cisnienie) |
Sprawdźmy jak wyglądają korelacje pomiędzy liczbą rowerów a poszczególnymi czynnikami pogodowymi:
|
1 2 3 4 |
library(corrgram) corrgram(bike_weather[,c(5,6,7,8,9,10,11)], lower.panel = panel.pts, upper.panel = panel.cor) |
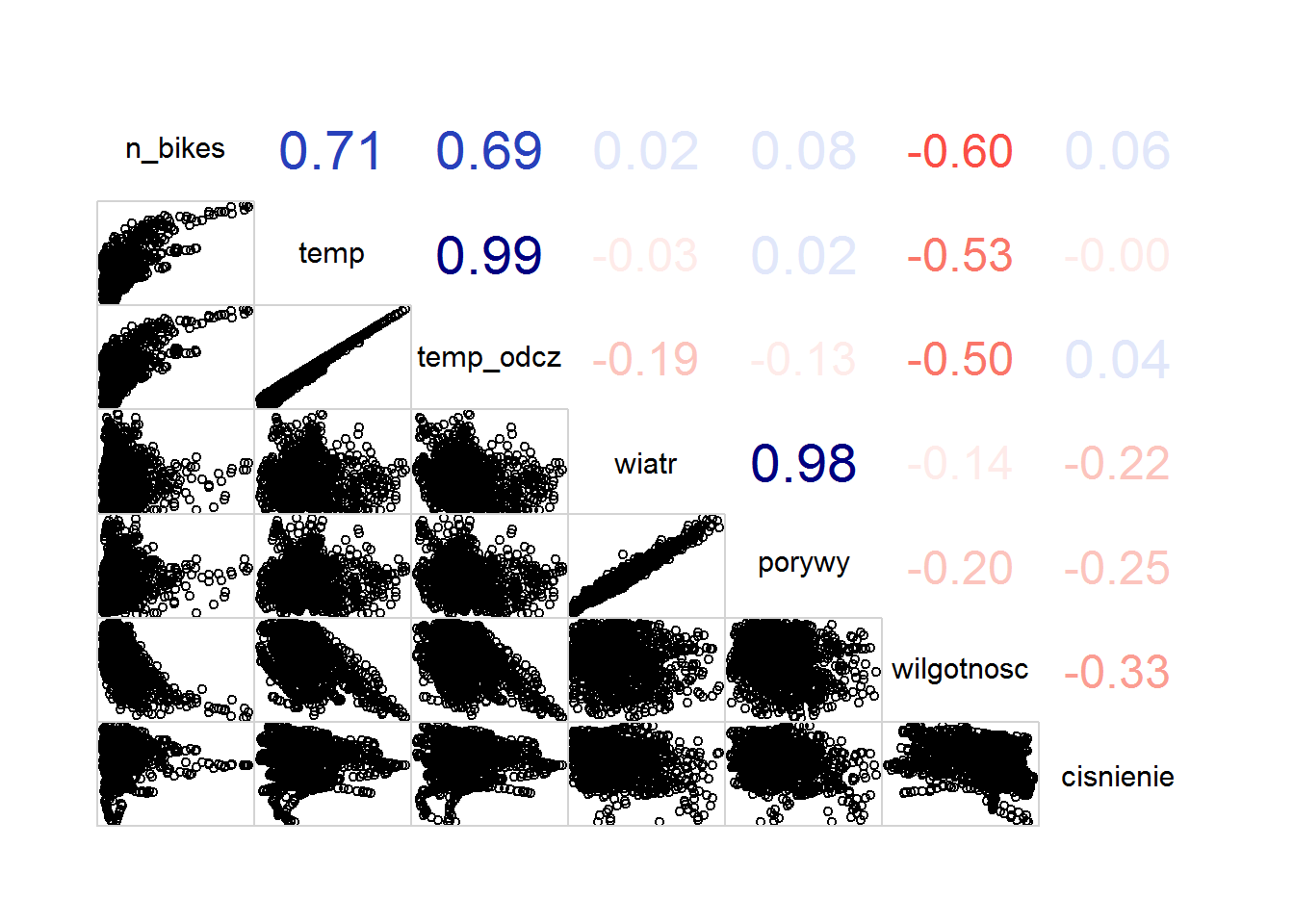
Jak widać bardzo duża jest korelacja (wartości prawie idealnie za sobą podążają) pomiędzy temperaturą i temperaturą odczuwalną, a także pomiędzy prędkością wiatru i jego prędkością w porywach. W dalszej części po prostu wybierzemy samą temperaturę i samą prędkość wiatru.
Ale widać silną korelację dodatnią liczby jeżdżących rowerów z temperaturą i ujemną, też dość silną, korelację z wilgotnością powietrza.
Zobaczmy jak to wszystko wyglądało razem, na przestrzeni kolejnych dni?
|
1 2 3 4 5 6 |
bike_weather_gather %>% filter(!cecha %in% c("temp_odcz", "porywy")) %>% ggplot() + geom_line(aes(make_datetime(year, month, day, hour), wartosc)) + facet_wrap(~cecha, scales="free_y", ncol = 1) + labs(x="Czas") |
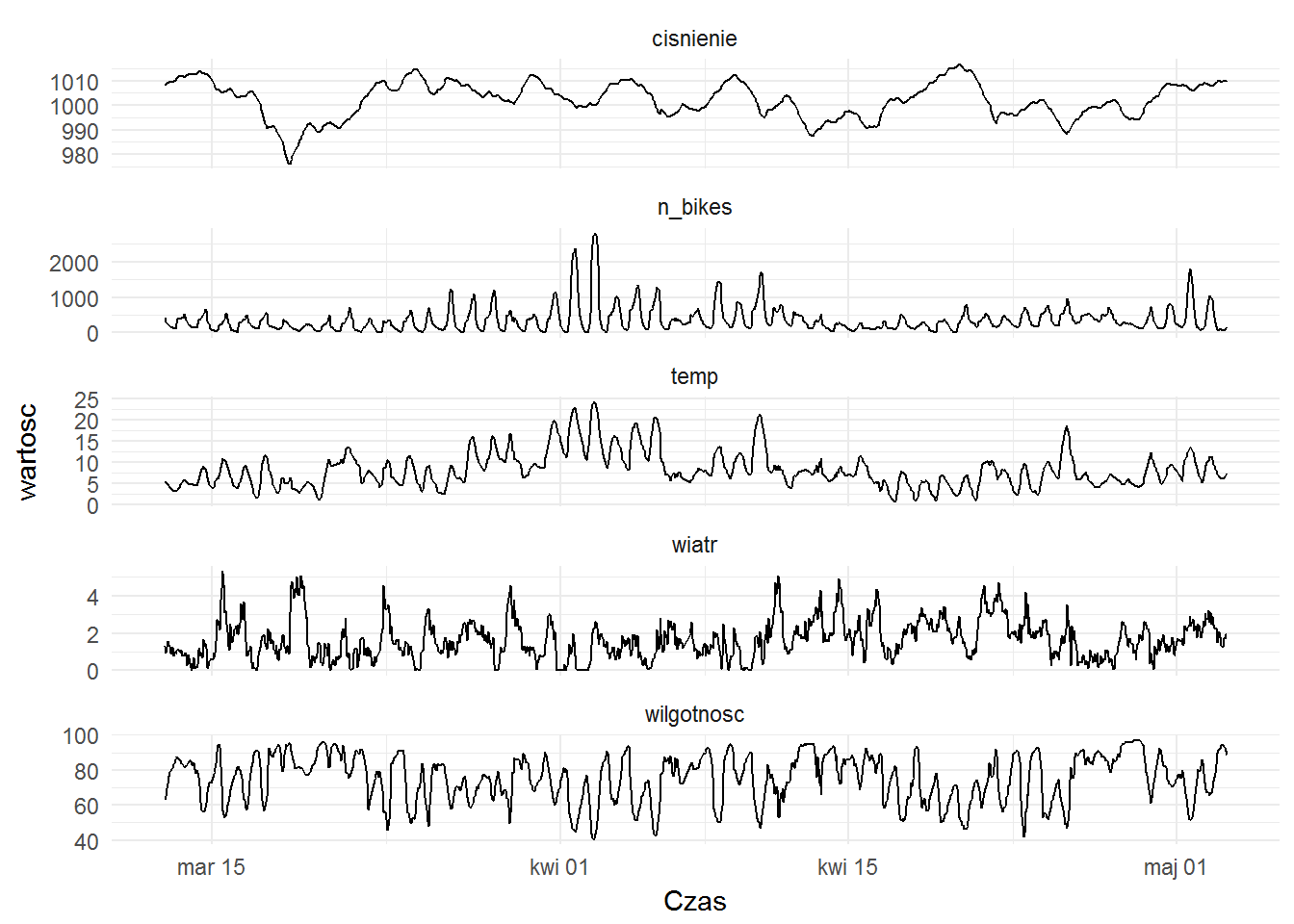
Poza historią nie widzimy niczego czego nie odczytaliśmy z korelacji.
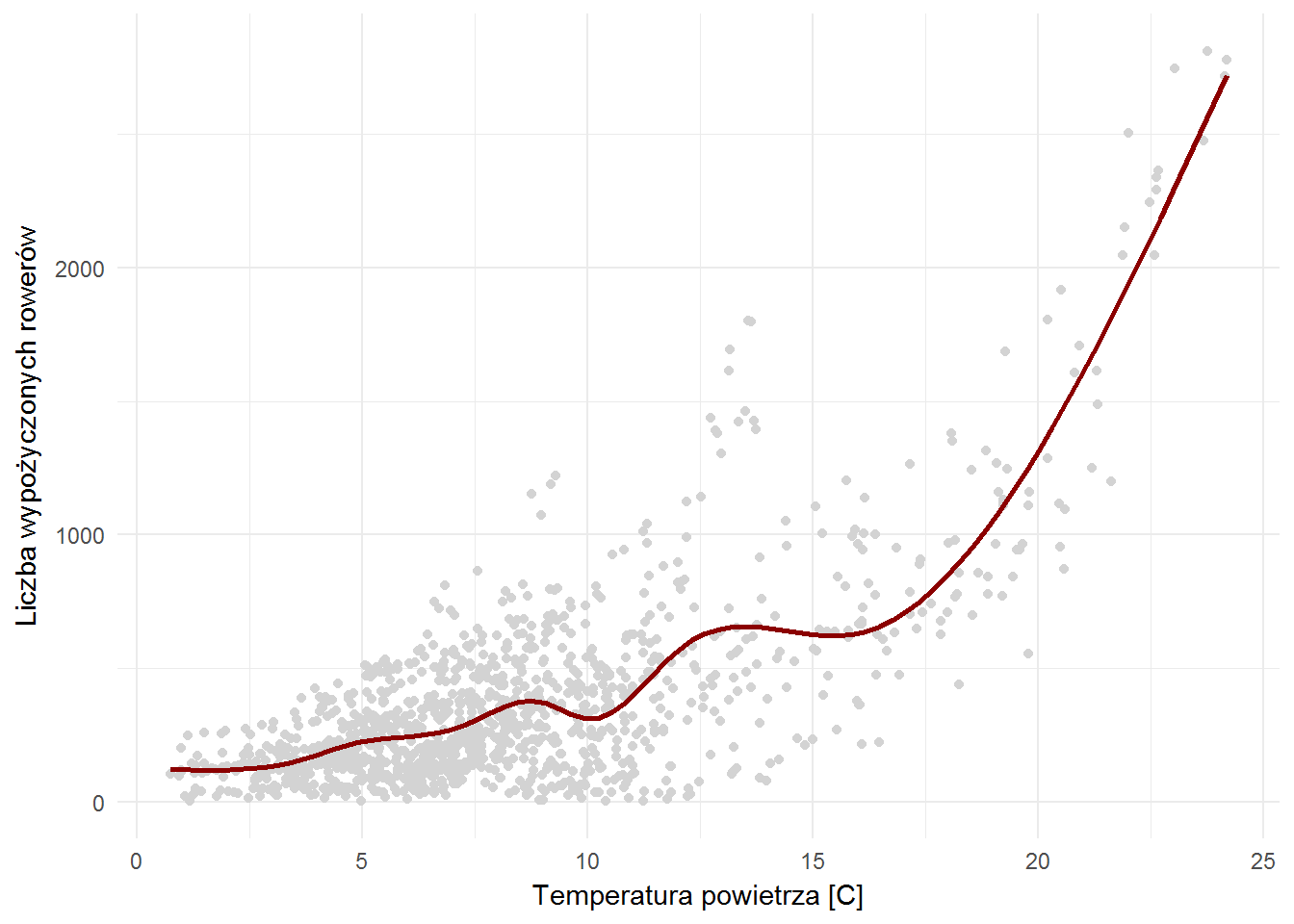
No dobra, to jak dokładnie wygląda zależność liczby rowerów od temperatury? Z korelacji wynika, że im cieplej tym więcej rowerów w trasie:
|
1 2 3 4 |
ggplot(bike_weather) + geom_point(aes(temp, n_bikes), color="lightgray") + geom_smooth(aes(temp, n_bikes), se=FALSE, color="darkred") + labs(x="Temperatura powietrza [C]", y="Liczba wypożyczonych rowerów") |
A zależność od wilgotności? Powinno być tak, że bardziej wilgotno tym mniej chętnych do jazdy:
|
1 2 3 4 |
ggplot(bike_weather) + geom_point(aes(wilgotnosc, n_bikes), color="lightgray") + geom_smooth(aes(wilgotnosc, n_bikes), se=FALSE, color="darkred") + labs(x="Wilgotność powietrza [%]", y="Liczba wypożyczonych rowerów") |
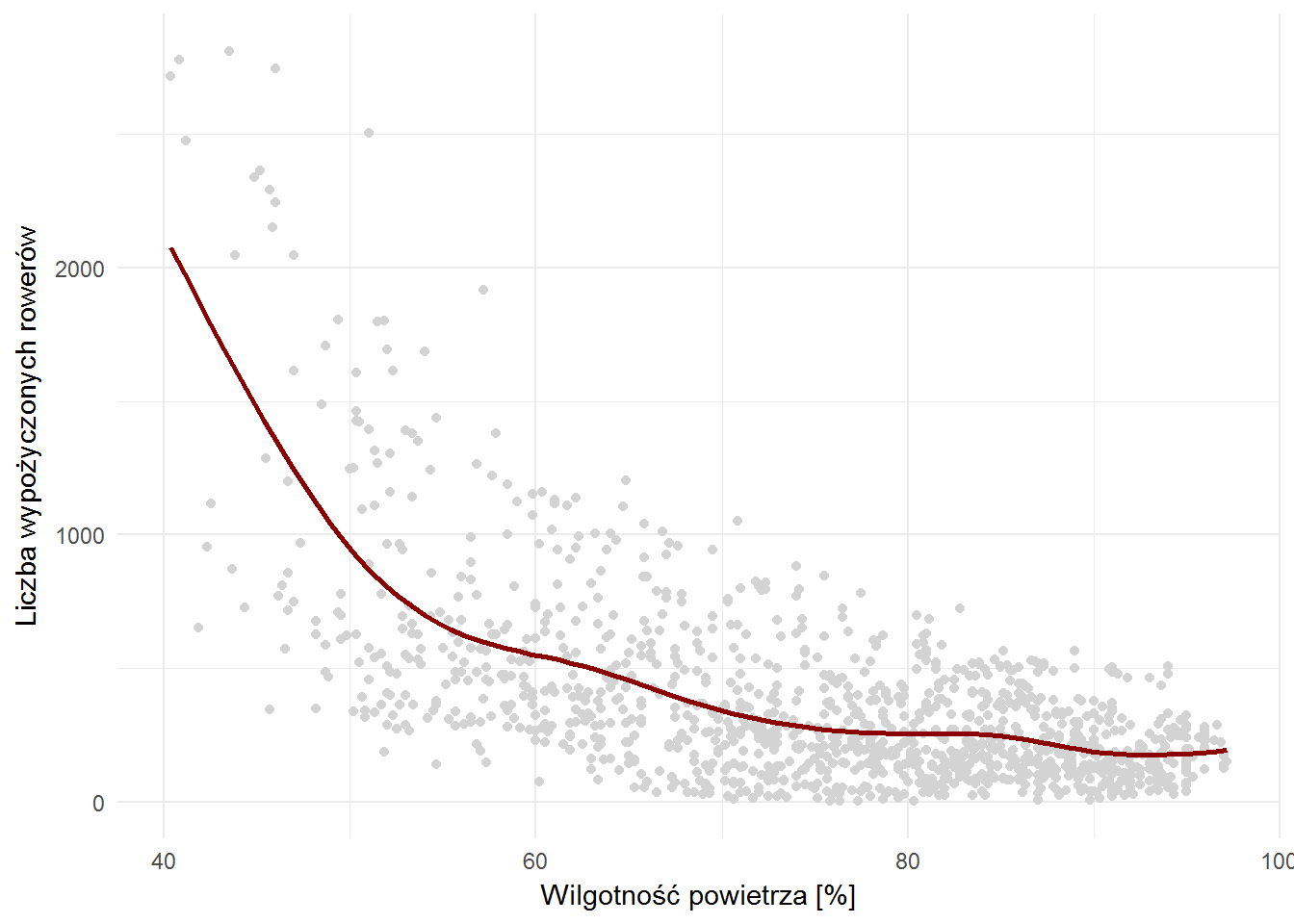
Należy jednak pamiętać o korelacji temperatura-wilgotność (-0.53), która występuje, ale według przyjętych zwyczajów jest raczej korelacją słabą.
Co jeszcze można z tym zrobić? Przede wszystkim można zbudować model predykcyjny, który na podstawie aktualnych warunków atmosferycznych i pory dnia powie nam ile mniej-więcej rowerów jest w ruchu. Taki model to zapewne jedno z kluczowych narzędzi Veturlio – aby zadbać o jakość usług (której bardzo silnym składnikiem jest dostępność rowerów) trzeba przewidywać kiedy (i gdzie!) dostarczyć nowych rowerów.
Przypomnę, że mamy informacje o położeniu (w pewnym sensie) każdego roweru – wiemy czy był przypięty do jakiejś stacji i o której godzinie. Użyjemy tych danych w drugiej części.
Wow, jako początkujący Data Schentist jestem wdzięczna za każdy Pana wpis związany z R … Świetnie się tego czyta oraz można poznać logiczny ciąg podejścia do problemu ! Bardzo dziękuje!
Jedna uwaga: Nie zbierasz danych ze wszystkich stacji rowerowych.
Na terenie Warszawy są dwie 'wirtualne’ sieci Veturilo: zwykła i 'sponsorska’.
Dlatego część wypożyczeń może oznaczać, że rowery zostały przypięte do stacji 'sponsorskiej’
Sieć sponsorska ma uid=372:
http://nextbike.net/maps/nextbike-official.xml?city=372
I jeszcze jedno, zgodnie z twoimi obliczeniami maksymalna liczba rowerów w stojakach wynosiła: 6866.
Wydaje mi się, że to jest jakaś nieścisłość: jeżeli sprawdzisz unikalne ID (numery) rowerów, które przewinęły się przez ten czas przez stojaki, to powinno ich być w okolicach 4000.
Te 6866 wyjaśniłem w tekście – to występuje przy kilku „timestampach” i chyba jest błędem pobrania danych. Dlatego obcinam dane średnią plus odchylenie standardowe, co daje jakieś 3600 rowerów.
A o sieci sponsorskiej nie wiedziałem, teraz już późno na update danych.
2 kwietnia to byl pierwszy goracy dzien po ktorym znowu zimno wrocilo
Z kąd dowiedzieć się jakie ID ma Wrocław?
Pobierz całego xmla, bez parametru. W środku znajdują się wszystkie miasta.
Pingback: Parsowanie XMLa w R | Łukasz Prokulski